本帖最后由 graphite 于 2025-8-13 18:02 编辑
本文围绕生物医学 AI 中的变分自编码器(VAE)展开,分为上下两部分。本篇分为下半部分,将聚焦第3章内容(全文目录如下文所示),深入解读变分自编码器(VAE)的核心概念与原理。这一章从降维和自编码器的基础概念入手,回顾主成分分析(PCA)与自编码器的关联,进而剖析普通自编码器在内容生成方面的局限性。在此基础上,引出变分自编码器的定义,阐述其通过对编码分布进行正则化以优化潜在空间结构的机制,并结合概率框架与变分推断技术,详细推导 VAE 损失函数的构成,同时探讨神经网络在模型中的应用,帮助读者全面理解 VAE 从直觉到数学层面的完整逻辑。

本文为《 Auto-encoding variational bayes 》的下篇内容,上篇链接:生物医学 AI 中的变分自编码器(VAE):原理、算法与应用解析(上)。《 Auto-encoding variational bayes 》一文聚焦生物医学 AI 中的变分自编码器(VAE),先阐述其方法基础,涉及有向图模型下界估计、问题场景(难解性与大数据集挑战)、变分边界、SGVB 估计器、AEVB 算法及重参数化技巧,还以具体示例说明 VAE 结构,对比相关工作,介绍实验及结论与未来方向,展现 VAE 在处理连续潜变量等方面的技术细节与应用潜力。
全文目录
1. 论文说明
2. 论文速读
3. 变分自编码器(VAE)的理解
3. 变分自编码器(VAE)的理解
Understanding Variational Autoencoders (VAEs):
https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
Intuitively Understanding Variational Autoencoders:
https://towardsdatascience.com/intuitively-understanding-variational-autoencoders1bfe67eb5daf
本博客以上述第一篇博客为主。该博客由Joseph Rocca和Baptiste Rocca编写。
3.1 引言(Introduction)
在过去的几年里,基于深度学习的生成模型由于该领域的一些惊人的改进而获得了越来越多的兴趣。依靠大量的数据、精心设计的网络架构和智能训练技术,深度生成模型已经显示出一种令人难以置信的能力,可以生成各种类型的高度逼真的内容,如图像、文本和声音。在这些深度生成模型中,有两个主要的家族值得特别关注:生成对抗网络(Generative Adversarial Networks, GANs)和变分自编码器(Variational Autoencoders, VAEs)。

在今年1月发表的上一篇文章中,我们深入讨论了生成对抗网络(Generative Adversarial Networks, GANs),并特别展示了对抗训练如何对抗两个网络,一个生成器和一个鉴别器(a generator and a discriminator),以推动它们迭代改进。在这篇文章中,我们现在介绍另一种主要的深度生成模型:变分自编码器(Variational Autoencoders, VAEs)。简而言之,变分自编码器(VAE)是一种自编码器,在训练过程中对其编码分布进行正则化(regularised),以确保其潜在空间具有良好的性质,从而使我们能够生成一些新的数据。此外,“变分(variational)”一词来自于统计学中正则化与变分推断方法(regularisation and the variational inference method)之间的密切关系。
如果最后两句话很好地总结了变分自编码器(VAE)的概念,它们也会提出很多问题。什么是自动编码器(autoencoder)?什么是潜在空间,为什么要规范它?如何从变分自编码器(VAE)生成新数据?变分自编码器(VAE)和变分推断(variational inference)之间的联系是什么?为了尽可能好地描述变分自编码器(VAE),我们将尝试回答所有这些问题(以及许多其他问题!),并为读者提供尽可能多的见解(从基本的直觉到更高级的数学细节)。因此,这篇文章的目的不仅是讨论变分自编码器所依赖的基本概念,而且是一步一步地建立,从最开始的推理,导致这些概念。
话不多说,让我们一起(重新)发现变分自编码器(VAE)吧!
3.2 博文大纲(Outline)
在第一部分中,我们将回顾一些关于降维和自动编码器的重要概念,这些概念将有助于理解变分自编码器(VAE)。然后,在第二节中,我们将展示为什么自动编码器不能用于生成新数据,并将介绍变分自动编码器,它是自动编码器的正则化版本,使生成过程成为可能。最后,在最后一节中,我们将基于变分推断给出变分自编码器(VAE)s的更数学的表示。
请注意:在最后一节中,我们试图使数学推导尽可能完整和清晰,以弥合直觉和方程之间的差距。但是,不想深入研究变分自编码器(VAE)的数学细节的读者可以跳过本节,而不会影响对主要概念的理解。还请注意,在这篇文章中,我们将滥用以下符号:对于随机变量( z ),我们将( p(z) )表示该随机变量的分布(或密度,取决于上下文)。
3.3 降维,PCA和自编码器
在第一部分中,我们将首先讨论与降维有关的一些概念。特别是,我们将简要回顾主成分分析(principal component analysis, PCA)和自动编码器(autoencoders),展示这两个想法是如何相互关联的。
3.3.1 什么是降维?
