本帖最后由 离子 于 2026-5-28 16:02 编辑
本文解读研究——基于解耦变分自编码器(Disentangled Variational Autoencoder, DVAE)的逆向材料设计方法。该工作面向高熵合金等复杂材料体系,提出一种半监督生成式建模框架,通过将目标性能与其他材料特征在隐空间中严格解耦,实现小样本下高精度性能预测、可控式新材料生成与全程可解释的逆向设计。模型同时利用标注数据与无标注数据进行联合训练,在高熵合金单相 / 多相分类任务中展现优异精度,并支持从目标性能直接反向推导合金成分,为新能源、航空航天等关键领域的高效材料研发提供通用、可扩展的 AI 新范式。

一、引言:逆向材料设计的需求与现有方法的困境
材料是支撑现代工业与前沿科技的核心基础,从高温结构材料、固态电池电解质到量子功能材料与生物医用材料,重大技术突破往往依赖新材料的发现与突破。然而,传统材料研发依赖大量实验试错,研发周期长、成本高、效率低,尤其对于高熵合金这类由多种主量元素按不同比例混合而成的复杂材料,其成分空间巨大、结构多样,仅依靠实验筛选几乎不可能穷尽所有潜在组合。在这样的背景下,逆向材料设计成为突破研发瓶颈的关键方向:不再从材料推导性能,而是直接根据目标性能,反向生成满足要求的材料成分与结构。
在各类 AI 生成模型中,变分自编码器(VAE)因其能够学习数据的潜在概率分布、生成连续且可控的样本、训练过程稳定等优势,被广泛应用于材料生成与设计。然而,传统 VAE 在实际应用中存在难以回避的缺陷:首先,隐空间高度纠缠,目标性能与材料的其他特征混合在一起,研究者无法单独调控某项性能而不改变其他属性,导致生成过程不可控;其次,对标注数据依赖度过高,而真实实验中带准确性能标注的数据极为稀缺,纯监督学习难以达到理想效果;最后,模型可解释性极差,属于典型的 “黑箱模型”,无法说明生成某种材料的依据,难以满足工业界对可靠性与可追溯性的要求。
为解决上述问题,本研究提出解耦变分自编码器(DVAE),将目标属性从混合的隐空间中彻底分离,采用半监督学习方式同时利用标注数据与无标注数据,并结合物理先验特征与可解释分析工具,构建一套数据高效、可控生成、全程可解释的逆向材料设计流程。该方法在高熵合金单相形成这一关键任务上得到系统验证,证明其在复杂材料体系中的强大能力与广泛适用性。
