|
近日,浙江大学侯廷军、康玉教授团队联合澳门理工大学刘焕香教授团队发表在Nature Communications的研究论文,题为LaMGen: LLM-Based 3D Molecular Generation for Multi-Target Drug Design,该研究提出了基于大语言模型的多靶点药物设计通用3D分子生成框架LaMGen,打破了现有方法泛化性不足、精度与效率难以兼顾的核心瓶颈,仅通过输入靶蛋白氨基酸序列即可直接生成量子化学精度的3D活性分子,在双靶点、三靶点药物设计场景中均展现出优越性能,为复杂疾病的多靶点药物研发提供了全新的基础计算工具。
研究背景
靶向药设计是现代药物研发的核心任务,而单靶点药物设计策略在复杂多因素疾病治疗中始终面临耐药性、副作用大、疗效有限等核心问题。与之相对,多靶点药物设计可通过同时调控疾病多个相关靶点产生明确的选择或协同药理效应,是攻克癌症、神经退行性疾病等复杂疾病的关键方向。但多靶点药物设计要求候选分子同时满足多个结合口袋的结构约束,还要保持优异的类药与成药性质,对计算方法提出了极高的要求。
近年来,深度学习分子生成模型在单靶点药物设计中取得了长足进步,但向多靶点场景拓展时仍面临三大核心局限:绝大多数方法为基于配体的方法,高度依赖特定靶点对的活性数据,对缺乏已知参考分子的靶点组合泛化性极差;部分方法通过强化学习引入靶点信息,却难以平衡靶点特异性奖励与化学多样性,过度优化极易导致骨架利用狭窄;基于扩散架构的通用框架计算密集、生成效率极低,在复杂场景下的生成质量与可控性显著下降,难以拓展至三靶点等更复杂的多靶点场景。近期,大语言模型(LLM)在计算药物研发领域展现出巨大潜力,但现有相关模型普遍缺乏对分子3D 信息的理解,在多靶点药物生成领域的应用几乎处于空白。应对上述行业痛点,研究团队开发了LaMGen框架,首次实现了基于LLM的通用型多靶点3D分子生成。
方法概述
为打破多靶点分子生成中精度、泛化性与效率的三重壁垒,研究团队构建了全流程的 LaMGen框架,核心创新分为数据集构建、模型架构设计与训练策略三大模块。
1.大规模多靶点专属数据集MTD2025构建
针对多靶点药物设计领域高质量数据匮乏的核心问题,研究团队基于Papyrus生物活性数据库,整合ChEMBL、ExCAPE-DB等权威来源的实验活性数据,经过系统过滤、配对与重构,构建了MTD2025数据集。该数据集包含4011个唯一蛋白、123024个唯一小分子,配套超60万个量子力学精度的3D分子构象,以及44.6万条双靶点、28.3万条三靶点关联数据。所有分子均通过CREST完成构象搜索,再经量子力学精度的LiTEN-FF力场优化得到局域最低能量构象,确保了数据集的结构质量与物理合理性,为模型训练提供了高质量的数据基础。
2.LaMGen核心架构设计
