本帖最后由 哈奇一 于 2026-3-23 17:09 编辑
化学预训练模型因在药物发现领域的应用而受到广泛关注。通过自监督训练提取的通用化学知识,有望改善关键药物发现终点的预测,包括靶点结合效力和ADMET性质。
2025年10月14日,默沙东与英伟达的研究人员于在arXiv上发表研究成果,题为“Multitask finetuning and acceleration of chemical pretrained models for small molecule drug property prediction”。

该研究在化学预训练图神经网络模型的微调过程中引入多任务机制,结果显示其性能显著优于未预训练的图神经网络模型。以多任务方式微调KERMT模型时,数据规模越大,性能提升越显著。此外,发布了两个多任务ADMET数据划分方案,以实现对多任务深度学习方法在药物性质预测中更精准的基准测试。最后,在GitHub上提供了KERMT模型的加速实现,为工业级药物发现工作流中的大规模预训练、微调和推理提供支持。
KERMT代码仓库:https://github.com/NVIDIA-Digital-Bio/KERMT
背景
在药物发现中,预测性机器学习模型正越来越多地被用于指导小分子和环肽的多属性优化。近年来深度学习的进展使得模型的预测精度实现了跨越式提升,特别是在ADMET性质预测方面。有监督深度学习架构,尤其是图神经网络,正越来越多地应用于实际药物发现流程中的性质预测。然而,这些方法在数据量较少的情况下性能往往有限。在这种情况下,通常会采用随机森林等传统方法,尽管这些方法所需的特征工程并非易事。
近期围绕化学预训练模型的研究旨在解决当前方法的局限性。预训练模型所含的通用知识能够生成更具表达力的分子表征有望提升模型性能,尤其是在小数据集上。在药物性质预测中,特别是ADMET性质,许多任务之间是相互关联的,这为使用多任务学习提供了机会。多任务学习是一种基于相关任务的归纳迁移学习来提升性能的方法。尽管这种方法已被广泛应用于改进从头训练的深度学习架构中的分子性质预测,但它尚未被探索作为化学预训练模型的微调方法。
实验设置
本研究的总体框架如图1所示。首先以单任务方式对三种不同的预训练编码器模型进行了基准测试,并对其中性能最优的模型应用了多任务微调方法。为此,评估KERMT、KPGT和MoLFormer,其中KERMT对GROVER重新实现并进一步增强,每种模型采用不同的分子表示方法和不同的自监督训练算法(图1b)。在微调阶段,允许所有模型的编码器和前馈网络的权重进行更新。对于KPGT,采用了两种微调方案,即简单微调模型KPGT仅更新编码器和前馈网络的权重;而复杂微调模型KPGTcomplex则采用了原论文中提出的复杂微调策略。