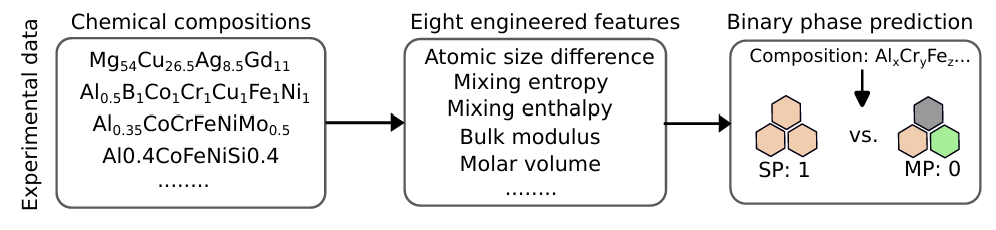
Figure 1 高熵合金数据集与特征构成图
二、解耦变分自编码器(DVAE)核心原理
解耦变分自编码器(DVAE)的核心创新,是将材料的信息拆分为相互独立的两部分:一部分专门表示目标属性(如高熵合金是否形成单相结构),另一部分表示除此之外的所有材料特征(元素组成、配比关系、结构特征、物理根源等)。通过这种解耦设计,模型可以在不干扰材料整体特征的情况下,单独调控目标性能,实现真正意义上的可控逆向设计。
在概率建模层面,DVAE 将材料、目标属性、隐变量纳入统一的联合分布中。其生成模型假设三者满足可分解的概率关系:
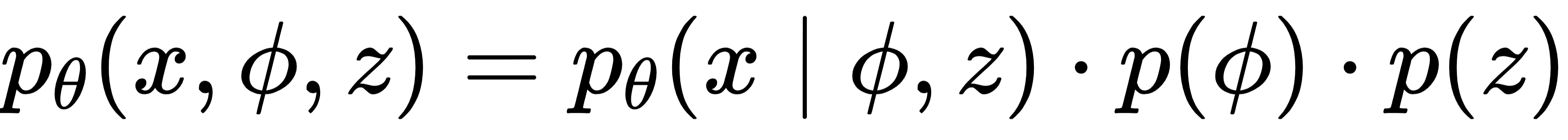
其中,x 代表材料的成分输入,Φ代表目标性能(单相 / 多相),z 代表隐变量,pθ(x|Φ,z)是由神经网络参数化的解码器,用于从目标属性和隐变量重建材料成分。这种分解使目标属性与隐变量彼此独立,从根源上实现解耦。
为了实现高效推理,模型采用均值场假设,将后验分布近似为两个独立部分的乘积,分别对应目标属性预测与隐变量推理:
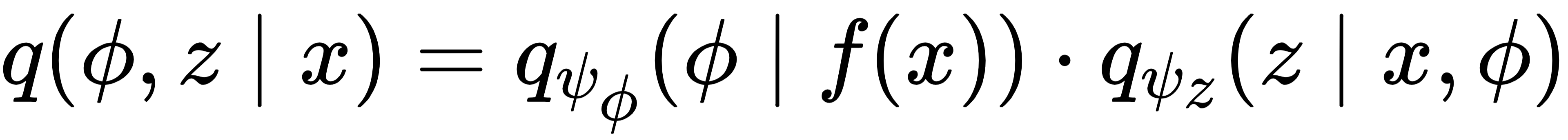
其中 f(x)是基于领域知识预先构造的8 个物理特征,包括原子尺寸差、混合焓、混合熵、价电子浓度、摩尔体积、熔点、体模量和电负性差。这些物理特征已被证实对高熵合金的相形成行为具有强指示意义,将其直接嵌入模型可以显著提升物理一致性与预测可靠性。
在训练目标上,DVAE 采用半监督损失函数,同时利用无标签数据和带标签数据进行联合优化:
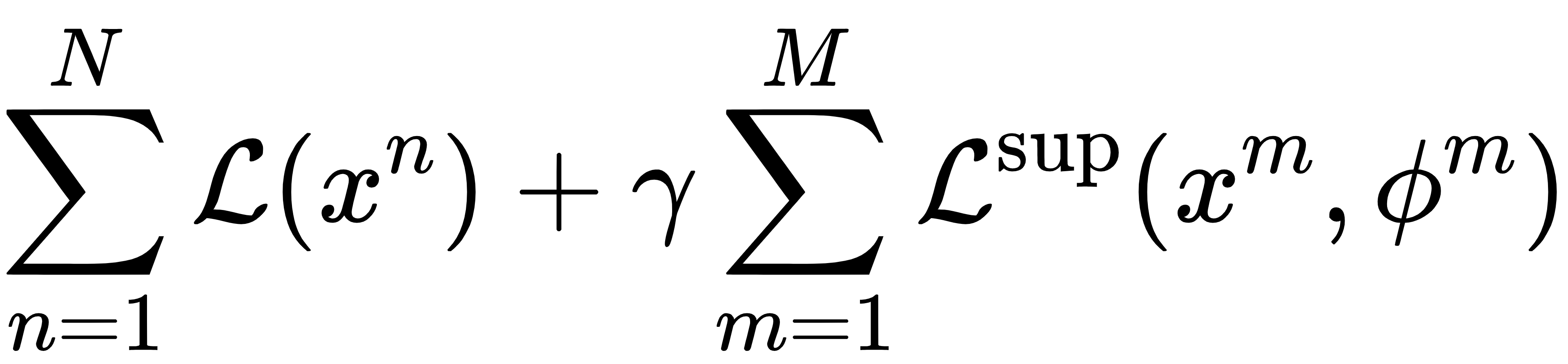
第一部分是标准 VAE 的证据下界(ELBO)损失,用于无监督重建;第二部分是监督分类损失,用于学习目标性能。通过超参数\gamma平衡两项损失,模型能够在数据有限的情况下保持高泛化能力,实现数据高效学习。
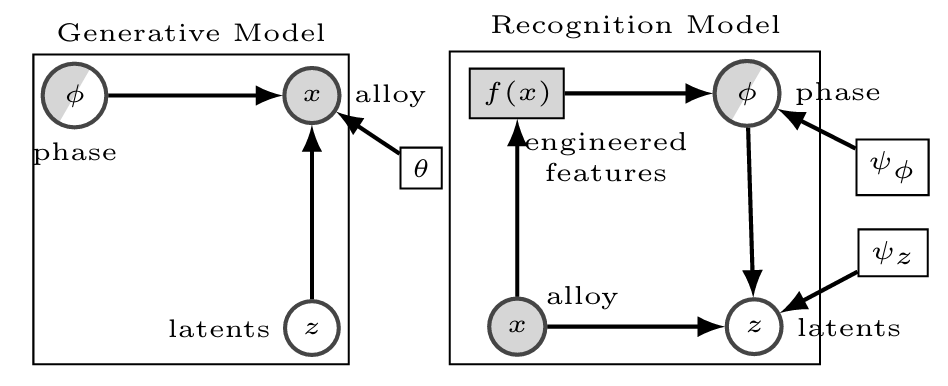
Figure 2 DVAE 生成模型与推理模型架构图
三、模型架构、特征设计与训练流程
