本帖最后由 宇宙微尘 于 2025-8-14 18:49 编辑
本文发表在《信息通信技术与政策》2025 年第 7 期:http://ictp.caict.ac.cn/CN/10.12267/j.issn.2096-5931.2025.07.004。本文摘录其中关键内容,全部内容可点击链接查看。

摘要:生命科学基础研究和药物发现中存在大量的复杂计算需求,时常面临高频的大规模组合优化问题求解和复杂分布采样,基于经典计算框架的方法在这些问题上难以权衡时间和准确率,计算结果往往 “失之毫厘,差之千里”,较低的求解质量和采样偏移最终导致构象偏差和较高的筛选假阳性,造成了药物发现高昂的时间成本和花费,因此亟需一种兼具筛选效率和准确率的计算框架摆脱这一困境。随着物理硬件的发展,多种新型的量子计算框架在不同复杂计算问题上得到了广泛验证,其中相干伊辛机 (Coherent Ising Machine,CIM) 是目前发展较快的技术路线之一,其通过利用光学参量振荡脉冲作为量子比特,在运行中可以搜索出伊辛模型基态时的自旋构型,从而提升求解组合优化问题的计算速度和正确率。该技术路线在比特全连接特性、比特数规模、长时连续求解稳定性等方面较现有其他技术路线有较大优势。主要从 CIM 的底层原理、技术优势、生命科学基础研究和药物发现中的主要应用以及 CIM 目前实用化应用的挑战展开论述,并对未来发展进行展望。
关键词:相干伊辛机;组合优化;玻尔兹曼采样;生命科学;药物发现
0 引言
生命科学基础研究和药物发现存在诸多复杂计算过程,其复杂性来源于生物数据的高噪声和多模态、不同组学层次生物分子的非线性互作关系、高度动态的分子构象变化、日益增长的化学分子搜索空间等,如何从海量的生物多模态数据挖掘得到有价值的生物信息并筛选得到有结合活性的化学分子成为目前领域内的研究热点。然而,受限于摩尔定律,经典计算框架所提供的算力支持已经相当有限,现有计算方法在处理海量生物多模态数据和在巨大的化学搜索空间得到有活性的分子时显得 “力不从心”,且在速度和精度上难以平衡。因此,亟需一种先进的算力和方法来改善这种困境。量子计算作为一种新兴的计算范式,其强大的并行计算和模拟能力在一些复杂计算问题上得到了广泛验证,成为解决上述问题的一种有效途径。
随着物理硬件的发展,一系列非经典计算框架被不断提出,如量子退火机 (Quantum Annealer, QA)、高斯玻色子采样器和相干伊辛机 (Coherent Ising Machine,CIM) 等,这些新兴的计算体系在不同复杂计算问题上得到了初步验证。其中,以简并光学参量振荡器 (Degenerate Optical Parametric Oscillator,DOPO) 为计算比特的 CIM 通过实现自旋比特间的任意耦合,可以针对大规模组合优化问题 (Combinatorial Optimization Problem,COP) 快速求解,被视为一种新型的针对 COP 的专用光量子计算处理器。