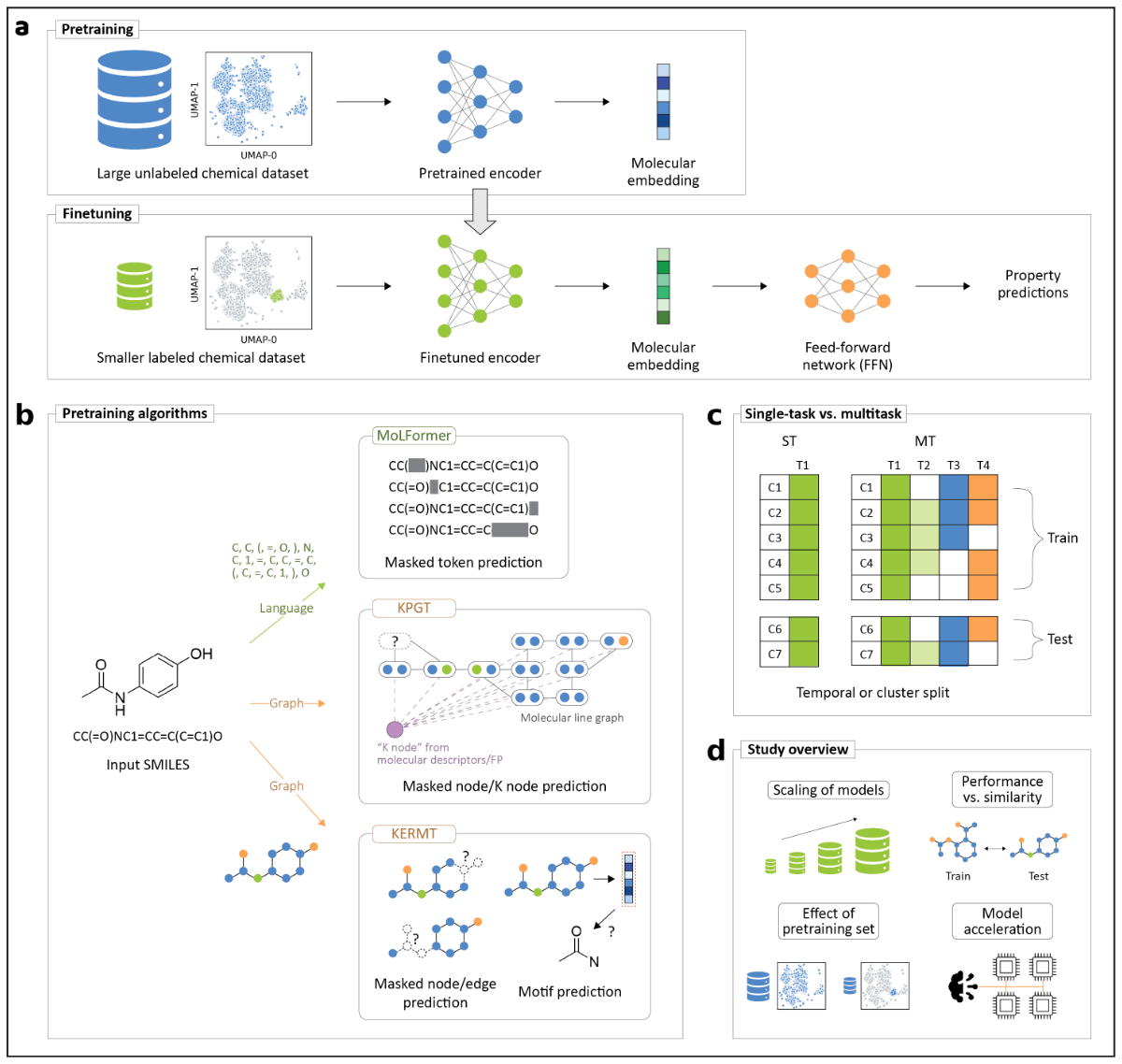
图1 研究方案示意图
结果
化学基础模型基准测试
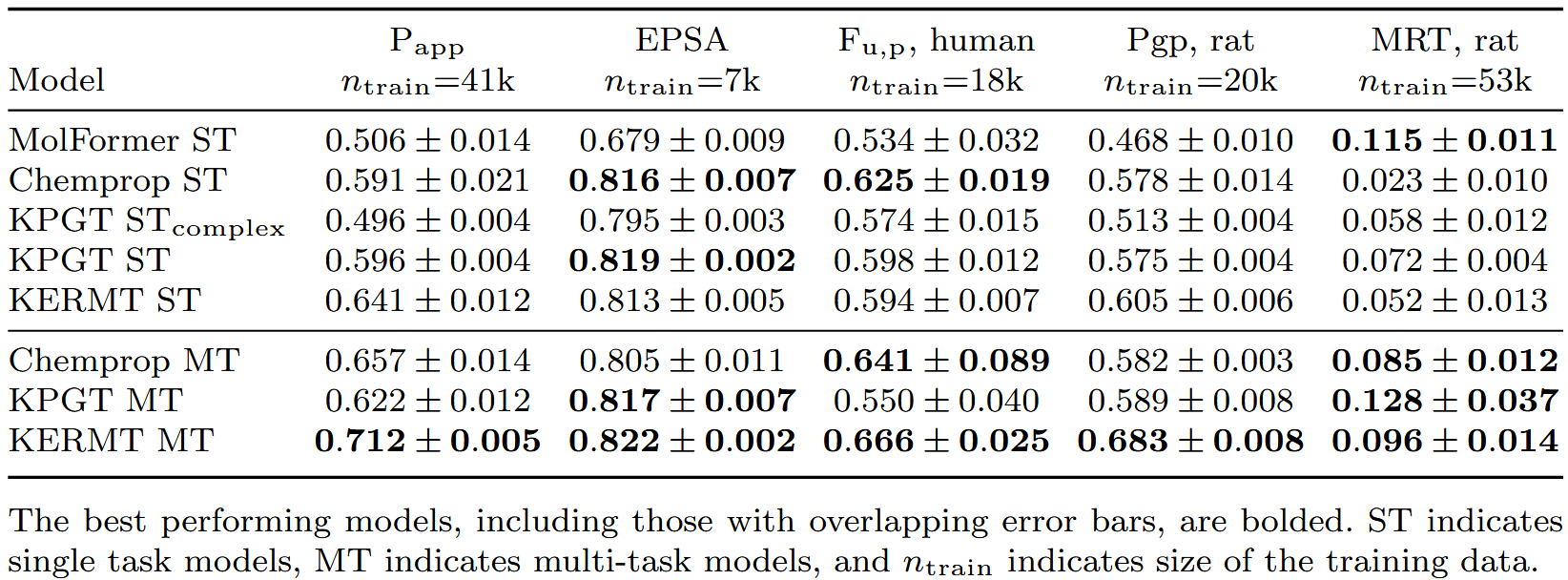
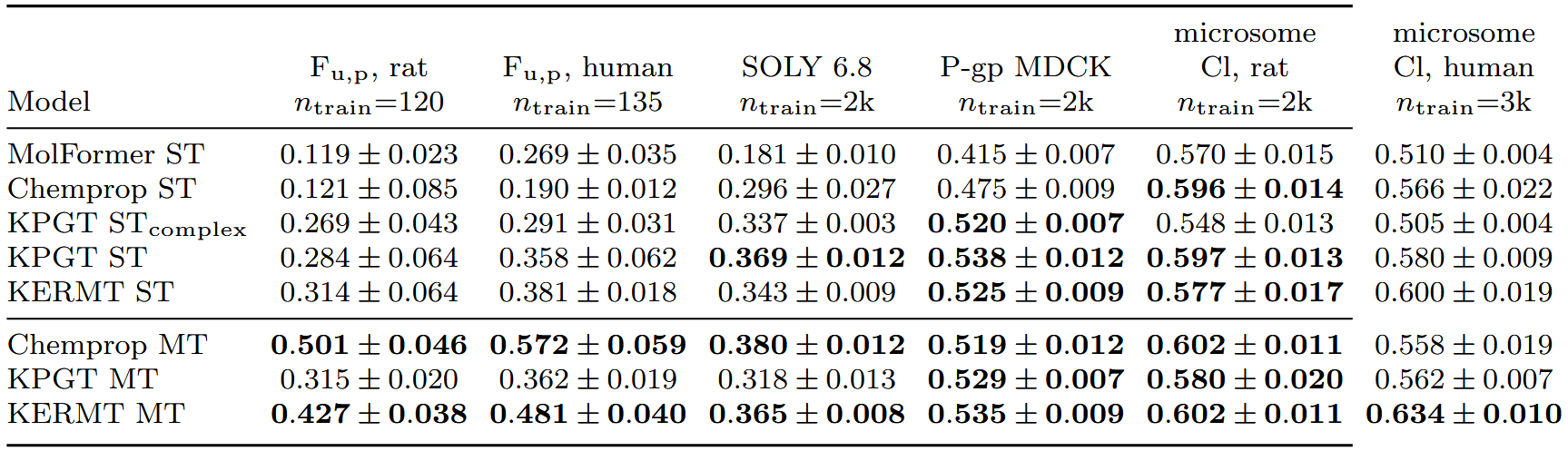
在三个ADMET数据集、六个单任务靶点结合效力数据集以及一个单任务激酶靶点结合效力数据集上对模型进行了测试。ADMET数据集包括来自默沙东公司的内部数据、公共数据集、公共Biogen数据集。所有ADMET数据集都是稀疏的,每个终点包含的数据量不同。从这些数据集中选择了五到六个不同的终点对单任务方法进行基准测试,随后对性能最佳的模型在所有可用终点上比较了多任务方法。靶点结合效力数据集包括来自默沙东公司的两个未公开靶点(靶点1和靶点2)的内部EC50和IC50数据,以及来自BindingDB和两篇文献的公共IC50数据集。与ADMET数据集相比,效力数据集的数据点较少。多任务激酶数据集包含跨越十个激酶终点(ABL1, BRAF, EGFR, ERBB2, KDR, MAPK14, NTRK1, PIK3Ca, PIK3Cg, and RAF1)的26577个化合物。