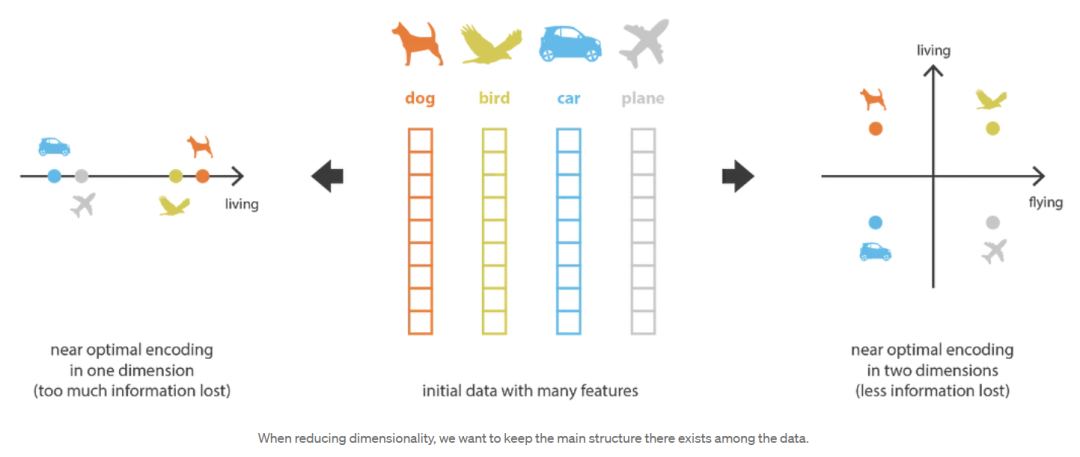
在机器学习中,降维(dimensionality reduction)是减少描述某些数据的特征数量的过程。这种减少可以通过选择(只保留一些现有特征)或提取(在旧特征的基础上创建减少数量的新特征)来完成,并且在许多需要低维数据的情况下(数据可视化、数据存储、繁重的计算……)非常有用。尽管存在许多不同的降维方法,但我们可以设置一个与这些方法中的大多数(如果不是全部!)匹配的全局框架。
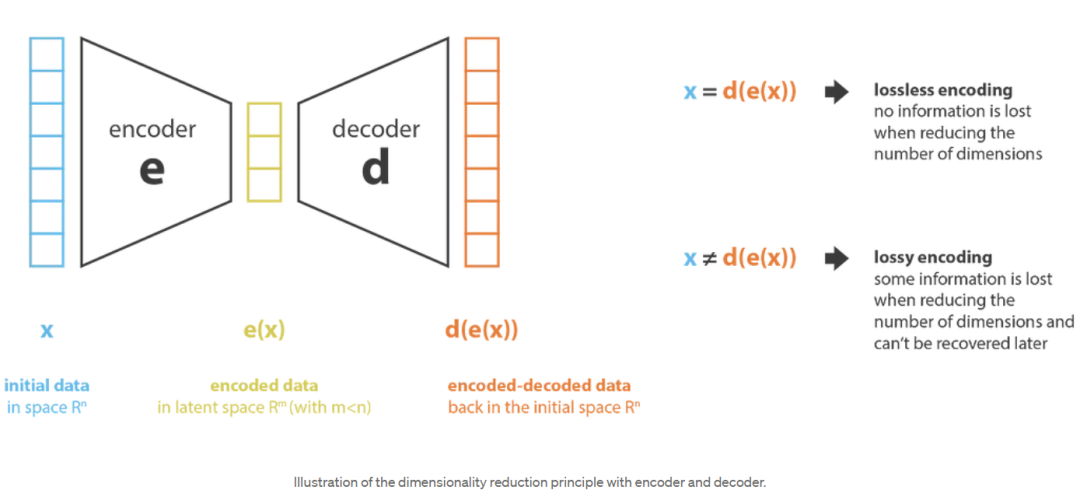
首先,我们将编码器(encoder)称为从“旧特征”表示(通过选择或提取)产生“新特征”表示的过程,而将解码器(decoder)称为相反的过程。降维可以解释为数据压缩,其中编码器压缩数据(从初始空间压缩到编码空间,也称为潜在空间latent space),而解码器解压它们。当然,根据初始数据分布、潜在空间维度和编码器定义的不同,这种压缩可能是有损的,这意味着在编码过程中丢失了一部分信息,在解码时无法恢复。
[降维示意图](image-20231016195551050)
降维方法的主要目的是在给定族中找到最佳编码器/解码器对。换句话说,对于给定的一组可能的编码器和解码器,我们要寻找在编码(encoding)时保留最大信息并且在解码(decoding)时具有最小的重构错误的对。如果我们分别表示我们正在考虑的编码器和解码器族( E )和( D ),那么降维问题可以写成:
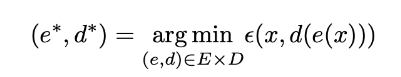
其中:
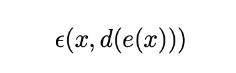
定义了输入数据( x )和编解码数据( d(e(x)) )之间的重构误差度量。最后注意,在下面的代码中,我们将( N )表示数据的数量,( n_d )表示初始(解码)空间的维数,( n_e )表示约简(编码)空间的维数。
3.3.2 主成分分析(PCA)
当谈到降维时,首先想到的方法之一是主成分分析(Principal components analysis, PCA)。为了展示它是如何符合我们刚刚描述的框架,并与自动编码器建立链接,让我们对主成分分析(PCA)的工作原理进行一个非常高的概述,把大多数细节放在一边(注意,我们计划写一篇关于这个主题的完整文章)。
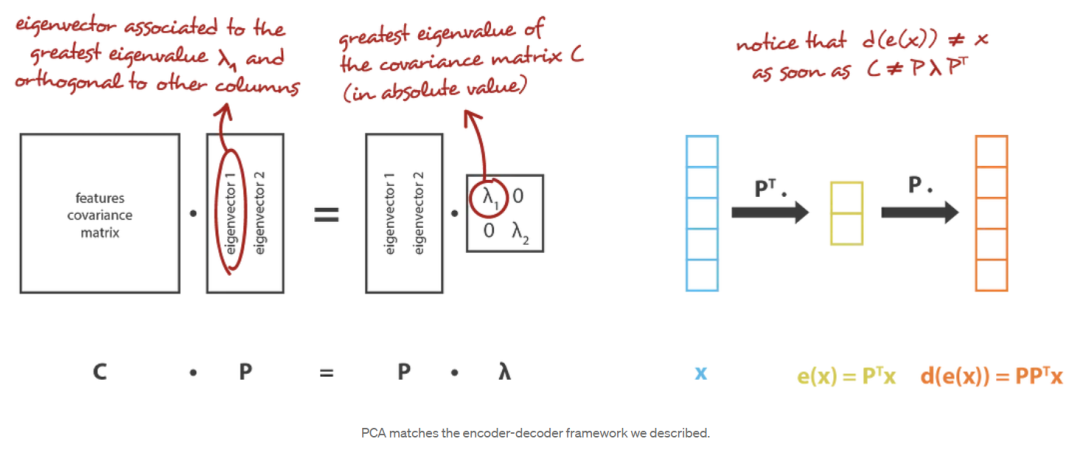
主成分分析(PCA)的思想是建立( n_e )个新的独立特征,这些特征是( n_d )个旧特征的线性组合,从而使这些新特征定义的子空间上的数据投影尽可能接近初始数据(就欧几里得距离而言)。换句话说,主成分分析(PCA)正在寻找初始空间(由新特征的正交基描述)的最佳线性子空间,以便通过它们在该子空间上的投影近似数据的误差尽可能小。
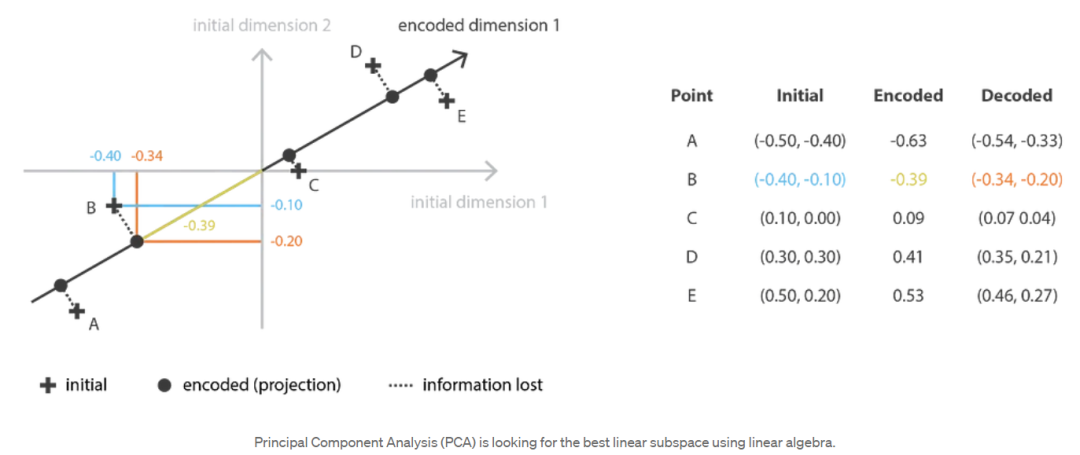
