|

研究背景与科学问题
分子构象——即原子在三维空间中的精确排列——深刻影响着分子的反应性、稳定性及分子间相互作用等核心化学性质。随着分子尺寸增大,可及构象数量呈指数级增长,穷举式构象空间探索面临严峻的计算挑战。然而,理解构象分布对于药物设计、催化剂开发和生物科学等领域至关重要。
传统构象生成方法主要分为两类:基于物理的方法(如分子动力学、元动力学)精度较高但计算代价昂贵;基于启发式规则的方法(如RDKit)计算效率高但精度有限,常遗漏关键构象。近年来,扩散模型作为强大的生成范式,在分子构象生成中展现出潜力,但现有方法仍存在架构复杂、缺乏化学知识嵌入、依赖大分子训练数据等瓶颈。特别是,纯数据驱动模型常生成非物理或能量不合理的结构,且大分子高质量数据集的构建本身即为难题。
StoL框架:类LEGO式的模块化构象生成
针对上述挑战,华南师范大学兰峥岗教授团队研究提出了StoL(Small-to-Large)框架——一种端到端的化学增强扩散模型方法,核心理念是仅利用小分子数据训练模型,即可生成大分子的多样化高质量构象。该框架无需在训练阶段见过目标大分子或任何同等规模的结构,从根本上规避了大分子数据匮乏的限制。
StoL以SMILES字符串为输入,直接输出多种构象的笛卡尔坐标,采用类似LEGO积木的模块化设计,包含三个核心阶段:
(1)分子片段化。 输入SMILES被系统性地拆解为若干较小的化学有效片段。算法识别分子图中的非环单键进行裂解,保留含6—10个重原子的片段,并采用"最大片段优先"的树遍历策略选择片段组合。相邻片段至少共享三个重原子以保证结构连贯性,所有片段组合后须能完整重构原始分子。 (2)片段构象生成。 每个片段的SMILES被转化为分子图,由化学增强扩散模型生成多种合理的三维构象。该模型采用两阶段训练策略:先进行纯数据驱动的预训练,再进入化学增强阶段,引入Sinkhorn算法和Gumbel-softmax技术进行原子匹配与排列优化,同时加入环系平面性检查等化学约束。这些化学先验知识的嵌入显著加速了训练收敛并提升了生成质量。 (3)全局组装与验证。 过滤后的三维片段被组装为完整分子结构,并经化学信息学约束验证结构完整性与热力学合理性,最终输出多样化的构象集合。
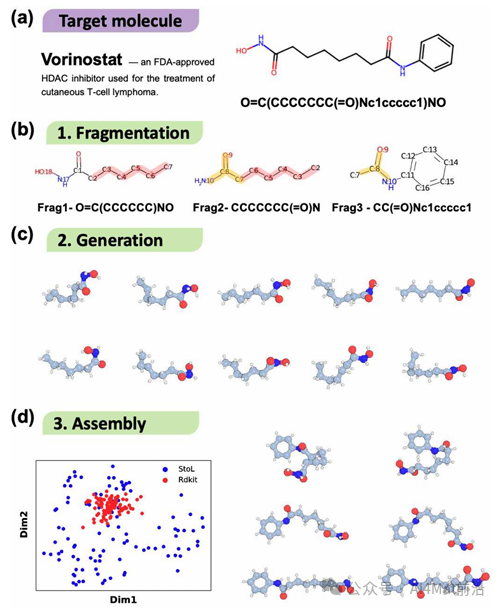
▲ Fig.1 | StoL流程应用于伏立诺他(vorinostat)的示例说明。(a) 伏立诺他的SMILES表示及其分子结构。(b) 分子的片段化处理及对应的片段SMILES。(c) 对片段1进行降维处理后,通过聚类技术获得10种代表性构象。(d) 伏立诺他的最终组装。左图展示了由StoL和RDKit生成的分子结构的PCA可视化结果,右图展示了六种代表性三维结构。
图1以抗癌药物伏立诺他(vorinostat)为例,展示了StoL的完整流程:从SMILES输入到分子片段化、片段构象降维聚类,再到最终组装。右侧的PCA可视化表明,StoL生成的构象在构象空间中的覆盖范围明显优于传统RDKit方法,能够探索到更广泛的构象区域。
化学增强策略的关键作用
StoL的核心创新在于将化学原理系统性地嵌入扩散模型的多个环节。在训练阶段,化学增强(CE)策略解决了分子生成中的原子排列不确定性问题:由于同类原子间的排列是不确定的,模型需要学习正确的原子-坐标对应关系。StoL引入Sinkhorn算法求解最优排列矩阵,并结合Gumbel-softmax实现可微分的离散采样,使排列学习融入端到端训练。此外,环系平面性约束确保芳香环等结构生成时保持正确的几何特征。
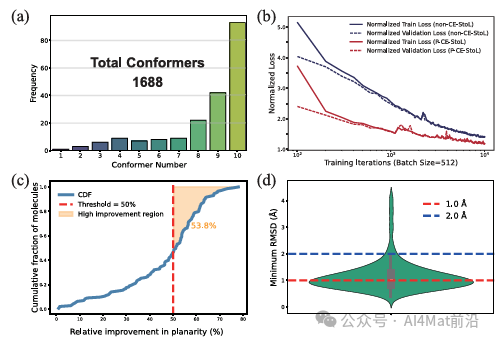
▲ Fig.3 | (a) StoL25-init数据集中的构象异构体分布。每个结构均通过对10个RDKit生成的初始构型进行DFT优化获得。(b) P-CE-StoL模型与non-CE-StoL模型的训练损失曲线比较。红色线条对应P-CE-StoL的训练损失和验证损失,蓝色线条对应non-CE-StoL的训练损失和验证损失,横轴为训练迭代次数。纵轴为归一化损失,定义为 /t T,其中T表示各策略最终收敛的损失值。