在内部数据上按照时间80-20划分对每种方法进行基准测试,结果如表1所示。在采用标准单任务微调的预训练模型中,使用简单微调的KERMT和KPGT模型在内部数据上表现更好。这凸显了在分子性质预测中保留图结构的重要性。此外,简单微调的KPGT模型始终优于复杂微调模型。此外,当KERMT使用多任务前馈网络进行训练时,它在所有基准测试方法中所有测定上表现最佳或并列最佳。
表1 内部ADMET数据基准测试
在内部数据集上,每种方法采用多任务训练所带来的性能提升如图2a所示。图2b展示了预训练多任务模型相对于Chemprop多任务模型,在内部所有测定的时间划分上的性能提升。综合考虑多任务设置下所有30个内部ADMET终点的整体表现,KERMT多任务模型仍然是最佳模型。
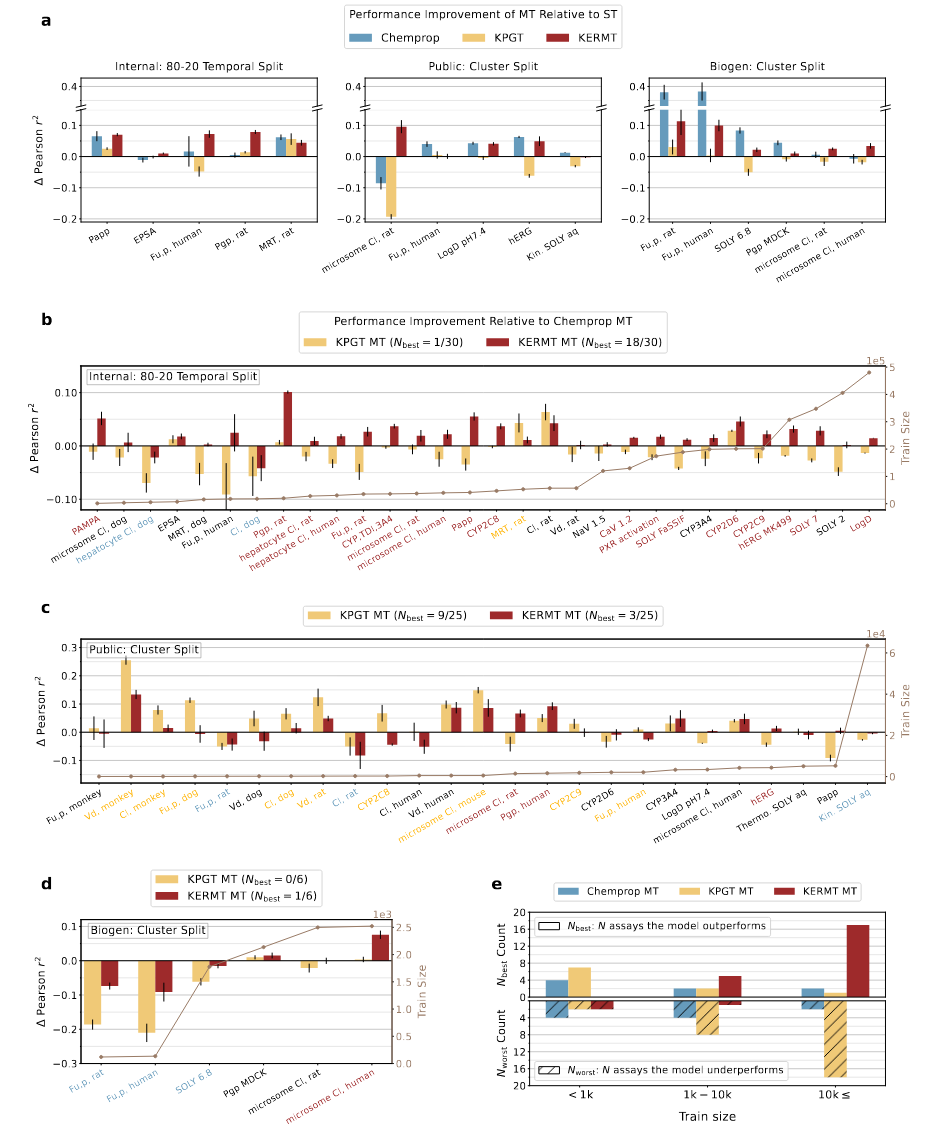
图2 模型在ADMET测定预测中的性能对比
在公共ADMET数据集上对每个模型进行了基准测试。在公共聚类划分上进行基准测试时, KPGT单任务模型在3/5的任务中表现最佳(表2)。在公共聚类划分的所有25项测定上与其他多任务方法进行基准测试时,KPGT同样表现最佳(图2c)。