在我们的全局框架中,我们正在寻找行正交(特征无关)的( n_e ×n_d )矩阵(线性变换)的( E )族中的编码器,以及( n_d ×n_e )矩阵的( D )族中的相关解码器。可以证明,协方差特征矩阵的( ne )个最大特征值(范数)对应的酉特征向量是正交的(或可以选择正交的),并定义了( ne )维的最佳子空间,以最小的近似误差投影数据。因此,可以选择这些( ne )特征向量作为我们的新特征,因此,降维问题可以表示为特征值/特征向量问题。此外,还可以证明,在这种情况下,解码器矩阵是编码器矩阵的转置。
3.3.3 自编码器(Autoencoders)
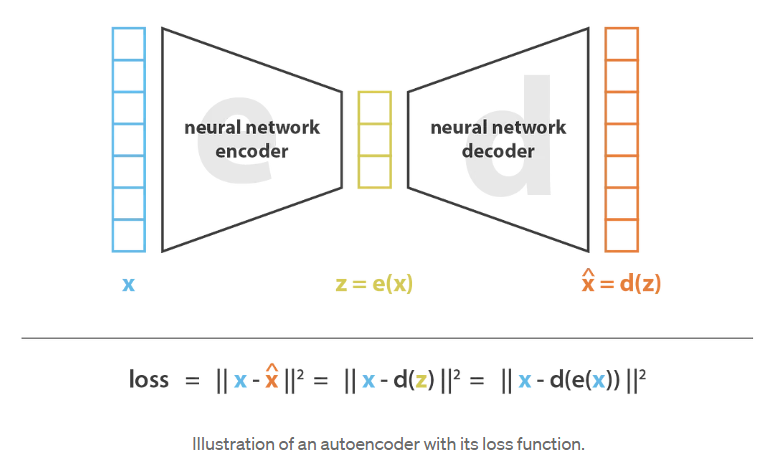
现在让我们讨论一下自动编码器(autoencoders),看看如何使用神经网络进行降维。自动编码器的一般思想非常简单,它包括将编码器和解码器设置为神经网络,并使用迭代优化过程学习最佳编解码方案。因此,在每次迭代中,我们向自编码器体系结构(编码器之后是解码器)提供一些数据,我们将编码-解码输出与初始数据进行比较,并通过体系结构反向传播误差以更新网络的权重。
因此,直观地说,整个自动编码器架构(autoencoder architecture, 编码器+解码器)为数据创造了一个瓶颈,它确保只有信息的主要结构化部分可以通过并被重构。看看我们的总体框架,( E )族编码器是由编码器网络架构定义的,( D )族解码器是由解码器网络架构定义的,编码器和解码器的搜索是通过这些网络的参数梯度下降来最小化重构误差的。
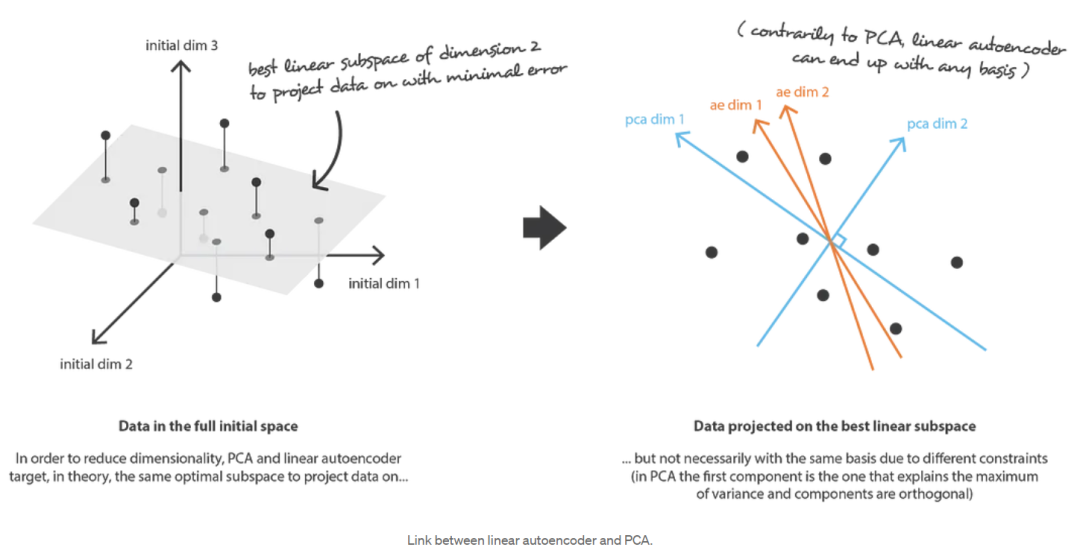
让我们首先假设我们的编码器和解码器架构都只有一层,没有非线性(线性自编码器)。这样的编码器和解码器是简单的线性变换,可以表示为矩阵。在这种情况下,我们可以看到与主成分分析(PCA)的明确联系,就像主成分分析(PCA)一样,我们正在寻找最好的线性子空间来投影数据,在这样做时尽可能少的信息损失。用主成分分析(PCA)获得的编码和解码矩阵自然定义了我们将满意地通过梯度下降达到的解决方案之一,但我们应该指出,这不是唯一的解决方案。实际上,可以选择几个基来描述相同的最优子空间(several basis can be chosen to describe the same optimal subspace),因此,几个编码器/解码器对可以给出最优重构误差(the optimal reconstruction error)。此外,对于线性自编码器,与主成分分析(PCA)相反,我们最终得到的新特征不必是独立的(神经网络中没有正交性约束)。
现在,让我们假设编码器和解码器都是深度和非线性的。在这种情况下,结构越复杂,自编码器就越能在保持低重构损失的同时进行高维降维。直观地说,如果我们的编码器和解码器有足够的自由度,我们可以将任何初始维度降为1。实际上,具有“无限性能(infinite power)”的编码器理论上可以将我们的( N )个初始数据点编码为1,2,3,…直到( N )(或者更一般地,作为实轴上的( N )个整数),而相关的解码器可以进行反向转换,在此过程中没有任何损失。