另外,基于伊辛模型 (Ising Model) 的能量函数可以通过 CIM 进行采样,生成服从玻尔兹曼分布 (Boltzmann Distribution) 的样本。趋于体系能量基态演化是自然状态分子体系的基本规律,自然状态下的小分子化合物、生物大分子的不同构象分布遵从能量状态的玻尔兹曼分布,基于伊辛模型的 CIM 采样可以很好地映射到分子构象采样求解体系。以伊辛模型为纽带,借助 CIM 在大规模组合优化问题求解和复杂分布采样的能力,在生命科学基础研究和药物发现计算的诸多场景得到了广泛应用。
1 CIM 在求解大规模 COP 时的优势
1.1 CIM 计算基本原理及伊辛模型
1.1.1 CIM 底层计算原理
相干伊辛机是基于光量子耗散架构的专用量子计算机,其核心器件是 DOPO,用于模拟伊辛模型中的自旋系统。其计算原理是:当泵浦光强度逐渐增加并接近振荡阈值时,DOPO 会发生相位破缺,产生 0 相位或 π 相位两种稳定状态,分别对应伊辛自旋的向上 (+1) 和向下 (-1) 状态。通过调控 DOPO 之间的耦合强度,可以编码待求解的优化问题。系统在演化过程中会自发寻找能量最低的状态,对应问题的最优解或近似最优解。
1.1.2 伊辛模型
伊辛模型是统计物理学中描述相变与临界现象的核心模型,通过简化粒子间的相互作用 (如自旋) 揭示复杂系统的集体行为。对于 N 自旋系统,其每一个自旋有两种状态,即σ_i=+1和σ_i=−1,分别表示自旋方向向上和向下。伊辛模型可以和二次无约束优化 (Quadratic Unconstrained Binary Optimization,QUBO) 问题进行转化,其中 QUBO 模型的自变量取值为 {0,1}。
1.2 CIM 在求解大规模 COP 的优势
1.2.1 CIM 的全连接优势
在 CIM 中,每个 DOPO 脉冲的相位和振幅信息被测量并反馈到所有其他脉冲上,从而实现了任意两个自旋之间的耦合。全连接使得 CIM 能够直接映射需要长程相互作用的组合优化问题。由于全连接,系统能够更快地收敛到基态,同时,全连接增加了系统的连通性,有助于求解过程中跳过局部最优解。相较于 D-Wave 为代表的 QA 在更复杂的连接图(d>3)的 max-cut 标准测试中,全连接 CIM 在求解成功率上有显著优势,说明 CIM 在真实场景的复杂问题中求解较 QA 将有更高的准确率。另外,CIM 的物理级全连接消除了硬件拓扑限制,而 QA 需通过辅助量子比特链模拟全连接,导致资源开销倍增。因此,同等规模的硬件,CIM 相较于 QA 有更多比特资源用于真实计算。
1.2.2 CIM 长时连续稳定的计算优势