在Biogen数据集上,除了在人肝微粒体清除率测定中KERMT多任务模型表现更好外,两个预训练模型相对于Chemprop多任务模型均表现不佳。图2e展示了在三个ADMET数据集中,针对三种数据范围小规模、中等规模和大规模,表现最佳和最差的多任务模型。总的来说,KERMT在两个公共ADMET数据集中均通过多任务学习持续获得改进,尽管与内部时间划分相比提升幅度较小。
表2 公共ADMET数据基准测试
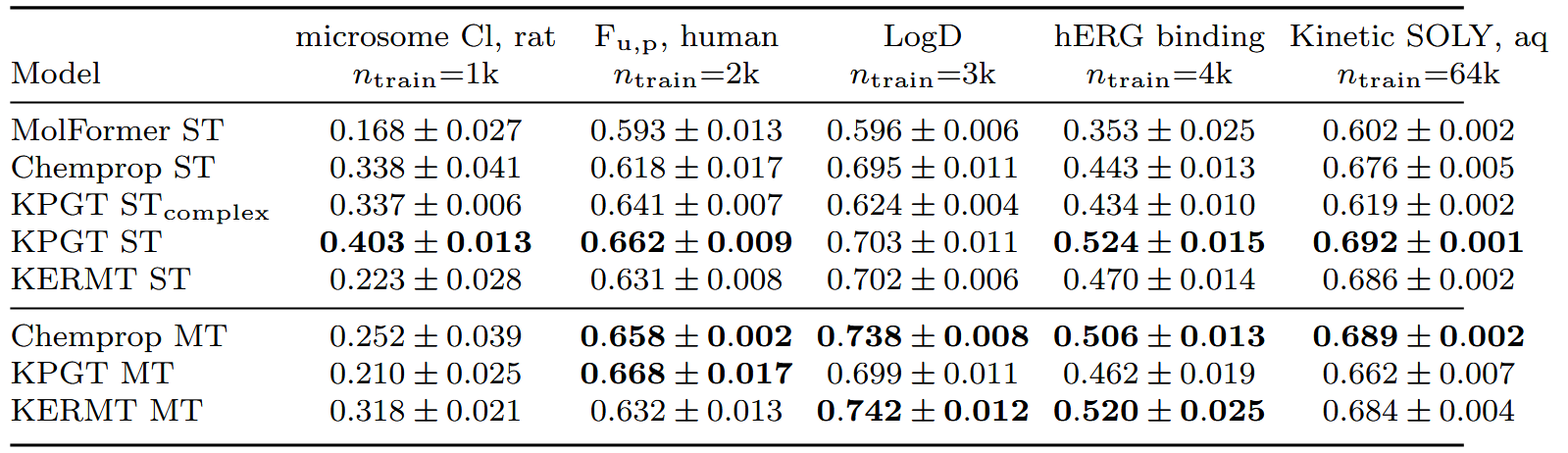
表3 Biogen ADMET数据基准测试
在对应于不同靶点的六个靶点结合效力数据集上对每个单任务模型进行了基准测试。靶点1和EGFRbdb效力预测的拟合图和分类条形图如图3所示。KPGT正确分类了更多高效力分子,在两个较大的EC50区间中被错误分类的高效力分子比例较低(图3b)。所有模型正确分类的高效力分子数量大致相同,KERMT的错误分类更少(图3c),因此在识别效力分子方面富集效果更好。
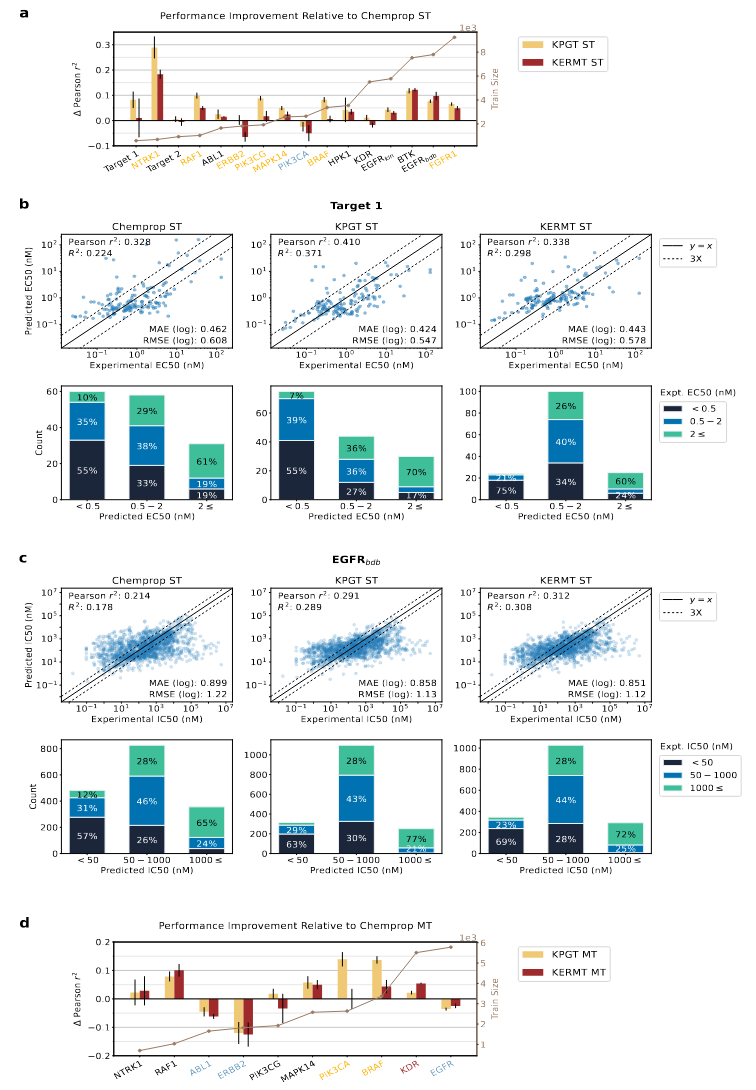
图3 模型在靶点结合效力预测中的性能
模型扩展性研究
通过改变多任务设置中用于微调模型的完整化学空间规模研究KERMT的扩展性。结果表明KERMT通常在更大的完整数据规模下表现更好(图4a,4b)。当下游完整数据规模大于6万个数据点时,KERMT的性能显著优越。当数据规模小于6万时,两个模型的性能相对接近,KERMT略微优于Chemprop。