在这里,我们应该记住两件事。首先,在没有重建损失的情况下进行重要的降维通常要付出代价:在潜在空间中缺乏可解释和可利用的结构(缺乏规律性,lack of regularity)。其次,大多数情况下,降维的最终目的不仅仅是减少数据的维数,而是在减少维数的同时,在减少的表示中保留了数据结构信息的主要部分。由于这两个原因,隐空间的维度和自编码器的“深度”(定义压缩的程度和质量)必须根据降维的最终目的仔细控制和调整。
3.4 变分自编码器(Variational Autoencoders)
到目前为止,我们已经讨论了降维问题,并引入了可以通过梯度下降训练的编码器-解码器架构(encoder-decoder architectures)。现在让我们与内容生成问题建立联系,看看当前形式的自动编码器对该问题的限制,并介绍变分自动编码器。
3.4.1 自动编码器对内容生成的限制
在这一点上,一个自然出现在脑海中的问题是“自动编码器和内容生成之间的联系是什么?”。事实上,一旦自动编码器被训练,我们就有了编码器和解码器,但仍然没有真正的方法来产生任何新内容。乍一看,我们可能会想,如果潜在空间足够规则(编码器在训练过程中很好地“组织”了),我们可以从潜在空间中随机取一个点并对其进行解码以获得新的内容。然后,解码器将或多或少地充当生成对抗网络(Generative Adversarial Network, GAN)的生成器。
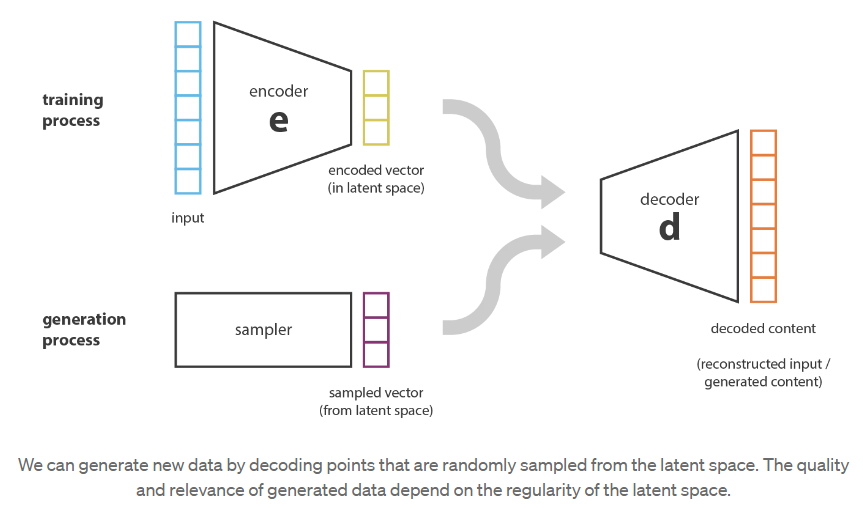
然而,正如我们在前一节中讨论的那样,自动编码器的潜在空间的规律性是一个难点,它取决于数据在初始空间中的分布、潜在空间的维度和编码器的体系结构。因此,我们很难(如果不是不可能的话)先验地确保编码器将以一种与我们刚刚描述的生成过程兼容的智能方式组织潜在空间。
为了说明这一点,让我们考虑一下我们之前给出的例子,在这个例子中,我们描述了一个编码器和一个解码器,它足够强大,可以将任意( N )个初始训练数据放到实轴上(每个数据点被编码为实值),并在没有任何重建损失的情况下对它们进行解码。在这种情况下,自编码器的高度自由度使得编码和解码没有信息损失(尽管潜在空间的维数很低)成为可能,这导致了严重的过拟合,这意味着潜在空间的一些点在解码后会给出无意义的内容。如果这个一维的例子是自愿选择的,那么我们可以注意到,自编码器的潜在空间规则性问题比这要普遍得多,值得特别注意。
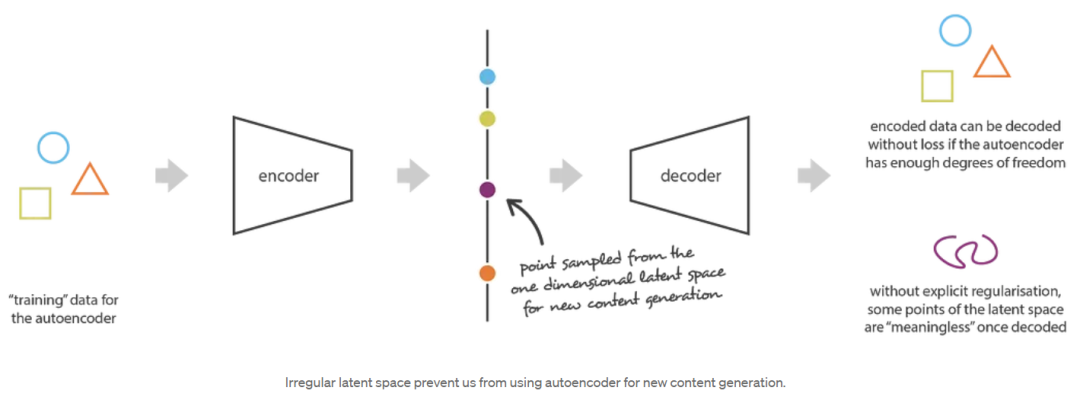
仔细想想,这种编码数据在潜在空间中缺乏结构是很正常的。事实上,在自动编码器训练的任务中,没有任何东西强制要求获得这样的组织:自动编码器只被训练以尽可能少的损失进行编码和解码,无论潜在空间是如何组织的。因此,如果我们对体系结构的定义不小心,很自然,在训练过程中,网络会利用任何过拟合的可能性来尽可能地完成它的任务……除非我们显式地规范它(unless we explicitly regularise it)!
