本文解读《International Journal of Molecular Sciences 2025》最新研究成果ICVAE(Interpretable Conditional Variational Autoencoder),一种面向从头分子设计的可解释条件变分自编码器。传统生成模型的隐空间高度纠缠、难以理解,导致分子生成如同 “黑箱操作”,无法精准控制与解释。ICVAE 通过改进损失函数,在隐变量与分子性质之间建立严格线性映射关系,实现隐空间语义可解释、分子属性可精准调控、生成过程可直观理解。模型可单独或同时控制分子量、logP、氢键供体 / 受体、拓扑极性表面积等关键成药性质,在有效性、新颖性、多样性等指标上超越 VAE 与 CVAE,为小分子药物研发、靶向抑制剂设计、多目标分子优化提供透明、可控、可信的 AI 新范式。

人工智能正在彻底改变新药研发的路径。利用深度学习生成模型从头设计分子(de novo molecular design),已经成为药物发现领域最具潜力的方向之一。研究人员不再依赖天然产物或已有化合物库的盲目筛选,而是让 AI 直接生成具有预期理化性质、药理活性、成药潜力的全新小分子。在众多生成模型中,条件变分自编码器(CVAE)凭借能够引入属性条件引导生成的优势,成为主流框架之一。然而,尽管 CVAE 能够根据指定性质生成分子,但其核心的隐空间(latent space)始终是一个难以解开的黑箱。
在传统 CVAE 中,隐向量与分子性质之间不存在明确的对应关系,隐空间高度纠缠、混乱无序。研究人员无法知道某一个隐向量对应何种分子属性,也无法通过简单调整隐坐标精准改变特定性质,更无法解释模型生成某一分子的内在逻辑。这种不可解释、不可控、不可调试的缺陷,严重限制了生成模型在真实药物研发中的落地应用。药化专家需要的不是一个只会 “吐分子” 的神秘工具,而是一个透明、可理解、可精细操控的设计助手。
