本帖最后由 薛定谔了么 于 2025-1-21 14:44 编辑
外点罚函数法
针对包含约束条件的最优化问题,此前介绍的拉格朗日乘子法和KKT条件已经提供一种有效的解决方案。但由于我是从智能优化算法入门运筹优化行业的,所以在遇到这类问题时,更直接的思路其实是:罚函数法。
假设原问题(P)定义如下

在罚函数法中,通常会构造如下的一个新问题(P1)

此处,M为惩罚因子。
设计上式的基本思路是:当gi(x)≤0时,约束已满足,P1目标函数中的后一项为0,P1等价于P;当gi(x)>0时,此时不再满足约束,后一项变为 ,只要M值被设置的足够大,第一项就会显著小于第二项,为了让整体最小化,迭代过程会更倾向于优先减小gi(x)的值,即降低约束不满足的程度,从而先将不可行解快速迭代为可行解,再逐步从可行解过渡至最优解。 ,只要M值被设置的足够大,第一项就会显著小于第二项,为了让整体最小化,迭代过程会更倾向于优先减小gi(x)的值,即降低约束不满足的程度,从而先将不可行解快速迭代为可行解,再逐步从可行解过渡至最优解。
当然,以上过程是通过朴素的认知推演出来的。如果要严谨一点,就需要思考,P的最优解和P1的最优解之间是怎样的关系?对M的值是否有什么要求?
首先,假设P的可行域为S。在可行域范围内,P和P1显然是等价的,且该结论和M的取值无关。
其次,P1中的x事实上并没有约束,所以其范围可以从可行域扩展到整个实数域,因为x的可选范围增加了,所以P1还有机会找到更好的解,所以P≥P1。也就是说,P1为P提供了下界,即P≥P1能够取到的最大值。
然后,在P1中,如果只看M,其系数为正,所以是单调递增的,即如果存在M1<M2,那么必然有

所以,当 时,P1取到最大值。 时,P1取到最大值。
至此,我们可以得到结论:P1为P提供了下界,并且该下界在M趋向于正无穷时取到。
举个简单的例子看一下。

以上问题中,包含2个优化变量,1个约束条件。如果使用罚函数法,则目标函数变为

分开来写

针对每种情形,分别计算梯度

最优性必要条件是:梯度值为0。如果x1+x2-4≤0,那么

此时x1+x2-4=1>0,与假设条件不符合,舍去。
如果x1+x2-4≥0,那么可以得到

时,x1,x2的值可以通过洛必达法则得到

此时,x1+x2-4=0,符合假设条件。
另外,海森矩阵为

因为M>0,所以 为正定阵,即上述解为极小值。 为正定阵,即上述解为极小值。
看起来挺简单的,那是不是针对任意的约束优化问题,都可以通过构造罚函数,然后直接求梯度等于0,并让M趋向无穷大后,得到最优解呢?
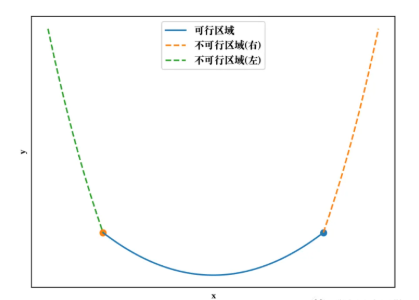
理论上好像可以,但实际上并不可行。主要原因有两点:(1)很多优化问题的梯度计算特别复杂,甚至无法计算,比如使用各种智能优化算法求解的复杂问题;(2)即使可以推导出梯度公式,但是随着M的增加,在边界处的梯度值越来越大,当M已经极大时,可能会出现梯度爆炸的现象,而很多问题的最优解恰恰是在边界处取得,这就会给数值计算带来较大误差,下图中,由于加入了惩罚项,边界处(两个圆点)的左右值显然变化很大。

为了更好地使用使用罚函数法,一般的求解框架是这样设计的:
(1)给定初始点x0,允许的惩罚项误差精度 ,初始M0,以及每次M的增长幅度c(c>1)。 ,初始M0,以及每次M的增长幅度c(c>1)。
(2)以xk-1为初始点,求解无约束优化问题P1,得到最优解xk。
(3)如果 ,则停止迭代,xk作为P的最优解;否则,令Mk+1=cMk,转步骤2。 ,则停止迭代,xk作为P的最优解;否则,令Mk+1=cMk,转步骤2。
这里需要解释一下给定x0的原因。求解P1时主要使用梯度类算法,所以是需要有个初值的,只不过此处初始点的选取是任意的,即可以在可行域外,也可以在可行域内;此外,求解Mk+1对应的P1时,需要使用Mk对应P1的最优解作为初值。
上述这种解决办法,在学术上还有一个更专业的称呼:外点罚函数法。
内点罚函数法
既然有外点罚函数法,那自然就还有内点罚函数法。
内点罚函数法的基本思想是在目标函数上引入一个关于约束的惩罚项,当迭代点由可行域的内部接近可行域的边界时, 惩罚项将趋于无穷大来迫使迭代点返回可行域的内部, 从而保持迭代点的严格可行性。
一种常见的新问题(P2)定义方式为:

此处,R为惩罚因子。
参考上一节的推理方式,我们可以得到如下结论:P2为P提供了上界,并且该上界在趋向于0时取到。
还是以上节的例子为例,目标函数变为

求梯度并令其等于0

上述两式相减,先得到变量间的对应关系

将该对应关系带入第二个梯度公式

 时,x2存在两个可行解:2和3/2。 时,x2存在两个可行解:2和3/2。
回到刚刚的对应关系,可以得到x1=3和x1=5/2。
显然,只有第二组解符合约束条件x1+x2-4≤0。而该解和外点罚函数法的解是完全一致的。
需要说明的是,相比外点罚函数法,内点罚函数法要求可行解始终保持在可行域内,并且不能直接处理含等式约束的最优化问题。受限于这些条件,内点罚函数法在实际问题中的通用性不如外点罚函数法。
罚函数法 vs 拉格朗日乘子法
既然罚函数法和拉格朗日乘子法都是解决约束优化问题的方法,那么就有必要放在一起横向对比一下。
浏览了一些网上关于这两种方法的对比,很多是从对偶角度入手的,不过暂时我还不太懂对偶,所以打算从算法设计的思路来阐述。
罚函数法的思路,有种逐步逼近最优解的状态:持续增加惩罚因子值后,新构造的无约束优化问题的最优解便会越来越逼近原约束优化问题的上界(内惩罚)或下界(外惩罚);在此过程中,惩罚因子是以参数形式被引入的,所以原问题未扩维。
拉格朗日乘子法的思路,则更像是一步到位的策略:直接证明了新构造的无约束优化问题的最优解等价于原约束优化问题的最优解;在此过程中,拉格朗日乘子则是以优化变量的身份被引入的,所以原问题相当于被升维到更高空间去解决。
本文转载自微信公众号:我在开水团做运筹 | 





