3.4.2 变分自编码器(VAE)的定义
因此,为了能够将自编码器的解码器用于生成目的,我们必须确保潜在空间足够规则。获得这种规律性的一个可能解决方案是在训练过程中引入显式正则化。因此,正如我们在这篇文章的介绍中简要提到的,变分自编码器可以被定义为一种自编码器,它的训练是正则化的(regularised),以避免过拟合,并确保潜在空间具有良好的属性,使生成过程成为可能。
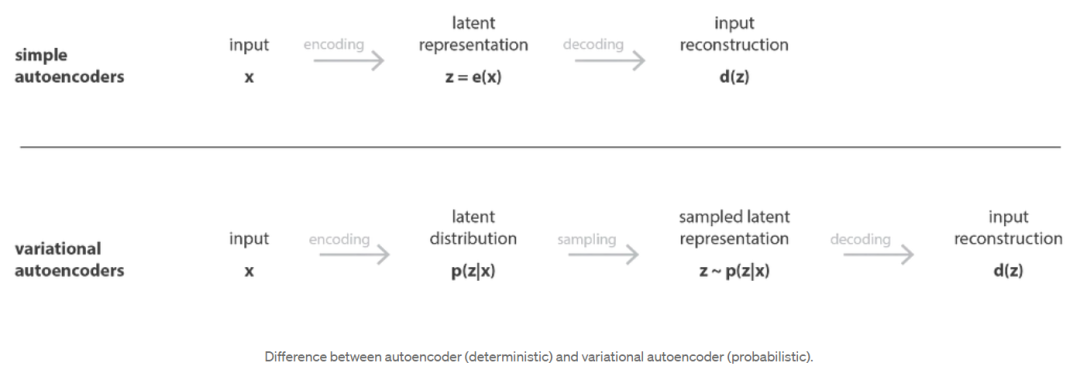
就像标准的自编码器一样,变分自编码器是一个由编码器和解码器组成的体系结构,它被训练成最小化编解码数据与初始数据之间的重构误差。然而,为了引入潜在空间的一些正则化,我们对编码-解码过程进行了轻微的修改:我们不是将输入编码为单个点,而是将其编码为潜在空间上的分布。然后对模型进行如下训练:
首先,将输入编码为潜在空间上的分布,
然后,从潜在空间的分布中采样一个点,
其次,对采样点进行解码并计算重构误差,
最后,将重构误差通过网络反向传播。
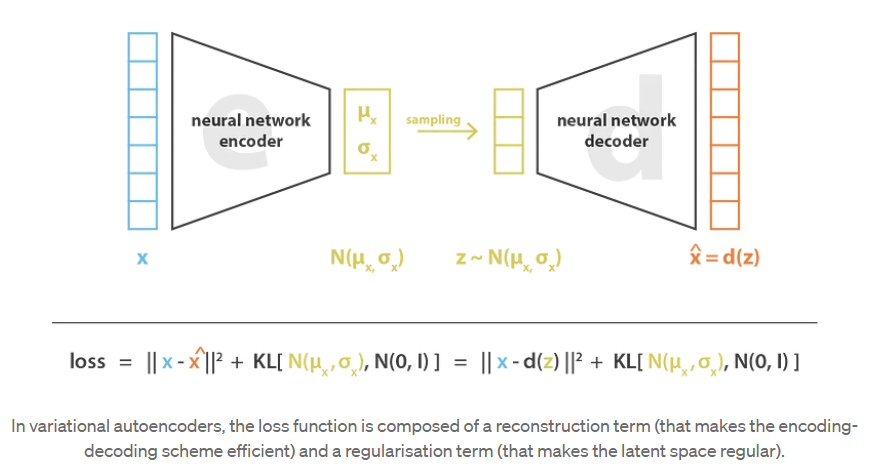
在实践中,编码分布被选择为正态分布,这样编码器就可以被训练来返回平均值和描述这些高斯分布的协方差矩阵。输入被编码为带有一些方差的分布而不是单点的原因是,它可以非常自然地表达潜在空间正则化:编码器返回的分布被强制接近标准正态分布。我们将在下一小节中看到,我们以这种方式确保潜在空间的局部和全局正则化(局部是因为方差控制,全局是因为均值控制)。
因此,训练变分自编码器(VAE)时最小化的损失函数由一个“重建项”(在最后一层)和一个“正则化项”(在潜在层)组成,它倾向于使编码-解码方案尽可能高效,它倾向于通过使编码器返回的分布接近标准正态分布来正则化潜在空间的组织。该正则化项表示为返回分布与标准高斯分布之间的Kulback-Leibler散度,并将在下一节中进一步证明。我们可以注意到,两个高斯分布之间的Kullback-Leibler散度有一个封闭的形式,可以直接用两个分布的均值和协方差矩阵表示。
3.4.3 关于正则化的直觉
为了使生成过程成为可能,从潜在空间中期望的规律性可以通过两个主要属性来表达:连续性(continuity, 潜在空间中的两个接近的点在解码后不应该给出两个完全不同的内容)和完备性(completeness, 对于选定的分布,从潜在空间中采样的点在解码后应该给出“有意义的”内容)。

变分自编码器(VAE)s将输入编码为分布而不是简单的点,这一事实不足以确保连续性和完整性。如果没有定义良好的正则化项,模型可以学习,为了最小化其重建误差,“忽略”返回分布的事实,并且表现得几乎像经典的自编码器(导致过拟合)。为此,编码器可以返回具有微小方差的分布(这往往是准时分布),也可以返回具有非常不同的方法的分布(这将在潜在空间中彼此相距很远)。在这两种情况下,都错误地使用了分布(取消了预期的好处),并且不满足连续性和/或完整性。 因此,为了避免这些影响,我们必须对协方差矩阵和编码器返回的分布的均值进行正则化。在实践中,这种正则化是通过强制分布接近标准正态分布(集中和减少)来完成的。这样,我们要求协方差矩阵接近单位矩阵(identity),防止出现点状分布,均值接近0,防止编码分布彼此相距太远。

有了这个正则化项(regularisation),我们防止模型在潜在空间中编码相隔很远的数据,并鼓励尽可能多的返回分布“重叠”,以这种方式满足预期的连续性和完备性条件。当然,对于任何正则化项,这是以训练数据上更高的重建误差为代价的。然而,重建误差和KL散度之间的权衡是可以调整的,我们将在下一节中看到平衡的表达式如何自然地从我们的形式推导中出现。
总结本小节,我们可以观察到,通过正则化获得的连续性和完整性(continuity and completeness)倾向于在潜在空间中编码的信息上创建一个“梯度”。例如,来自不同训练数据的两个编码分布的均值之间的潜在空间点应该在给出第一个分布的数据和给出第二个分布的数据之间的某个地方进行解码,因为它可能在两种情况下都被自动编码器(autoencoder)采样。