为了从根本上解决这一问题,研究者提出了ICVAE:可解释条件变分自编码器。它在保留 CVAE 生成能力的基础上,通过创新的线性约束与损失函数重构,让隐变量与分子性质之间建立清晰、稳定、可预测的线性关系,真正实现 “调整一个隐维度,精准改变一项分子性质” 的可控分子生成。
一、传统 VAE 与 CVAE 的核心局限:隐空间不可解释的根源
在理解 ICVAE 之前,我们需要先明确传统变分自编码器的工作机制与局限。
1.1 变分自编码器(VAE)基础逻辑
VAE 由编码器与解码器组成:编码器将高维分子表示(如 SMILES 的 one-hot 向量)压缩为低维隐向量 z;解码器从隐向量 z 还原出分子。其训练目标是最大化证据下界(ELBO):
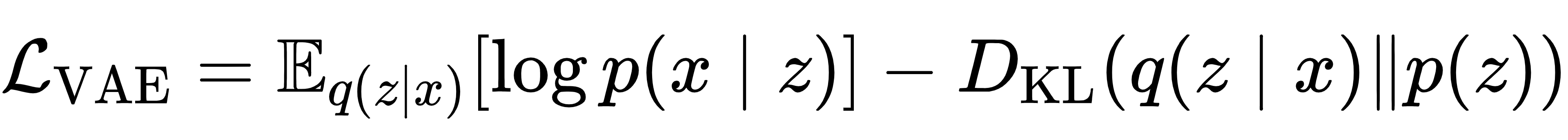
其中,第一项为重构误差,保证生成分子与输入相似;第二项为 KL 散度,约束隐空间服从标准正态分布。VAE 能够学习连续的隐空间,但无法引入性质条件,生成方向不可控。
1.2 条件变分自编码器(CVAE)的改进与不足
CVAE 在 VAE 基础上引入条件输入 c(如分子性质),实现条件引导生成,其目标函数为:
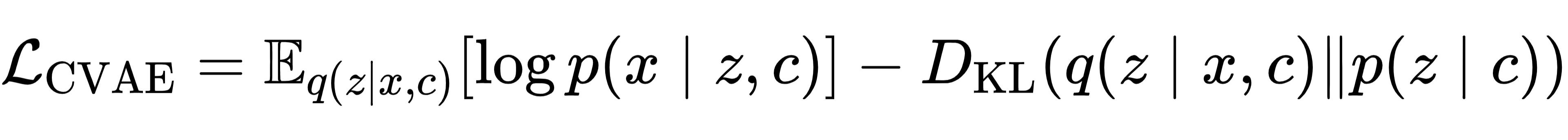
CVAE 可以按条件生成分子,但隐向量 z 与条件 c 之间无明确线性关系。隐空间仍然混乱,不同性质相互纠缠,无法解释、无法精准操控。
简单来说:VAE “生成不可控”,CVAE “可控但不可解释”。而 ICVAE 的目标,就是做到既可控、又可解释。
二、ICVAE 核心原理:强制线性映射,让隐空间具备物理语义
ICVAE 的核心创新,是在模型中引入隐变量与分子性质的线性关联约束,让每一个隐维度都对应明确的物理意义。
2.1 核心线性关系
ICVAE 强制建立如下线性映射:
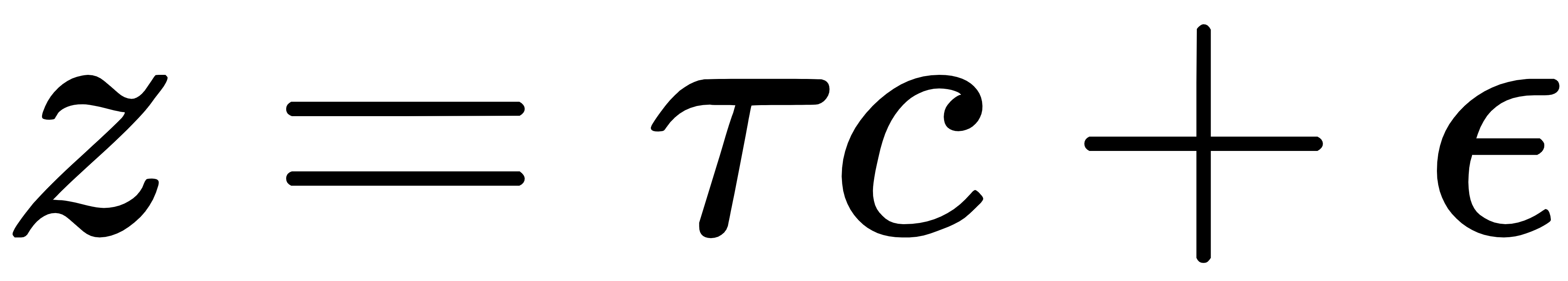
其中:z为隐向量;c为分子性质条件(如分子量、logP);τ为缩放系数,控制性质到隐空间的映射范围;ε为随机噪声,保证生成多样性。