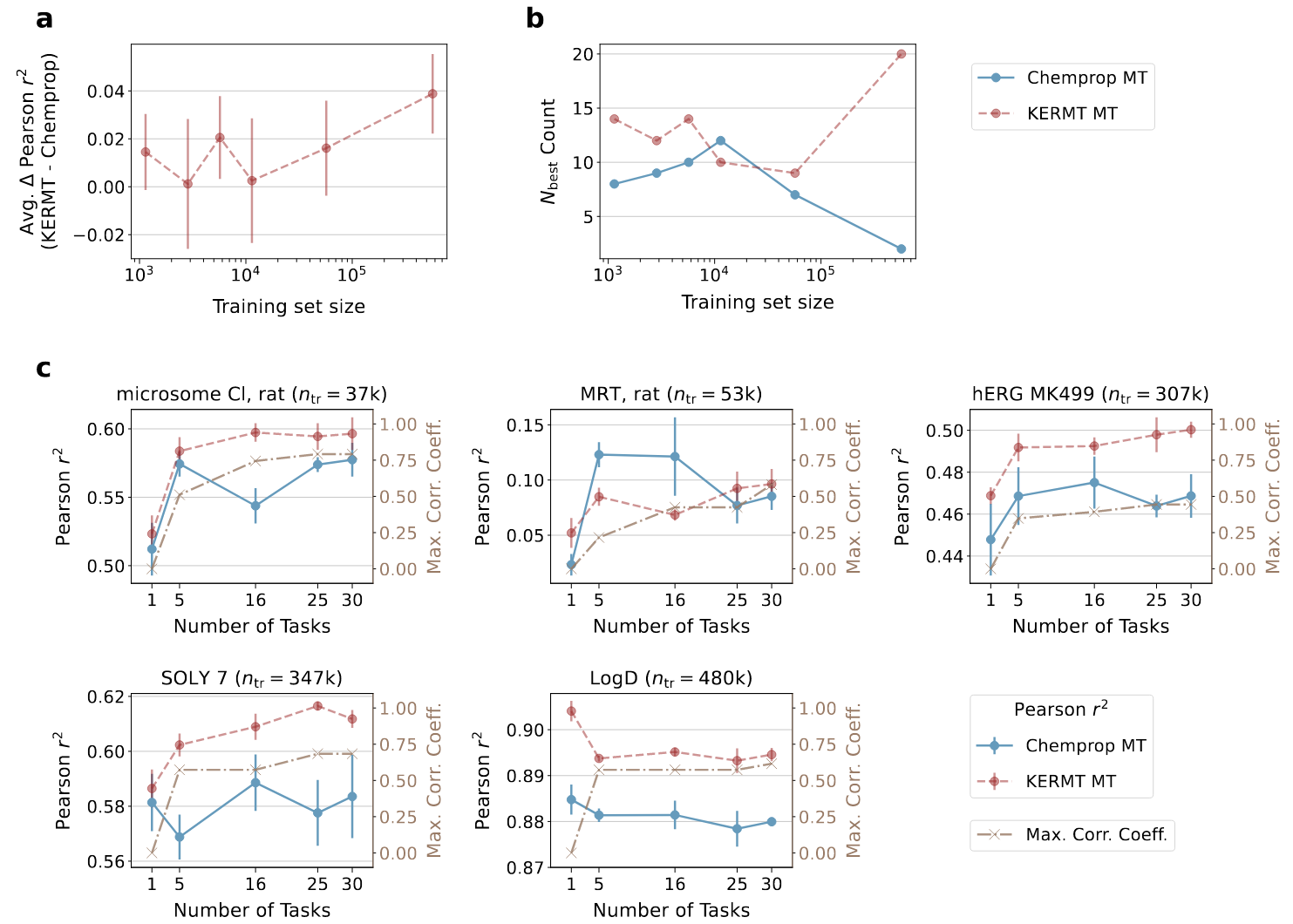
图4 训练集规模或任务数量变化的扩展性结果
此外,研究了在多任务模型中扩展任务数量如何影响KERMT和Chemprop多任务模型的性能(图4c)。增加KERMT中的任务数量时,性能略有提升,而Chemprop的性能通常保持不变或略有下降。分析表明数据量的增加和跨任务相关性都对KERMT的性能提升有影响。
化学空间泛化能力
根据测试集与训练集的最大分子Tanimoto相似度对测试集进行分组,比较了KERMT和Chemprop多任务模型在这些子集上的性能(图5a)。两个模型的Pearson r²通常都随着Tanimoto相似度的增加而提高。此外,在所有Tanimoto区间内,KERMT的表现始终优于Chemprop(图5b-c)。尽管KERMT并非对低相似度化合物有特别的优势,但它在整个测试的化学空间中是泛化能力更强的模型,并对所有相似度区间都有改进。
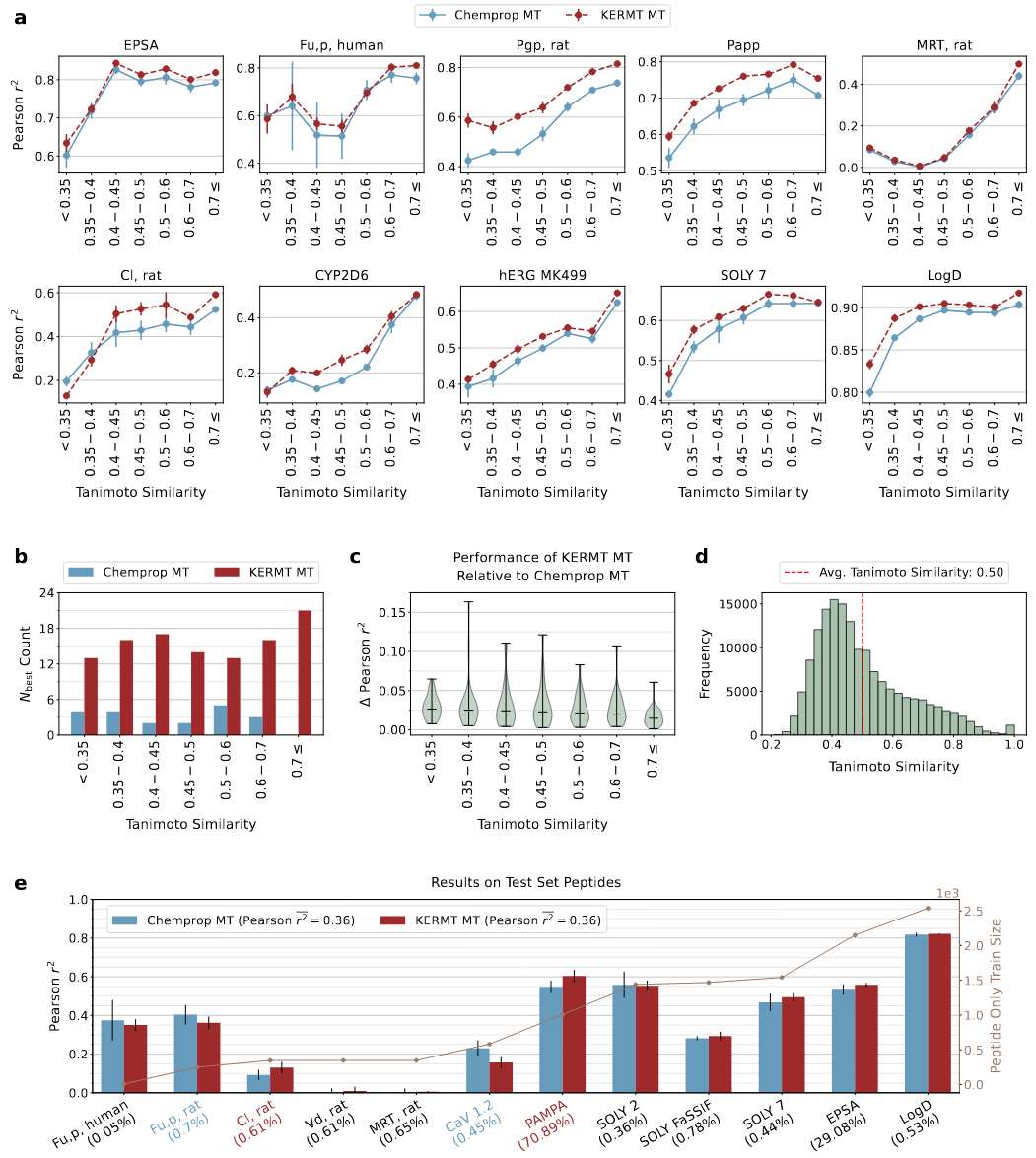
图5 在不同Tanimoto相似度区间的性能