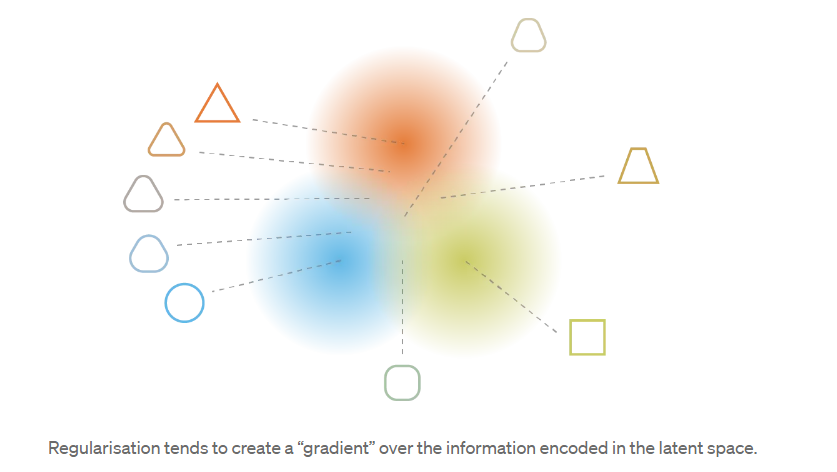
请注意。作为旁注,我们可以提到我们提到的第二个潜在问题(网络使分布彼此远离)实际上几乎等同于第一个问题(网络倾向于返回点状分布),直到尺度变化:在这两种情况下,分布的方差相对于它们均值之间的距离变得较小。
3.5 变分自编码器(VAEs)的数学细节
在上一节中,我们给出了以下直观的概述: 变分自编码器(VAE)s是将输入编码为分布而不是点的自编码器,其潜在空间“组织”通过编码器返回的接近标准高斯的约束分布进行正则化。在本节中,我们将给出变分自编码器(VAE)的更数学的观点,这将使我们能够更严格地证明正则化项。为此,我们将设置一个明确的概率框架(probabilistic framework),并将特别使用变分推断技术(variational inference technique)。
3.5.1 概率框架和假设
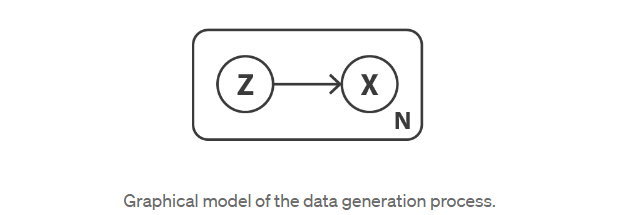
让我们首先定义一个概率图形模型来描述我们的数据。我们用x表示代表我们数据的变量,并假设x是由未直接观察到的潜在变量z(编码表示)生成的。因此,对于每个数据点,假设以下两步生成过程:
· 首先,从先验分布p(z)中采样潜在表示z;
· 其次,从条件似然分布p(x|z)中采样数据x。
有了这样一个概率模型,我们就可以重新定义编码器和解码器的概念。事实上,与考虑确定性编码器和解码器的简单自动编码器相反,我们现在要考虑这两个对象的概率版本。“概率解码器(probabilistic decoder)”自然由p(x|z)定义,它描述给定已编码变量的已解码变量的分布,而“概率编码器(probabilistic encoder)”由p(z|x)定义,它描述给定已解码变量的已编码变量的分布。
此时,我们已经注意到,我们在简单自编码器中缺乏的潜在空间的正则化自然出现在这里的数据生成过程的定义中: 潜在空间中的编码表示z确实被假设遵循先验分布p(z)。否则,我们还可以想起著名的贝叶斯定理,它将先验p(z),似然p(x|z)和后验p(z|x)联系起来
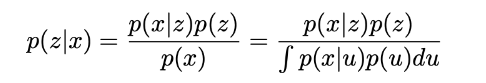
现在我们假设p(z)是一个标准高斯分布,p(x|z)是一个高斯分布,它的均值由变量z的确定性函数定义,它的协方差矩阵的形式是一个正常数c乘以单位矩阵I。假设函数f属于一个函数族F,这个函数族暂时不确定,以后会选择它。因此,我们有
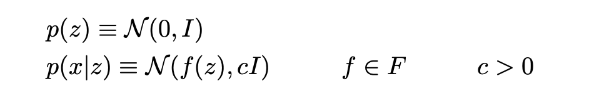
现在让我们考虑,是定义良好且固定的。在理论上,我们知道p(z)和p(x|z),我们可以用贝叶斯定理来计算p(z|x)这是一个经典的贝叶斯推理问题。然而,正如我们在上一篇文章中讨论的那样,这种计算通常是难以处理的(因为分母上有积分),并且需要使用近似技术,如变分推断(variational inference)。
请注意。这里我们可以提到p(z)和p(x|z)都是高斯分布。因此,如果我们有E(x|z)=f(z)=z,这意味着p(z)和p(x|z)的均值和协方差矩阵来表示p(z|x)的均值和协方差矩阵。然而,在实践中,这个条件是不满足的,我们需要使用一种近似技术,如变分推断(variational inference),使方法非常普遍,对模型假设的一些变化更健壮。
3.5.2 变分推断的公式
在统计学中,变分推断(variational inference, VI)是一种近似复杂分布的技术。我们的想法是设置一个参数化的分布族(例如高斯分布族,其参数是均值和协方差),并在这个分布族中寻找目标分布的最佳近似值。族中的最佳元素是最小化给定的近似误差测量(大多数情况下近似值和目标之间的Kullback-Leibler散度),并通过描述族的参数的梯度下降来找到。要了解更多细节,请参阅我们关于变分推断的帖子和其中的参考文献。