这一公式意味着:隐向量 z 与分子性质 c 呈严格线性关系。性质数值越高,对应隐坐标越大;性质数值越低,对应隐坐标越小。调整隐坐标等价于直接调整分子性质,隐空间从此具备清晰的语义。
2.2 ICVAE 改进损失函数
为实现上述线性约束,研究者重新设计 ELBO 目标函数,将隐变量中心化处理,使其围绕条件 c 的线性预测值分布:
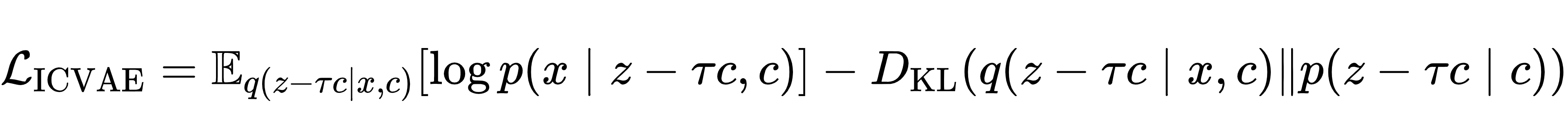
这一损失函数的关键在于:模型学习的是扣除线性趋势后的残差分布,从而在整体上保证 z 与 c 的线性关系。编码器输入分子与性质,解码器结合隐向量与性质还原分子,全程强化线性关联,最终得到一个可解释、可操控的隐空间。
2.3 ICVAE 整体架构
ICVAE 的架构与 CVAE 相似,但内部逻辑完全不同:
输入层:分子 SMILES one-hot 向量 + 分子性质条件;
编码器:卷积层 + 全连接层,输出隐变量分布,服从线性约束;
隐空间:z 与 c 严格线性对应,每个维度语义明确;
解码器:对称结构,从隐向量 + 条件生成分子 SMILES;
损失函数:线性约束 + 重构误差 + KL 散度,兼顾可解释性与生成质量。
这种设计让 ICVAE 突破黑箱,成为透明、可理解、可精准调控的生成模型。
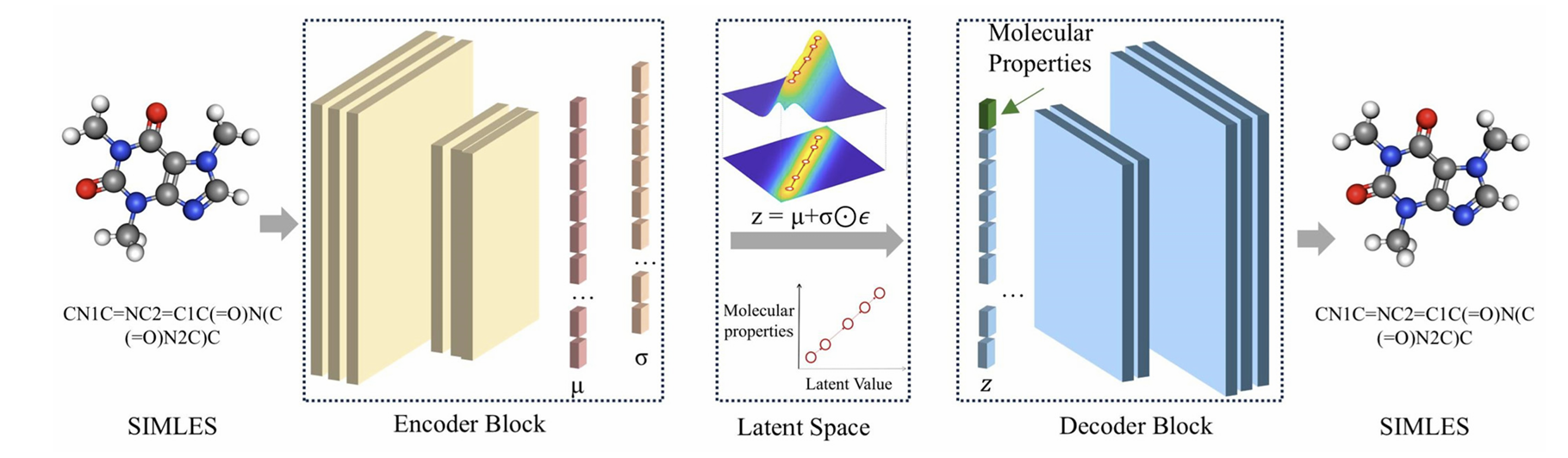
图1 ICVAE 整体模型架构图
三、模型训练流程与算法实现细节
ICVAE 的训练过程在标准深度学习框架下完成,整体流程分为数据预处理、模型构建、参数优化三个紧密衔接的阶段,每一步都为最终线性可解释的隐空间提供支撑。
3.1 数据集构建与预处理流程
研究选用公开的ZINC 化合物库作为训练数据源,从中随机抽取 50 万条分子记录,既保证数据规模充足,又避免冗余数据导致的过拟合。数据预处理阶段首先对 SMILES 字符串进行标准化清洗,统一长度至 120 个字符,并添加起始与终止符号标识分子边界,随后将字符转化为 33 类编码符号,最终转换为维度为 33×120 的独热编码矩阵,使其能够直接输入卷积神经网络。