生物复杂计算和药物筛选中时常面临高频的计算需求,因此,实现整个计算链路的稳定求解对于量子计算工程化应用具有重要意义。CIM 通过光学相变的自稳定特性和量子噪声主动抑制机制来维持稳定,在硬件层,基于对整个光路和计算体系进行温度控制和隔振优化,可提高 DOPO 稳定性从而提高稳定长时计算能力。
1.2.3 CIM 大比特数的求解规模优势
量子计算实用化限制的另一因素是求解规模的限制,现实场景问题随着建模分子的尺度增加,会导致所需计算资源的提升。现有技术方案中,CIM 是制备可计算量子比特数最高的技术路线之一,目前实验室已实现具有约 10.1 万个 DOPO 脉冲的 CIM ,其中有超过 100 亿个自旋与自旋间的相互作用来构成计算网络。北京玻色量子科技有限公司 (简称 “玻色量子”) 进一步优化了基于测量 - 反馈架构 CIM,完成了 CIM 的工程化,并于 2023 年 5 月、2024 年 4 月、2025 年 5 月分别发布了 100 节点、550 节点、1000 节点的 CIM。稳定的大比特数计算能力使得目前 CIM 体系能够满足一些生物复杂计算和药物发现场景的计算规模需求,在一些复杂计算问题上得到指数级加速。
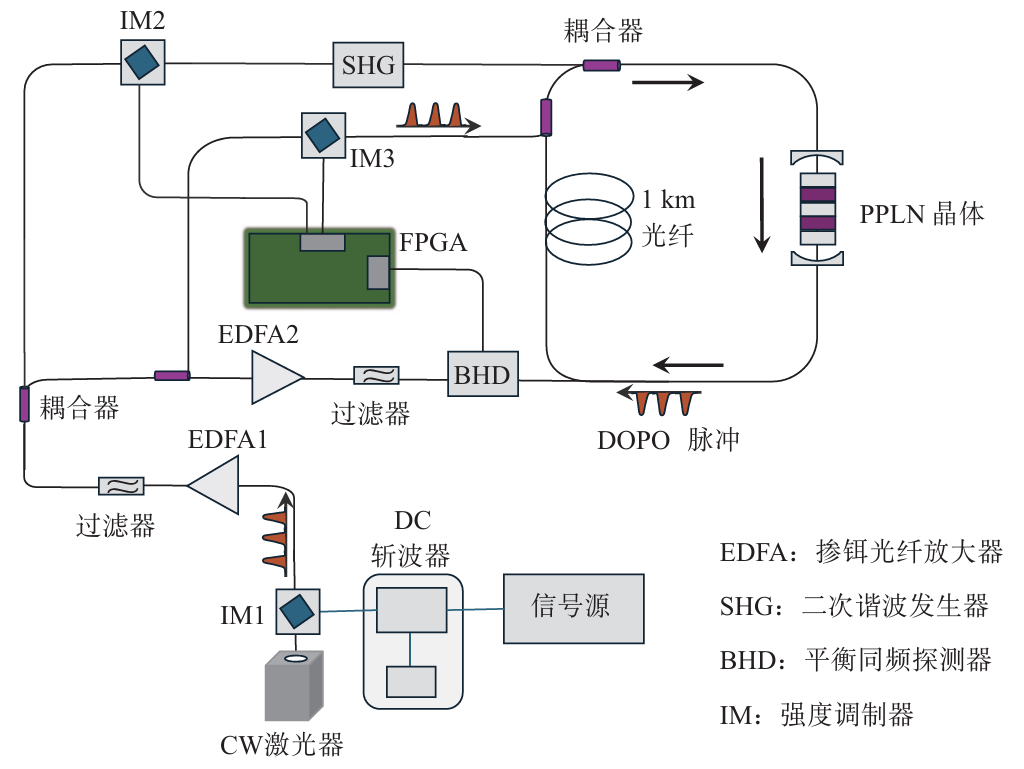
图1 带测量反馈电路的CIM
2 相干伊辛机在生命科学基础研究和药物发现中的应用
生命科学基础研究的目标是解析复杂生命系统,弄清遗传发育规律,找到关键调控因子,从而为疾病治疗提供理论依据和靶点信息。随着生物技术的发展,如今能以前所未有的分辨率从不同组学维度捕捉相关生物学信息,但随之而来的是海量的高维生物数据,如何从这些数据中挖掘得到有价值的生物信息是目前生物学家们最关心的问题之一。与之呼应的是化学搜索空间的指数级增长,目前已达到1060量级,如何快速地从海量的搜索空间中筛选得到有活性的分子成为药物发现的另一大难题。目前基于 CIM 的使用策略主要分为大规模组合优化问题求解和基于能量函数的玻尔兹曼采样 (Boltzmann Sampling) 。
2.1 基于伊辛模型的最优化问题求解应用
计算机辅助药物设计 (Computer-Aided Drug Discovery,CADD) 的技术发展显著提高了药物发现效率,同时降低了成本。然而,在 CADD 中,存在大规模 COP 的高频计算需求,现有算法的求解能力严重限制了其速度和准确性。基于伊辛模型的建模策略可以映射到一般的二值组合优化问题,通过将复杂计算场景问题转化为伊辛模型,可借助 CIM 的硬件优势实现问题求解的指数级加速。
2.1.1 基于结构的虚拟筛选 - 分子对接
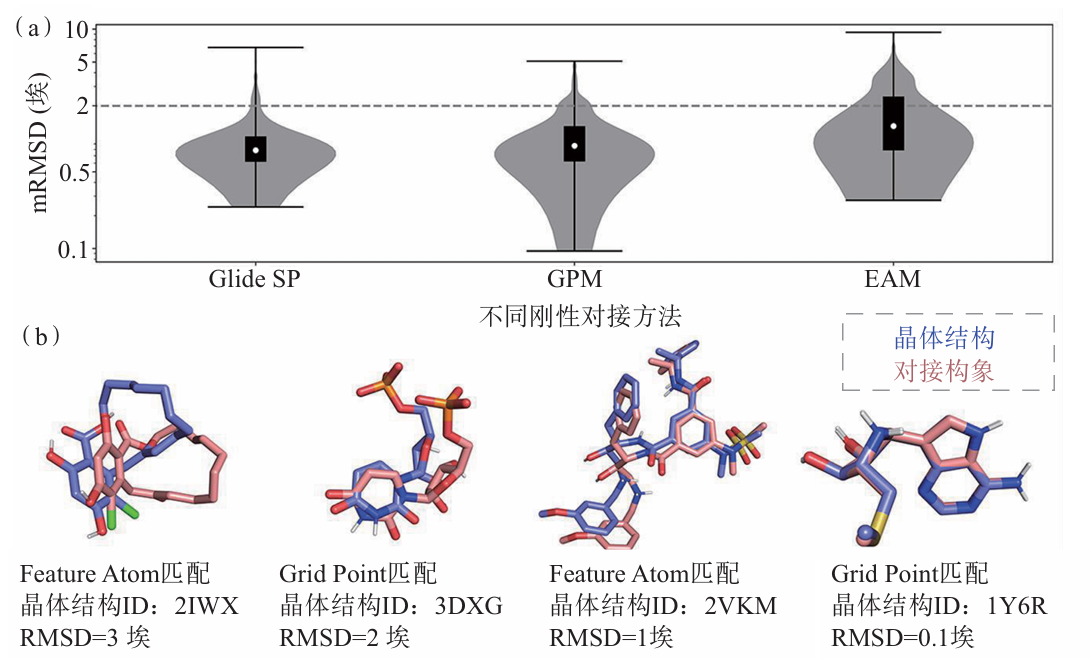
图2 GPM和FAM在CASF-2016数据集上的采样表现比较