在这里,我们将通过高斯分布qx(z)来近似p(z|x),其均值和协方差由参数x的两个函数g和h定义。这两个函数应该分别属于函数和Rd和H族,稍后将详细说明,但应该是参数化的。因此我们可以表示
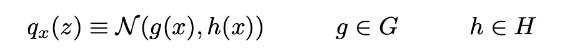
因此,我们以这种方式定义了一组变分推断的候选者,现在需要通过优化函数g和h(实际上是它们的参数)来找到这个家族中的最佳近似值,以最小化近似值与目标p(z|x)之间的Kullback-Leibler散度。换句话说,我们在寻找最优的g∗和h∗满足
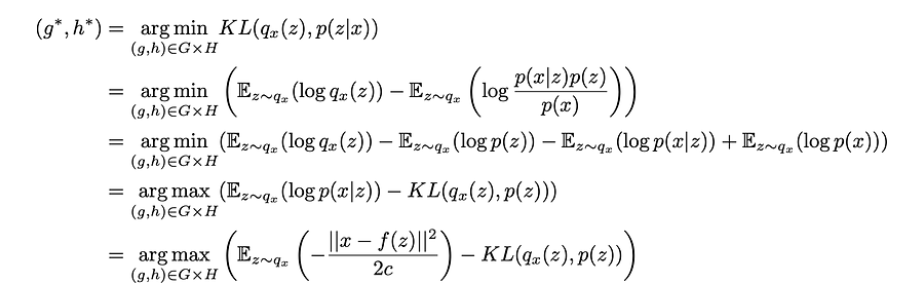
在最后一个方程中,我们可以观察到存在权衡-当近似后验p(z|x)时-在最大化“观察”的可能性(最大化期望的对数似然,对于第一项)和保持接近先验分布(最小化qx(z)和p(z)之间的KL散度,对于第二项)之间。这种权衡对于贝叶斯推理问题来说是很自然的,并且表达了我们对数据的置信度和对先验的置信度之间需要找到的平衡。
到目前为止,我们已经假设函数已知且固定,并且我们已经证明,在这样的假设下,我们可以使用变分推断技术近似后验p(z|x)。然而,在实践中,定义解码器的函数是未知的,也需要选择。要做到这一点,让我们提醒一下,我们的初始目标是找到一种高性能的编码解码方案,其潜在空间足够规则,可以用于生成目的。如果规则主要由潜在空间上假设的先验分布决定,则整个编解码方案的性能高度依赖于函数f的选择。实际上,由于p(z|x)可以(通过变分推断)近似于p(z)和p(x|z),并且(z)是一个简单的标准高斯分布,在我们的模型中,我们能够进行优化的仅有两个杠杆是参数c(定义可能性的方差)和函数f(定义可能性的平均值)。
因此,让我们考虑一下,正如我们之前讨论的那样,我们可以得到中的任何函数F中的任何函数f每个函数定义一个不同的概率解码器p(x|z)的后验概率p(z|x)的最佳近似值,记为qx∗(z)。尽管它的概率性质,我们正在寻找一个尽可能高效的编码解码方案,然后,我们想要选择函数f,当z从qx∗(z)中采样时,它使给定z的x,当我们从分布qx∗(z)中采样z,然后从分布p(x|z)中采样时,我们想要最大化x^=x的概率。因此,我们正在寻找最优的f∗,使得
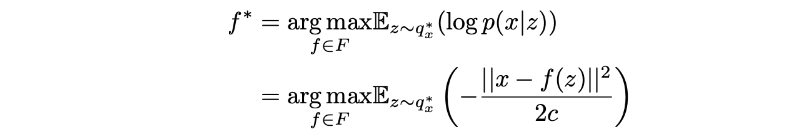
其中,qx∗(z)依赖于函数,其表达式如前所述。把所有的碎片放在一起,我们正在寻找最优的f∗,g∗和h∗,这样
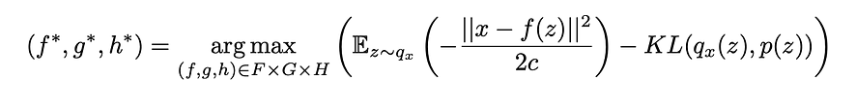
我们可以在这个目标函数中识别上一节给出的变分自编码器(VAE)s的直观描述中引入的元素x和f(z)之间的重构误差以及qx(z)和p(z)之间的KL散度给出的正则化项(这是一个标准的高斯函数)。我们还可以注意到常数c,它决定了前两项之间的平衡。c越高,我们假设模型中概率解码器在f(z)周围的方差越大,因此,我们越倾向于正则化项而不是重建项(如果c较低则相反)。
3.5.3 将神经网络引入模型
到目前为止,我们已经设置了一个概率模型,该模型依赖于三个函数f,g和h,并使用变分推断来表达要解决的优化问题,以便得到f∗,g∗和h∗,这些模型给出了最佳的编解码方案。因为我们不容易在整个函数空间上进行优化,所以我们限制了优化域并决定将f,g和h表示为神经网络。因此,F,G和H分别对应于由网络架构定义的函数族,并且对这些网络的参数进行优化。
在实践中,g和h不是由两个完全独立的网络定义的,而是共享它们的部分架构和权重,所以我们有
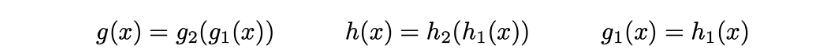