与此同时,研究通过 RDKit 工具批量计算 7 项关键成药性质,包括分子量(MW)、脂水分配系数(logP)、氢键供体数量(HBD)、氢键受体数量(HBA)、拓扑极性表面积(TPSA)、可合成性评分(SAS)与药物相似性评分(QED)。这些性质会被归一化到统一数值范围,作为条件标签与分子编码配对输入模型,确保不同数量级的性质能够在隐空间中实现均衡的线性映射。
3.2 编码器与解码器网络结构设计
ICVAE 的编码器由三层卷积层与三层全连接层堆叠构成,卷积层通道数依次设置为 16、32、64,卷积核尺寸为 11×3,步长为 2,能够逐层提取 SMILES 序列中的局部化学结构特征。卷积输出的特征图会被展平为一维向量,经过全连接层映射后,输出 128 维隐变量的均值向量 μ 与标准差向量 σ。
模型采用重参数化技巧保证梯度可正常传播,其计算方法为:

其中 ϵ 服从标准正态分布,⊙为哈达玛积。解码器采用与编码器完全对称的结构,接收隐向量与条件标签作为输入,逐步上采样还原为原始维度的 SMILES 独热编码,实现分子结构的精准重构。
3.3 关键超参数选择与训练策略
研究通过对照实验确定最优超参数组合:隐空间维度 K 设置为 128,此时模型在表达能力与计算效率之间达到最佳平衡;缩放系数 τ 将条件标签映射至 [0, 500] 区间,使线性关系最为显著。模型采用自适应矩估计优化器,初始学习率设为 1×10⁻³,训练过程中根据验证集损失动态调整学习率,经过充分迭代收敛,确保隐空间与分子性质之间的线性约束稳定生效。
四、实验结果:可解释性、可控性与生成质量的全面验证
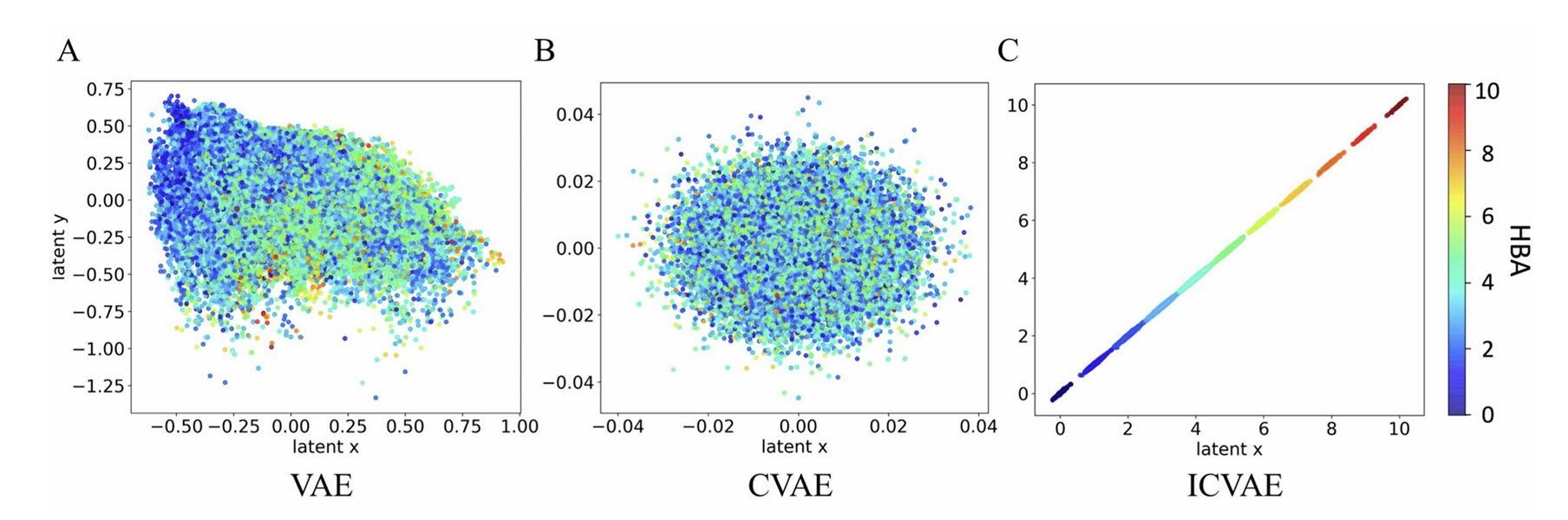
图2 VAE / CVAE / ICVAE 隐空间可解释性对比图