LaMGen基于Transformer解码器架构构建,整体分为配体预训练、多靶点微调、序列驱动分子生成三大核心阶段,核心创新点如下:3D旋转感知离散token编码:将配体扭转角等内部自由度编码为离散的3D旋转感知token,相比原始笛卡尔坐标,大幅缩短了序列长度,保证了旋转不变性,同时显著降低了计算复杂度,让LLM可直接学习分子SMILES序列与3D构象空间的精准映射。ESM-C蛋白序列编码:摒弃对蛋白 3D结构的依赖,仅以氨基酸序列为输入,通过预训练蛋白大模型ESM-C进行编码,得到能有效捕捉蛋白结构与功能特征的嵌入表示,大幅降低了模型对结构数据的依赖,同时借助大规模序列数据库提升了模型的泛化能力。TriCoupleAttention模块:创新性地在统一的自注意力框架内,联合建模靶点-靶点、配体-靶点、配体-配体间的自注意力与交叉注意力,通过加权融合机制自适应平衡双靶点对配体的影响,实现了对多靶点结合模式的细粒度、全维度建模,完美适配多靶点场景的复杂相互作用捕捉。
3.两阶段训练策略
模型先在GEOM数据集的800万+高质量分子构象上完成预训练,学习分子SMILES 与扭转构象的基础映射关系;再在MTD2025数据集上完成多靶点适配微调,让模型具备基于蛋白序列生成多靶点活性分子的能力。同时,训练过程中引入随机因果掩码策略,显著提升了模型的鲁棒性与泛化性。
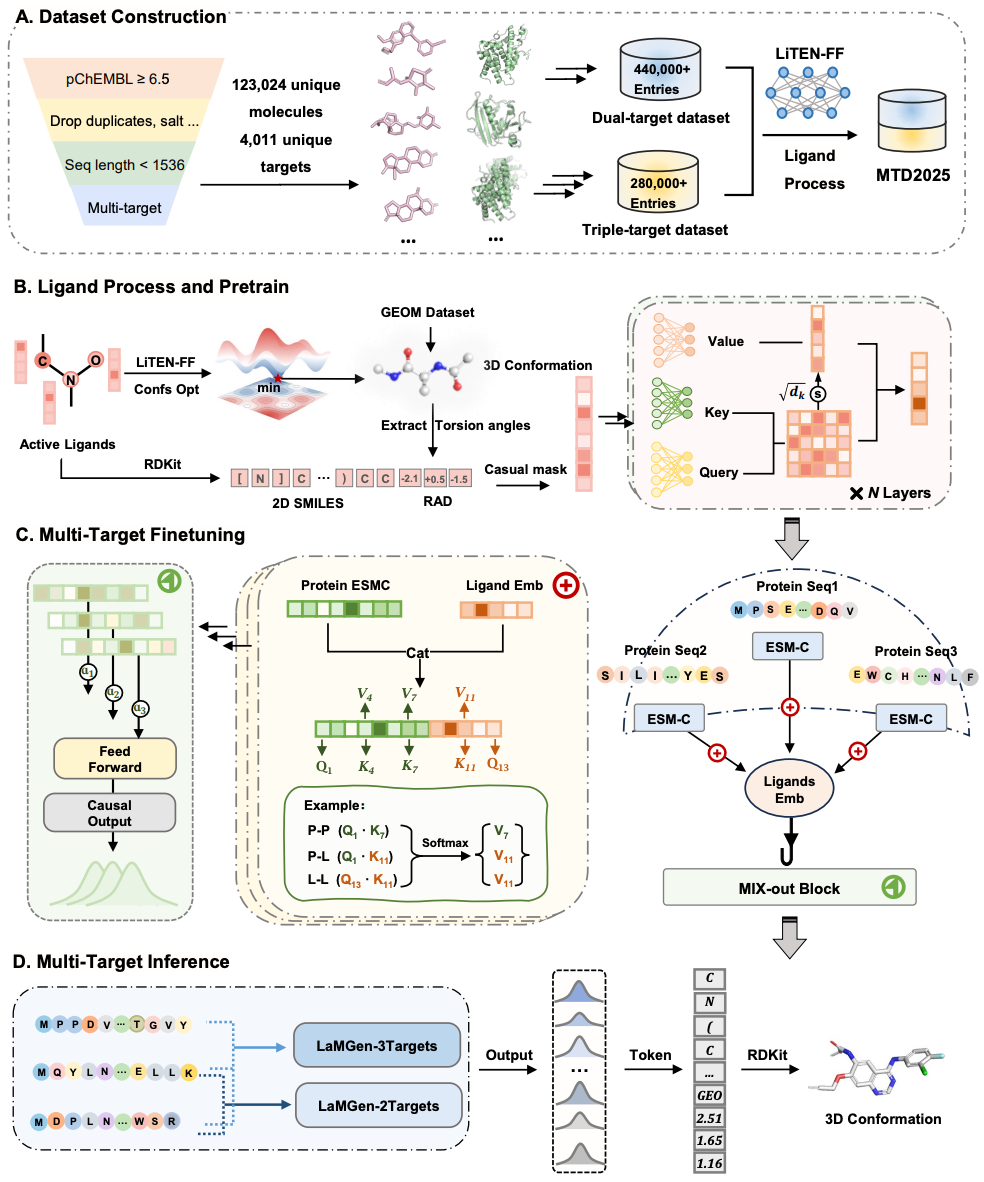
图1.LaMGen框架示意图
结果与讨论
研究团队通过多维度、多场景的系统实验,全面验证了LaMGen的性能优势与实际应用价值。
1.跨序列相似度靶点的零样本高亲和力分子生成
研究团队构建了两组独立测试集,分别对应全低序列相似度(<0.4)的完全分布外靶点对,以及“低+高”序列相似度的混合靶点对,全面评估模型的泛化能力。在外部测试集上,LaMGen在17/20个靶点对上的结合亲和力优于主流开源双靶点生成模型DualDiff,同时在类药性(QED)、合成可及性(SAScore)上展现出更优异的表现;单分子生成平均仅需0.44秒,较DualDiff(12.3秒/分子)提速超30倍,可适配高通量筛选场景。在混合测试集上,LaMGen生成分子的有效率达95%,内部结构多样性达0.89,与训练集平均相似度仅0.11,在保证结构创新性的同时,关键类药性质均完全符合成药区间,双靶点平均结合亲和力达-9.0与-8.7kcal/mol,展现出优越的分布外泛化能力。
2.量子化学精度构象的直接生成能力