分子对接 (Molecular Docking) 是基于配体 - 受体识别的锁钥模型提出的技术方法,通过计算配体 - 受体之间的空间互补状态以及能量匹配来寻找复合物模式,是基于结构的虚拟筛选中的重要技术手段。经典的分子对接主要分对接构象采样和打分两步,其中对接构象采样是一个 NP-hard 问题,巨大的对接构象搜索空间使得经典计算在采样时间和准确率上难以兼顾,严重限制了活性分子筛选效率。2023 年,玻色量子与上海交通大学联合研究团队提出了网格点匹配 (Grid Point Matching, GPM) 和原子特征匹配 (Feature Atom Matching,FAM) 算法模型,通过将配体与靶蛋白的对接问题转换为配体原子和对接格点的匹配问题,并添加位置约束和配体空间形状约束,构建得到伊辛模型,通过 CIM 求解上述伊辛模型可得到配体对接构象。
研究团队在 CASF-2016 标准测试集对基于 CIM 的对接方法和商业化对接工具 Glide SP 进行了表现对比。结果显示,GPM 与商业化软件的采样能力相当,但在速度上,基于 CIM 的求解速度比经典算法快至少 3 个数量级,该算法显著提升了对接效率,有望实现高精度的超高通量筛选。
2.1.2 基于配体的虚拟筛选 - GMS
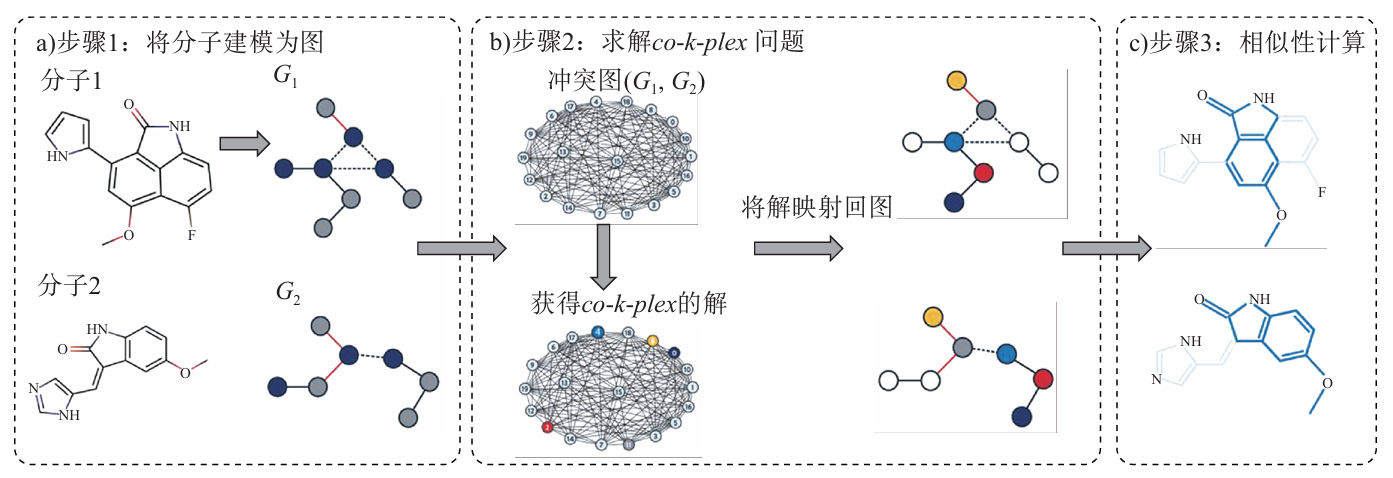
图3 基于图的GMS算法示意图
分子相似性 (Molecular Similarity) 是化学分子间的重要比较信息,相似性原理指出,总体相似的分子应具有相似的生物活性,分子相似性应用广泛,包括靶标预测、结合姿态预测、毒性预测、挖掘靶标与药物数据关联、虚拟筛选等。现有方法主要利用分子指纹的表征方式进行相似性计算,但其只考虑二维的原子及官能团排布,忽略了分子中不同原子的空间位置关系,这些构效关系对于分子与蛋白的结合至关重要。Maritza Hernandez 等提出基于图论方法解决分子相似性计算 (Graph-based Molecular Similarity,GMS) 中的原子匹配问题。通过构建冲突图 (Conflict Graph) 并添加相关约束构建 QUBO/Ising 模型,并使用 QA 在小规模数据上进行了验证。上述模型在 CIM 上可同样求解,在 CIM 大比特数以及全连接特性下,能解决更复杂的分子匹配问题。
2.1.3 基于 QUBO/Ising 模型的分子从头设计和优化