在更相似的数据上进行预训练
使用来自下游微调任务的完整约80万个分子预训练一个KERMT模型,以确定在更相似的数据上进行预训练是否会影响下游性能。结果表明,即使内部预训练模型包含了下游任务中出现的化学片段,就平均Pearson r²而言,它对所有化合物和环肽子集的下游性能并没有显著影响(图6)。相对于内部预训练集,基础KERMT模型对环肽这类药物形式的代表性要少得多,但基础KERMT模型在5/12的任务上优于内部预训练模型,而内部预训练模型仅在1/12的任务上优于基础模型。共同确定预训练数据集的最佳数据规模和分子选择方案至关重要。
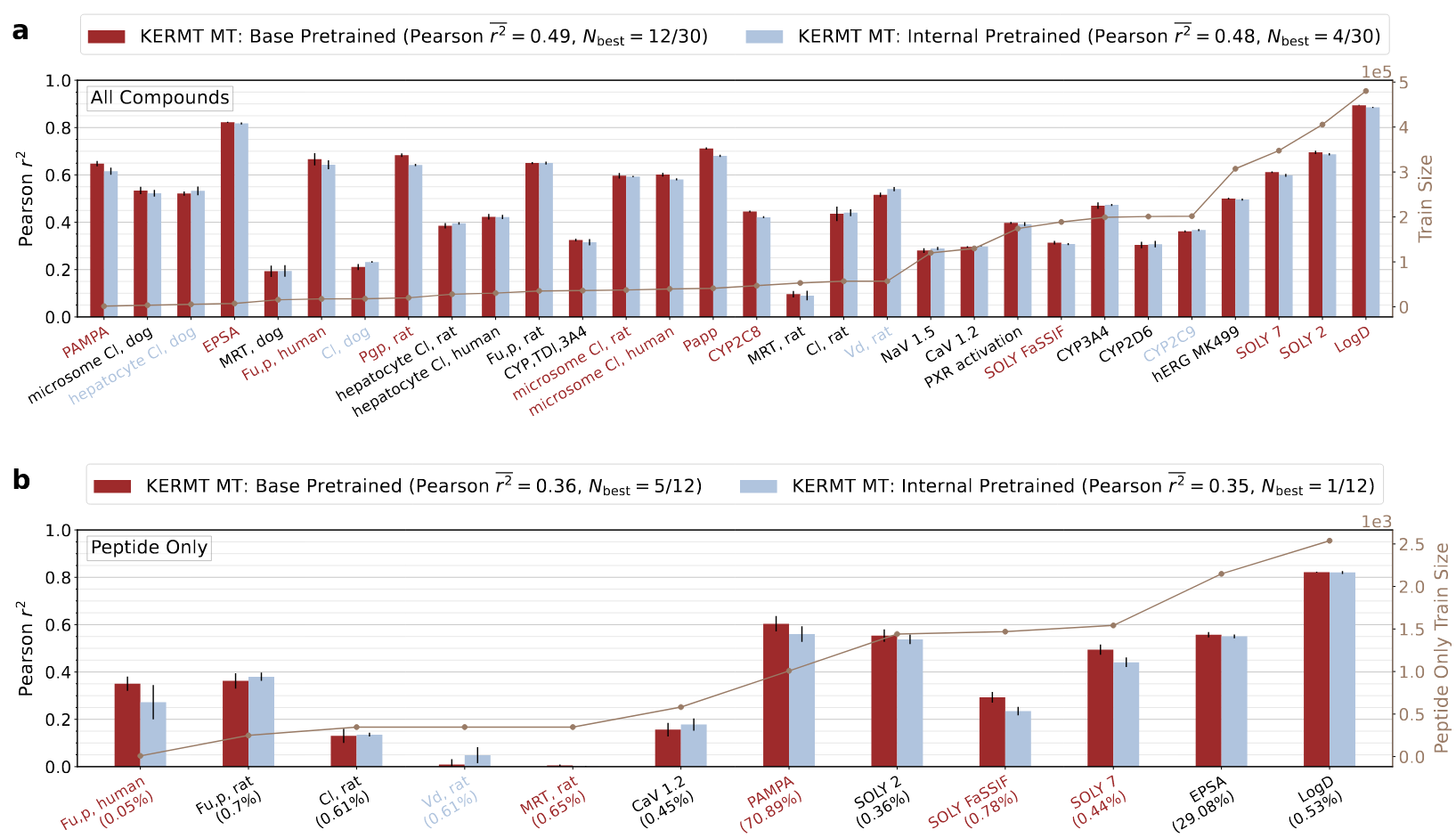
图6 基于已发表KERMT基础模型与基于内部化合物数据预训练的KERMT模型在下游任务中的性能对比。
模型并行与加速
为了加速预训练,使用PyTorch的分布式数据并行策略在多个GPU上并行化预训练,利用一个C++/Python包cuik-molmaker加速图神经网络中分子图的特征化。图7显示了在单个节点上扩展到多个GPU的预训练并行效率。分布式预训练实现的并行效率非常高,在两个GPU上实现了1.8倍的加速,相当于90%的扩展效率。当扩展到八个GPU时,扩展效率仅略微下降至86%,表明在预训练期间非常有效地利用了所有八个GPU。