研究团队设计三组系统性实验,从隐空间可解释性、单属性与多属性可控性、生成分子质量三个维度,全面验证 ICVAE 的突破性性能,所有实验均在相同数据集与评估标准下开展,结果具备高度说服力。
4.1 隐空间可解释性对比:线性关系清晰可观测
第一组实验将 ICVAE 与传统 VAE、CVAE 在相同数据集上训练,提取二维隐空间并以氢键受体数量(HBA)作为颜色映射,直观对比三者的可解释性。结果显示,VAE 的隐空间呈现杂乱无规律的分布,无法与分子性质形成关联;CVAE 虽然能够按照条件将隐点分组,但各组之间无线性趋势,依然属于不可解释的黑箱状态;而 ICVAE 的隐点随 HBA 数值递增呈现完美的线性排布,低数值与高数值区域分界清晰,连续过渡平滑,直接证明隐空间与分子性质之间严格遵循预设的线性关系。这一结果意味着,研究人员可直接通过隐坐标判断对应分子的性质数值,实现前所未有的直观可解释性。
4.2 单属性精准调控:7 大成药性质独立可控
第二组实验系统验证 ICVAE 对单分子属性的独立控制能力,分别对分子量、logP、SAS、QED、HBA、HBD、TPSA 七项性质进行单独调控测试。对于分子量、logP、TPSA 等连续型性质,隐空间呈现连续线性分布,调整隐坐标可精准生成对应数值范围内的分子;对于 HBA、HBD 等离散型整数性质,隐空间呈现分段线性分布,每个数值对应独立的隐空间区域。
实验通过设定固定间隔的目标属性值,批量生成分子并计算实际属性误差,结果显示绝大多数生成分子的属性误差处于可接受范围内,有效性保持在高位。即使在属性数值边界区域,模型依然能够稳定生成有效结构,充分证明 ICVAE 具备可靠的单属性精准调控能力,可满足药物设计中对单一关键成药性质的定制化需求。
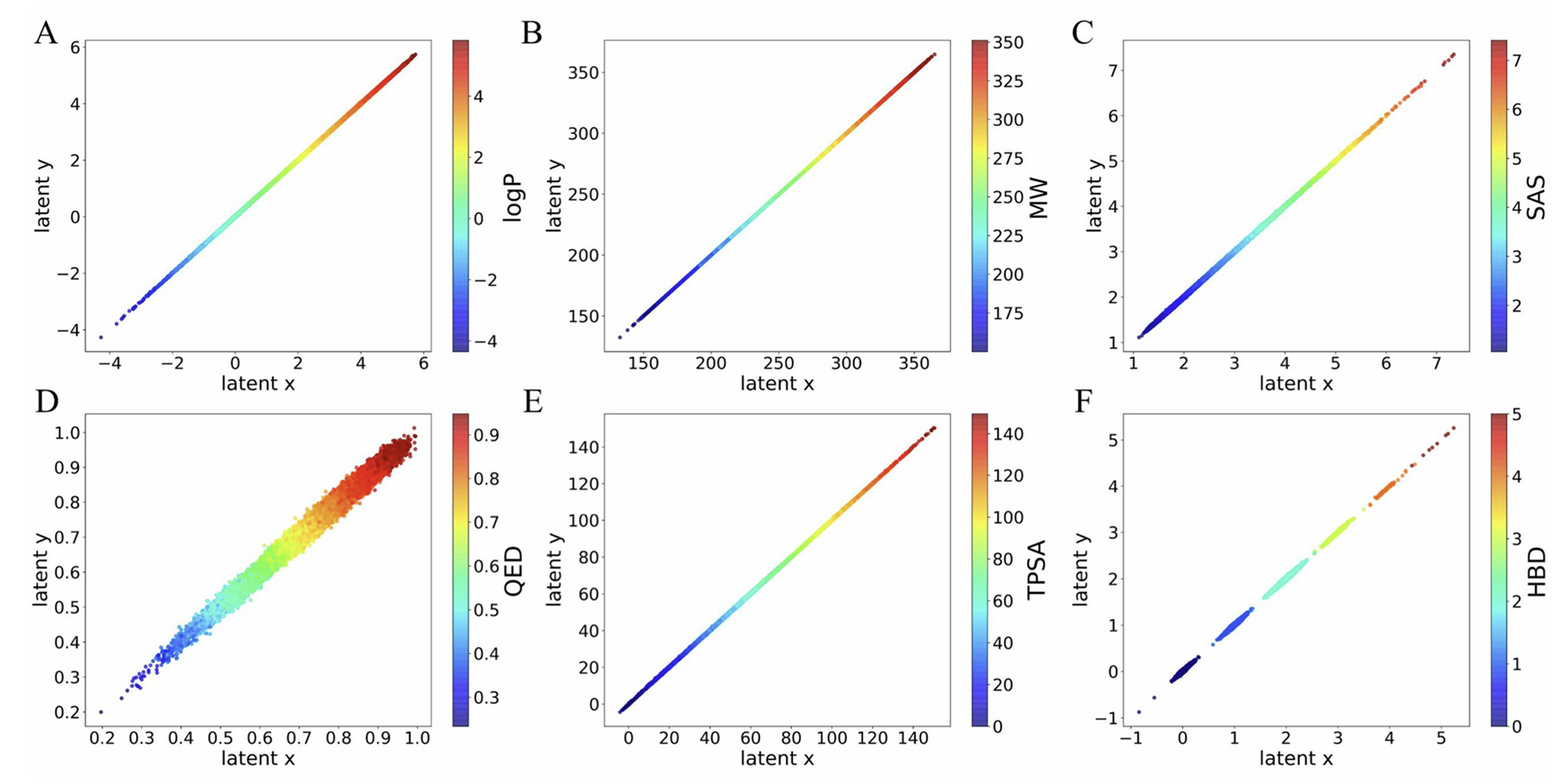
图3 单分子属性与隐空间的线性关系图
4.3 多属性联合调控:多目标药物设计高效实现