相较于从已有分子库中进行活性分子筛选,分子从头设计是另一种新兴成药策略。分子从头设计指不依赖已知分子模板,而通过算法生成全新分子结构。优化过程则需调整分子特性如生物活性、成药性等,可分为基于原子、基于片段、基于反应的分子从头设计。Akshay Ajageka 等构建了一个基于深度学习和 QUBO/Ising 的从头设计优化框架,该框架包含一个基于分子表征预测化学性质的回归模型,同时还包含一个基于目标化学性质进行序列优化的 QUBO/Ising 模型。其优化目标是不断迭代得到一个确定分子不同位置原子组成的邻接矩阵A**ij使得其预测的化学性质逼近目标化学性质。该模型基于 QA 进行了小规模验证,借助 CIM 的大规模 COP 求解能力,可以较原工作设计得到更大的分子以及实现多目标优化。
2.1.4 伊辛机增强的 D-VAE 实现分子性质优化
变分自编码器 (Variational Autoencoder,VAE) 是目前流行的一种生成模型,其核心思想是通过编码器将输入数据映射到潜在空间,然后通过解码器从潜在空间生成数据。2023 年,Tsud 研究团队将相干伊辛计算应用于自动分子设计优化上,构建了基于图的离散 VAE (D-VAE),将分子结构编码为 {0,1} 的离散潜在向量,同时训练因子分解机 (Factorization Machine) 作为性质预测的代理模型;使用伊辛机在离散潜在空间中搜索得到更优的隐变量表示,通过 decoder 可以解码得到真实分子图或者序列信息。该研究说明离散的隐变量空间可能更符合化学分子的真实能量分布,在该隐空间采样可以生成得到性质更优、多样性更好的分子。
2.2 基于 CIM 的玻尔兹曼采样及相关应用展望
玻尔兹曼采样是一种基于玻尔兹曼分布的概率采样方法,主要应用于统计物理学、机器学习和优化问题中。伊辛模型中哈密顿量描述了各个自选变量两两互作和自身的能量状态,因此在温度确定下,CIM 基于伊辛模型的采样结果应该符合玻尔兹曼分布。2016 年,Hiromasa Sakaguchi 等将 CIM 首次应用于基于结构虚拟筛选的分子优化场景中,通过建立配体分子片段组合以及和靶点结合的能量函数计算模型,实现了 CIM 基于玻尔兹曼采样的活性片段筛选优化,证明了基于 DOPO 计算的 CIM 在以伊辛模型为基础的玻尔兹曼采样能力。结合已有研究,本文列举了 CIM 基于玻尔兹曼采样的两个重要应用方向。
2.2.1 小分子构型采样
分子构型采样是 CIM 基于玻尔兹曼采样的应用拓展方向之一。分子构型采样是计算化学和分子模拟中的核心任务,旨在探索分子的可能空间构型如键长、键角、二面角等,用于研究分子稳定性、反应路径、自由能景观、晶型预测等。主要方法包括基于蒙特卡洛采样的构象随机生成和基于分子动力学 (Molecular Dynamics,MD) 的数值求解牛顿运动方程来模拟原子的运动轨迹。基于蒙特卡洛的分子构型采样往往容易陷入局部最优,随机变化的方向和幅度难以预判,因而很难获得下一个重要构象,难以在短时间内采样得到最低能量构象;基于 MD 的运动轨迹模拟需要建立在有效的力场体系下,经典力学体系在计算速度上较快,但精度欠佳;基于量子力学的体系精度尚可,但计算量巨大,只能在局部区域实现量子级模拟,这些方法的局限性使得高精度的构型采样在现有计算体系下很难满足。