图3(b)清晰展示了化学增强策略的效果:与非增强模型(non-CE-StoL)相比,化学增强模型(P-CE-StoL)的训练损失收敛速度显著加快,最终损失值也更低,验证了化学知识嵌入对模型训练效率和性能的实质性提升。图3(c)进一步通过片段生成质量的对比,表明化学增强策略生成的构象在键长、键角等几何参数上更加合理。
DFT验证与性能评估
为严格评估StoL的生成质量,研究者对生成构象进行了密度泛函理论(DFT)级别的几何优化与能量验证。
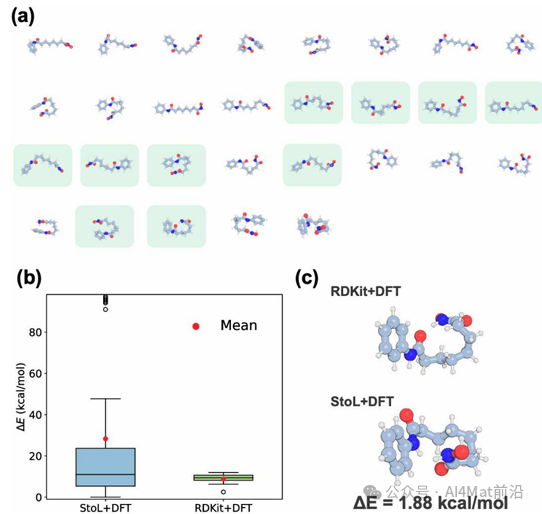
▲ Fig.2 | 伏立诺他构象的DFT评估。(a) 基于StoL生成的初始构型,经DFT计算得到的29种代表性构象,按能量降序排列。浅绿色标记表示同时由RDKit和StoL初始构型获得的结构。(b) 以最低能量结构为参考的相对能量(ΔE)箱线图,比较了由RDKit+DFT(StoL25-init数据集)和StoL+DFT(基于StoL生成的初始构型进行DFT计算)所生成的构象异构体。
图2以伏立诺他为例展示了DFT验证结果。StoL生成的初始猜测经DFT优化后获得了29种代表性构象,其中包含RDKit无法找到的独特低能构象。能量箱线图显示,StoL+DFT工作流产生的构象能量分布整体低于RDKit+DFT,表明StoL能够更有效地探索低能构象空间。
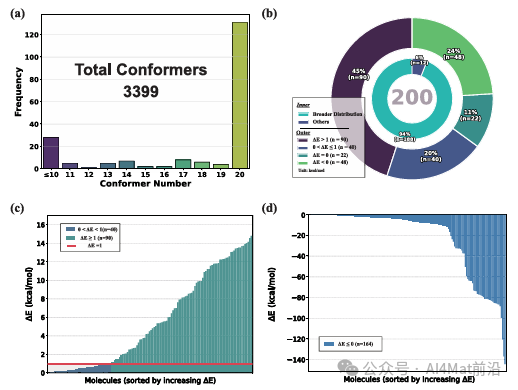
▲ Fig.4 | (a) 使用20种StoL生成的代表性初始结构经DFT优化后的构象异构体分布。(b) 环形图展示了200个分子中,由RDKit和StoL初始化的DFT工作流所获得的最低能量构象异构体之间的能量差(ΔEmin = ERDKit+DFT min − EStoL+DFT min,单位:kcal/mol)。(c) 柱状图展示了StoL+DFT工作流产生更低能量构象异构体的分子的ΔEmin值,按能量差升序排列(单位:kcal/mol)。
图4将评估扩展至200个分子的系统性测试。图4(a)展示了StoL生成的20个代表性初始结构经DFT优化后的构象分布情况。图4(b)的环形图给出了关键统计结果:在200个测试分子中,StoL+DFT工作流在相当比例的分子上找到了比RDKit+DFT更低能量的构象。图4(c)和(d)分别展示了两种方法各自占优的分子及其能量差异。这些结果表明,StoL作为构象搜索的初始猜测生成器,能够有效补充甚至超越传统启发式方法,尤其在柔性大分子的低能构象发现方面具有显著优势。
总结与展望
StoL框架的主要创新贡献可归纳为以下几点:第一,提出了"小分子训练、大分子生成"的片段化策略,从根本上解决了大分子训练数据匮乏的问题,具有出色的可扩展性和可迁移性;第二,系统性地将化学先验知识嵌入扩散模型的训练和推理过程,显著提升了模型效率和生成质量;第三,端到端的黑箱设计使框架无需专家干预即可使用,降低了应用门槛。
该研究也存在一定局限性:当前片段约束为6—10个重原子,对于含有更大刚性子结构的分子可能需要调整;此外,片段间柔性连接区域的构象采样完整性仍有提升空间。未来方向可包括扩展训练数据的化学多样性、引入更精细的片段间相互作用建模,以及与增强采样方法的联合使用。
该工作深刻揭示了一个重要启示:在分子生成领域,将基础化学原理与机器学习模型深度融合,远比单纯增加数据规模或模型复杂度更为有效。这一思路对物理信息增强的分子生成研究具有广泛的借鉴意义。
结合,以提升框架在更复杂设计场景中的适用性。
参考文献:Yifei Zhu, Jiahui Zhang, Jiawei Peng, Mengge Li, Chao Xu, and Zhenggang Lan. The Journal of Physical Chemistry Letters (2026) https://doi.org/10.1021/acs.jpclett.5c04019
文章改编转载自微信公众号:AI4Mat前沿
原文链接:https://mp.weixin.qq.com/s/MQ9L5_SfIsThlFWtGKKQqw | 





