针对分子构象生成这一下游应用的核心环节,研究团队开展了系统的构象保真度验证。结果显示,LaMGen生成的构象与LiTEN-FF优化结构的平均RMSD仅为0.5 Å,超98%的构象RMSD低于2Å,构象质量全面优于DualDiff;其生成构象的对接得分与LiTEN-FF优化构象高度一致,显著优于MMFF94力场优化构象,PoseBusters综合通过率达92%,远超DualDiff的68%。这意味着LaMGen可直接生成无需额外力场优化、即可用于下游对接与性质预测的物理合理3D结构,有效简化了药物研发的计算流程,降低了计算开销。
3.JNK3/GSK3β双靶点设计的零样本泛化与微调潜力
研究团队以神经退行性疾病领域经典的JNK3/GSK3β双靶点设计为案例,验证模型的实际应用能力。在零样本场景下,仅输入两个靶点的氨基酸序列,LaMGen生成的分子有效率达94.2%,多样性达0.863,45%以上的分子对接得分超过已知活性分子的平均水平,综合性能与AIxFuse等SOTA模型相当甚至更优。经过少量样本微调后,LaMGen-FT的双靶点对接达标率提升至33.01%,超越AIxFuse(31.80%),多性质综合成药成功率同样显著优于AIxFuse(8.46% vs5.40%),同时保持了更高的分子多样性,展现出优秀的迁移学习能力与靶点适配性。
4.真实场景双/三靶点任务的回溯性验证
研究团队进一步在癌症治疗相关的3组经典双靶点体系(EGFR/HER2、PI3K/mTOR、LSD1/HDAC6),以及EGFR/HER2/VEGFR三靶点体系中开展回顾性验证。结果显示:在双靶点体系中,LaMGen可精准复现与已知活性分子结构完全一致的化合物,同时能自主生成保留核心药效团、结合亲和力更优的骨架类似物,实现了药效团重构与骨架跃迁的双重能力;在三靶点体系中,LaMGen依然保持了优异的生成性能,生成分子在三个靶点上均集中于高亲和力区间,可自适应调整分子复杂度以满足第三个靶点的结合约束,同时保持核心类药性质稳定,首次实现了基于 LLM的三靶点3D分子生成。
总结
LaMGen为多靶点3D分子生成提供了基于大语言模型的新型技术路径。该框架能够直接从目标蛋白氨基酸序列出发,快速生成兼具量子力学构象精度、高多靶点亲和力且满足成药性指标的3D活性分子,有效平衡了模型泛化性、计算精度与运行效率。作为面向多靶点药物设计的LLM基础生成框架,LaMGen在零样本场景下表现出可靠的泛化能力,能够适配功能协同靶点等多种复杂设计需求。随着与蛋白结构及性质预测模型的深度融合,LaMGen有望为AI驱动多靶点药物研发提供有力工具,在针对复杂疾病的多靶点药物开发中发挥作用。
共同第一作者为浙江大学博士生苏群、澳门理工大学博士生苟巧林。
原文链接:https://www.nature.com/articles/s41467-026-71737-w
本文转自【BioArt】公众号
文章改编转载自微信公众号:智药邦
原文链接:https://mp.weixin.qq.com/s/t0O07SGkD4pJ8iyP-w9eeA | 





