Kevin Mato 等通过将分子键角、二面角等采样参数离散化并以分子展开距离目标函数构建 QUBO/Ising 模型实现了分子折叠预测。受此启发,可通过对不同键角和二面角进行离散化并构建整体能量函数,借助 CIM 可实现基于玻尔兹曼分布的分子构型采样。
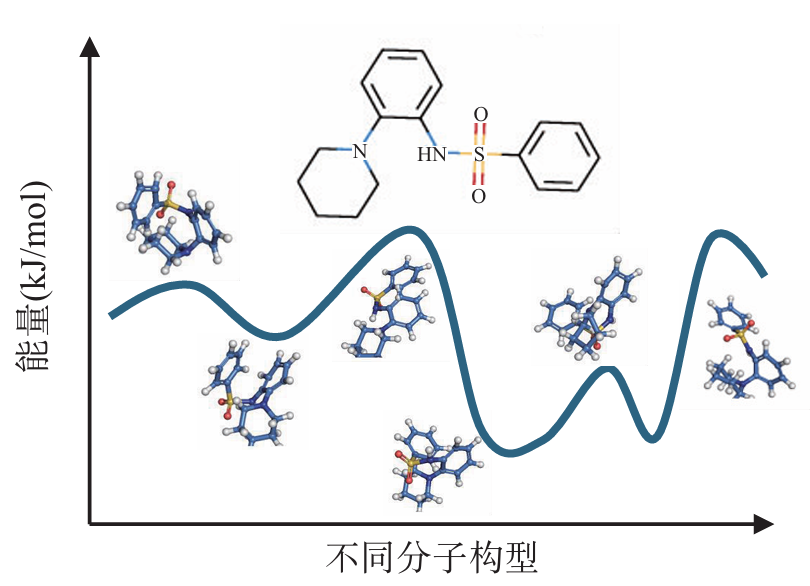
图4 不同分子构型的能量分布
2.2.2 蛋白折叠路径预测
CIM 基于玻尔兹曼采样的另一个重要可应用方向为蛋白质折叠预测。自然状态下,线性氨基酸链通过一系列物理化学作用自发形成特定三维结构,该折叠过程决定了蛋白质的功能,若折叠错误可能导致严重疾病,如阿尔茨海默病、帕金森病等。折叠过程遵循热力学第二定律,由自由能最小化原则主导。多肽链通过疏水作用、氢键、范德华力等非共价相互作用,从高能无序态 (变性态) 转变为低能有序态 (天然态)。对于生物大分子,先进的基于人工智能的方法 (如 AlphaFold、RoseTTAFold 等) 能预测较高精度的晶体结构,但此结构是大分子固定状态时的空间结构信息,无法描述其具体的折叠动态过程。探究此过程一般借助经典计算下的 MD 模拟方法,然而,MD 在经典力学力场下模拟全原子运动轨迹也需要消耗巨大算力,更精确的量子力学力场体系则只能模拟局部原子的运动信息。Danial Ghamari 等构建了一个基于 QA 和经典计算的混合框架,实现了蛋白质等大分子的稀有构象转变路径的高效采样,克服了传统 MD 模拟在时间尺度上的局限性。该框架首先基于 Intrinsic Map Dynamics iMapD 建立了蛋白构象空间C={Xk}并将构象空间离散化为节点代表构象区域和边 (代表区域间转移权重) 的图,其次基于 Langevin 动力学推导出粗粒度有效作用量 (coarse-grained effective action) 作为权重,从而将路径采样问题转换为基于哈密顿量的连通图采样,其中目标哈密顿量HT=αHpath+Haction,Hpath 为约束路径拓扑,Haction 为路径统计权重。上述模型可转换为 CIM 适配的伊辛模型,并基于能量函数进行玻尔兹曼采样得到大分子的构象转移路径分布,基于大比特数的 CIM 能实现更多构象的转移路径,得到较为连续的构象转移过程模拟。
3 当前 CIM 在生物复杂计算应用的挑战
目前基于 CIM 的相关算法在分子对接、分子相似性计算、生物序列设计等具体应用场景进行了深度验证,但其在大规模实用化层面依然存在一定的挑战,主要包括 CIM 的比特数资源、混合计算整体链路的时间延迟以及基于 QUBO/Ising 建模描述复杂计算体系的能力。未来,CIM 在真实场景实现大规模应用的可优化方向包括以下 3 点。