第三组实验进一步验证 ICVAE 同时调控多项分子性质的能力,分别测试 HBA 与 HBD、logP 与 HBA、MW 与 TPSA 三组双属性组合。实验中两项属性分别对应隐空间的一个维度,各自保持独立线性关系,互不干扰。连续型属性与离散型属性组合时,模型可稳定区分不同维度的语义信息,生成同时满足两项属性约束的分子。
在分子量与拓扑极性表面积联合调控实验中,除极端数值区间因训练数据稀疏导致生成效果略有下降外,大部分区间内生成分子均能精准命中目标属性组合。这一结果极具工业应用价值,意味着药化研究人员可直接设定多项成药指标,通过 ICVAE 一键生成满足全部约束的候选分子,无需复杂多目标优化算法,大幅降低从头药物设计的门槛与成本。
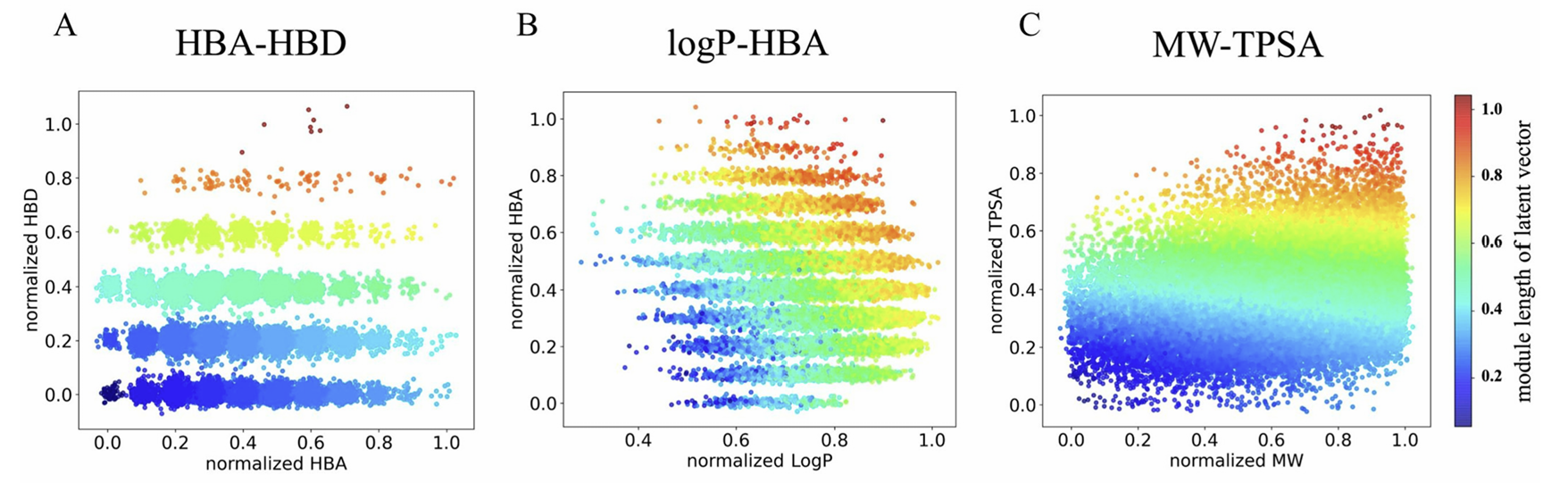
图4 双属性联合控制结果图
4.4 生成质量量化评估:全面超越主流生成模型
研究采用 MOSES 标准分子生成评估体系,从有效性、新颖性、唯一性、多样性等关键指标对 ICVAE、VAE、CVAE 进行量化对比。结果显示,ICVAE 在有效性(Valid)指标上达到 0.979,略高于 VAE 与 CVAE,说明生成的分子结构合法稳定;新颖性(Novelty)达到 1.000,意味着生成的分子几乎均为全新化合物,具备发现潜在药物的价值;唯一性(Unique@1k)与多样性(IntDiv)同样位居第一,证明生成分子库无冗余、覆盖化学空间广泛。综合来看,ICVAE 不仅实现可解释性突破,在生成质量核心指标上同样实现全面领先,兼顾可解释性与实用性。
五、ICVAE 的科学价值与产业应用前景
ICVAE 的提出,不仅是生成模型架构的一次技术改进,更是 AI 驱动药物设计理念的重要升级,其核心价值在于彻底打破传统生成模型的黑箱困境,为学术界与工业界提供透明、可控、可信的分子设计新范式。