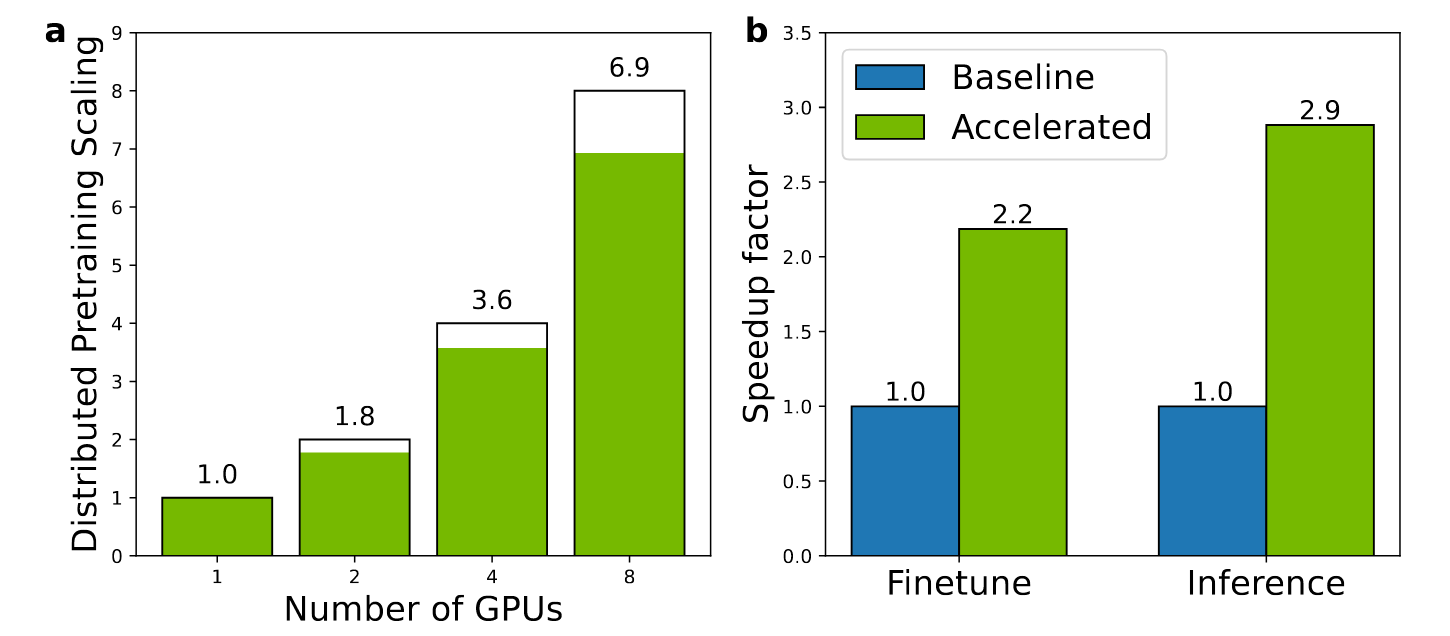
图7 KERMT模型的并行化与加速
总结
本研究提出在化学预训练模型的微调中利用多任务学习的优势。作者实现了GROVER和KPGT的多任务版本并介绍了KERMT,重新实现并增强加速特性的GROVER改进版本。多任务学习显著提升了KERMT相对于其单任务变体以及其他预训练和非预训练化学性质预测模型的性能。此外,基于实验结果,建议在中等至大数据规模下使用KERMT多任务模型,在小数据规模下使用KPGT单任务模型进行ADMET性质预测。
作者计划进一步研究更先进的算法、归纳偏置和数据整理策略用于预训练任务,这可能进一步有益于其他药物形式(如肽)的下游性能。此外,应进行更深入的消融研究,以更严格地确定各种预训练任务与多任务带来的性能变化之间的相关性。最后,希望进一步研究编码器的参数量和部分冻结如何影响小规模和大规模数据下的下游性能。
参考链接:https://doi.org/10.1016/j.fmre.2024.11.027
文章改编转载自微信公众号:智药邦
原文链接:https://mp.weixin.qq.com/s/XAbwGigKxK0grS0RB7sxyQ | 





