3.1 大比特数 CIM 的工程化实现
目前,CIM 在实验室已实现 10 万量级比特数的测试规模,但目前能提供稳定的计算服务的比特数规模只在数百比特量级。而生物复杂计算场景如分子折叠模拟、构型采样随着模拟对象分子的原子数增加,其所需计算比特资源会成指数级增长,目前量级的 CIM 可能无法完全覆盖所有规模模拟对象的计算。未来,大比特数 CIM 的工程化实现将大大提高其解决实际问题的能力,在大分子折叠模拟、构型采样等问题上实现突破。
3.2 CIM - 经典计算的 I/O 时间优化
当前基于 CIM 的复杂计算建立在和经典计算相互融合的模式上,CIM 在整个计算链路中的组合优化问题求解和复杂采样上步骤上实现了指数级加速,但 CIM 求解数据前处理和后处理依然交由 CPU 和 GPU 完成。在大规模筛选和高频计算需求下,数据在 CIM 和经典计算的 I/O 时间将成为制约其计算效率的因素之一。该优化方向依赖于 CIM 和经典计算硬件层和软件层任务调度的协同发展,未来混合计算的低延时数据传输将显著提升整体计算链路的时间,在大规模化合物库筛选实现加速,从而提高化合物筛选效率。
3.3 QUBO/Ising 模型描述场景问题的局限性
建立 QUBO/Ising 模型是 CIM 应用的基础,生物复杂计算场景为了方便适配硬件求解,在很多场景的建模上采取了一定的简化处理,如原子间作用力的计算、空间位置的稀疏离散化、大分子粗粒化处理等,这些建模方式会丢失很多信息,造成模拟精度的损失。随着硬件比特规模的提升,可以优化建模策略,实现更细尺度的空间划分以及全原子模拟,从而提高计算精度。
4 结束语
CIM 作为含噪声中等规模量子(Noisy Intermediate Scale Quantum,NISQ)时代最具应用前景的量子计算平台之一,在生命科学基础研究和药物发现领域展现出独特价值。其基于光量子的物理实现方式与生物分子体系的能量演化过程具有天然的契合性,为大规模 COP 求解和复杂分布采样提供了全新途径。未来,随着 CIM 底层硬件规模的扩展、混合计算链路优化以及算法建模信息完全度的提升,CIM 有望在生命科学基础研究和药物发现领域取得更大突破,主要包括 4 方面。一是大规模虚拟筛选和分子优化设计,覆盖更广阔的化学空间;二是小 / 大分子折叠预测,解决生物大分子的构象采样难题;三是多药物临床使用组合优化,设计多靶点、低副作用的创新药物组合;四是个性化医疗,根据患者遗传信息定制个性化治疗方案。未来,大比特数的 CIM 将成为生物复杂计算的重要算力支撑板块,更广泛普适的应用将加速生命科学重大发现,降低药物研发成本,为人类生命健康提供重要保障。
—— END —— | 





