从科学研究角度来看,ICVAE 首次在条件变分自编码器中实现隐空间与分子性质的线性解耦,为可解释人工智能在化学与生物医学领域的应用提供了可复用的方法论。传统生成模型只能输出结果,无法揭示分子结构与性质之间的关联规律,而 ICVAE 让每一个隐维度都具备明确的物理语义,帮助研究人员理解模型学习到的化学规则,推动从头分子设计从经验驱动走向机理驱动。
在产业应用层面,ICVAE 能够直接嵌入药物研发流程,赋能小分子药物、靶向抑制剂、候选化合物优化等多个关键环节。在药物分子早期设计阶段,研究人员可通过 ICVAE 快速生成满足多项成药性质约束的候选分子,缩小实验筛选范围;在先导化合物优化阶段,可精准调整特定性质指标,如提升溶解度、降低毒性、改善成药性,避免盲目合成与测试。与传统高通量筛选相比,ICVAE 能够将耗时数月的化合物筛选过程压缩至数天,显著降低研发成本与时间消耗。
同时,ICVAE 的线性可解释特性使其具备高度的可信赖性,更容易满足医药研发领域的合规与验证要求。研究人员可清晰追溯每一个分子的生成依据,为候选药物的机理阐述与专利申报提供有力支撑。随着模型进一步扩展至更多分子性质与生物活性标签,ICVAE 有望成为下一代 AI 药物设计平台的核心引擎,推动更多疾病领域的创新药物加速问世。
六、总结
ICVAE(可解释条件变分自编码器)是 AI 分子生成领域的里程碑式工作。它通过隐变量与分子性质的线性约束与改进损失函数,彻底打破传统模型的黑箱困境,实现了隐空间可解释、分子性质精准控、生成过程可理解。
模型既能单独控制分子量、logP、HBA、HBD、TPSA 等关键性质,也能同时优化多重要指标,且在生成质量上全面领先现有模型。ICVAE 证明:AI 药物生成不必依赖神秘的黑箱,透明、可控、可解释才是下一代生成模型的核心方向。
随着 ICVAE 的不断发展与扩展,未来的药物研发将真正进入精准设计、理性创造、高效迭代的全新阶段,让更多疾病拥有被治愈的可能。
论文链接:https://www.mdpi.com/1422-0067/26/9/3980 | 





