因为它定义了qx(z)的协方差矩阵,所以h(x)应该是一个方阵。然而,为了简化计算和减少参数的数量,我们做了额外的假设,我们的近似p(z|x),qx(z),是一个多维高斯分布的对角协方差矩阵(变量无关假设)。在这个假设下,h(x)仅仅是协方差矩阵对角元素的向量,并且与g(x)具有相同的大小。然而,我们以这种方式减少了我们考虑的变分推断的分布族,因此,得到的p(z|x)的近似值可能不太准确。
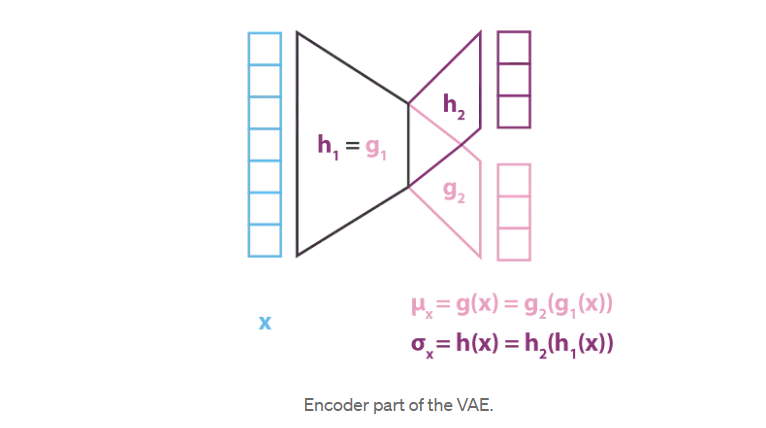
与对p(z|x)建模的编码器部分相反,我们考虑了均值和协方差都是x(g和h)函数的高斯函数,我们的模型假设p(x|z)是协方差固定的高斯函数。定义高斯均值的变量z的函数f由神经网络建模,可以表示如下
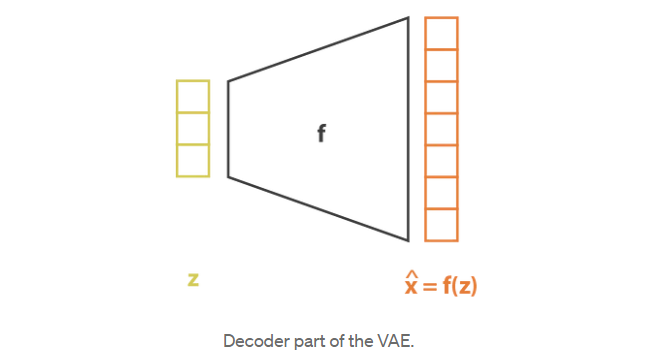
然后通过连接编码器和解码器部分获得总体架构。然而,我们仍然需要非常小心我们在训练期间从编码器返回的分布中采样的方式。采样过程必须以一种允许误差通过网络反向传播的方式来表示。一个简单的技巧,称为重参数化技巧,用于使梯度下降成为可能,尽管随机抽样发生在架构的中间,并且使用这样一个事实,即如果z是一个随机变量,遵循高斯分布,平均值为g(x),协方差H(x)=(x)⋅Ht(x),那么它可以表示为
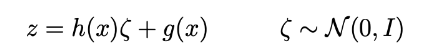
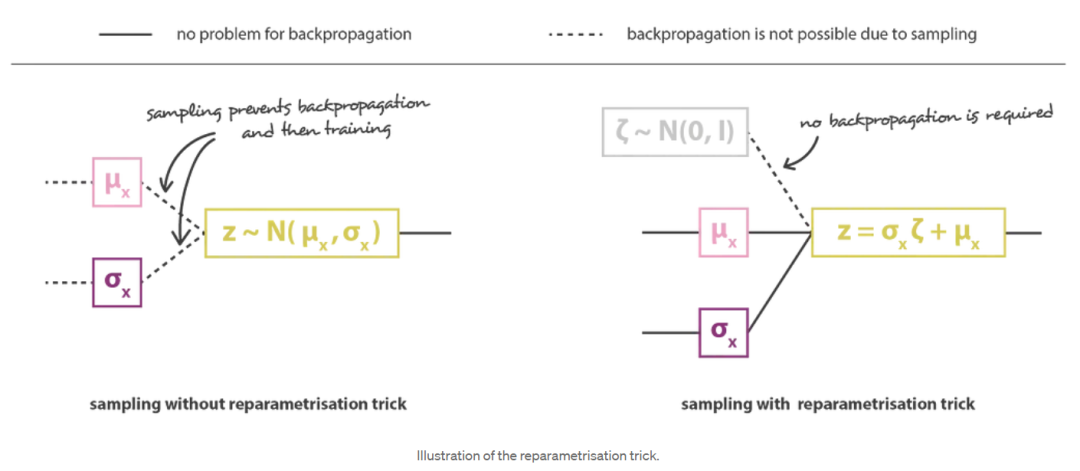
最后,以这种方式获得的变分自编码器结构的目标函数由上一节的最后一个方程给出,其中理论期望被一个或多或少精确的蒙特卡罗近似所取代,该近似在大多数情况下由单个绘制组成。因此,考虑到这个近似并表示C=1/(2c),我们恢复在上一节中直观导出的损失函数,由重建项、正则化项和定义这两个项的相对权重的常数组成。
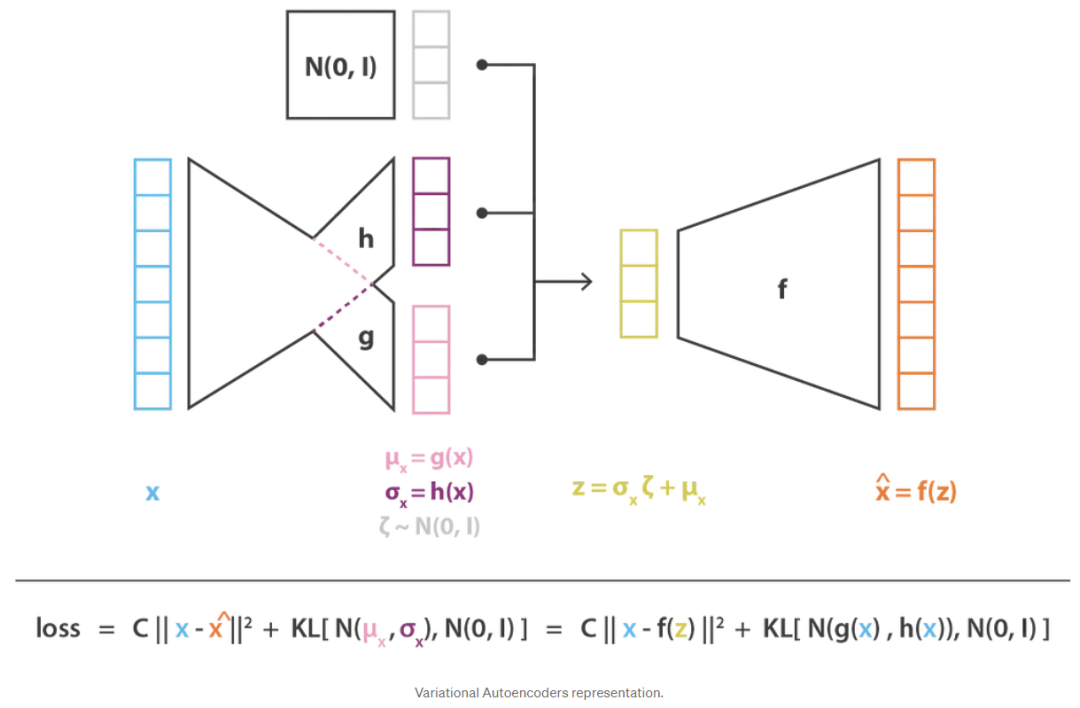
3.6 要点(Takeaways)
本文的主要观点是:
· 降维是减少描述某些数据的特征数量的过程(要么只选择初始特征的一个子集,要么将它们组合成减少数量的新特征),因此可以看作是一个编码过程。
· 自编码器是由一个编码器和一个解码器组成的神经网络架构,它为数据创造了一个瓶颈,并且在编解码过程中被训练成丢失最小数量的信息(通过梯度下降迭代训练,目标是减少重建误差)。
· 由于过拟合,自编码器的潜在空间可能是非常不规则的(潜在空间中接近的点可能会给出非常不同的解码数据,潜在空间中的某些点一旦解码后可能会给出无意义的内容……),因此,我们无法真正定义一个生成过程,即简单地从潜在空间中采样一个点,并使其通过解码器获得新数据。
· 变分自编码器(VAEs)是一种解决潜在空间不规则性问题的自编码器,它使编码器在潜在空间上返回一个分布,而不是一个单点,并通过在损失函数中添加一个正则化项来返回分布,以确保更好地组织潜在空间。
· 假设一个简单的潜在概率模型来描述我们的数据,非常直观的变分自编码器(VAE)s损失函数,由重建项和正则化项组成,可以仔细推导,特别是使用变分推断的统计技术(因此称为“变分”自编码器)。
总之,我们可以概括地说,在过去的几年里,生成对抗网络(GAN)比变分自编码器(VAE)s受益于更多的科学贡献。除其他原因外,社区对生成对抗网络(GAN)表现出的更高兴趣可以部分解释为,与生成对抗网络(GAN)中的对抗性训练概念的简单性相比,变分自编码器(VAE)理论基础(概率模型和变分推断)的复杂性更高。通过这篇文章,我们希望能够分享有价值的直觉和强大的理论基础,让新手更容易接触到变分自编码器(VAE),就像我们今年早些时候为生成对抗网络(GAN)所做的那样。
然而,既然我们已经深入讨论了这两个问题,还有一个问题……你们是更倾向于生成对抗网络(GAN)还是变分自编码器(VAE)?
文章改编转载自微信公众号:计算微生物组学
原文链接:https://mp.weixin.qq.com/s/jdtTYjSqV01eEeKJOHs65w?scene=1 | 





