DVAE 的整体架构由编码器、解码器、分类头和物理特征提取模块四部分组成,充分兼顾生成能力、预测精度与可解释性。模型的输入包含两种互补信息:一是元素成分向量,采用数据集中最常见的 30 种元素,将合金表示为固定长度的成分比例向量;二是8 个手工构造的物理先验特征,这些特征直接反映合金的结构稳定性、混合效应与原子环境,为模型提供可解释的物理信号。
编码器由两层各 100 个神经元的全连接网络构成,将材料的成分与物理特征映射到目标属性分布和隐变量分布。解码器同样采用两层全连接网络,从目标属性Φ和隐变量z重建输入的成分向量,使生成的成分尽可能接近真实合金。分类头直接从物理特征预测单相形成概率,与生成模型共享特征并互相正则化,提升整体鲁棒性。
在训练过程中,数据集被随机划分为标注训练集、无标注训练集、验证集与测试集。模型使用 Adam 优化器进行训练,设置初始学习率并采用动态衰减策略,若验证集性能长时间不提升则自动降低学习率。训练过程同时优化重建精度、隐空间规整度和分类准确率,使模型在生成、预测与解耦三个目标上同时达到最优。整个训练流程不需要复杂的超参数调优,也不依赖大规模算力,具备良好的工程落地潜力。
与传统 VAE 不同,DVAE 并不追求隐空间完全无监督聚类,而是主动将目标属性剥离,使隐空间只保留与材料结构相关的信息,从而让逆向设计更加稳定、可预测、可复现。这种架构设计使得模型既拥有生成模型的创造力,又保留了分类模型的精准度。
四、实验结果与性能分析:高精度、数据高效、解耦清晰
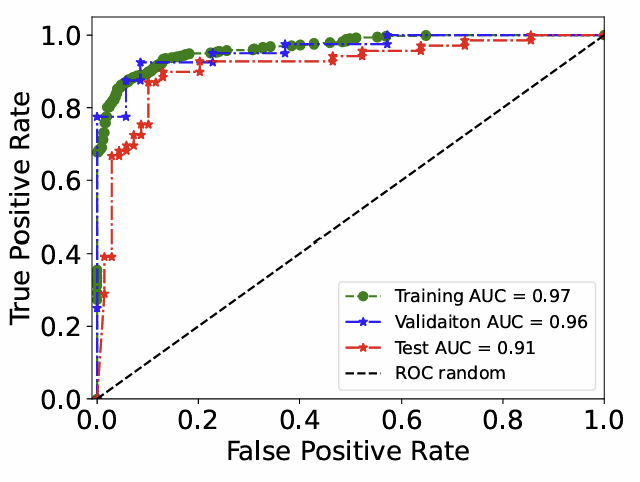
Figure 3 ROC曲线
研究团队在高熵合金实验数据集上对 DVAE 进行了全面系统的评估,验证其在分类精度、重建质量、数据效率与隐空间解耦四个方面的突出能力。在分类任务中,模型在测试集上达到AUC 0.91以上的高准确度,表明其可以可靠预测高熵合金的单相形成概率。在重建任务中,模型对成分向量的平均重建误差仅为 2.3%,即使在复杂的多元素合金中也能保持高精度还原,证明生成的样本具有化学合理性与结构真实性。
在数据效率方面,DVAE 展现出明显优于纯监督学习的性能。当标注数据量充足时,DVAE 与监督学习精度相当;当标注数据大幅减少时,DVAE 依靠无监督重建与物理先验保持稳定性能,而纯监督模型显著下降。这一结果证明,半监督框架能够充分利用大量易获取的无标注数据,显著降低对昂贵实验数据的依赖,对实际研发场景极具价值。
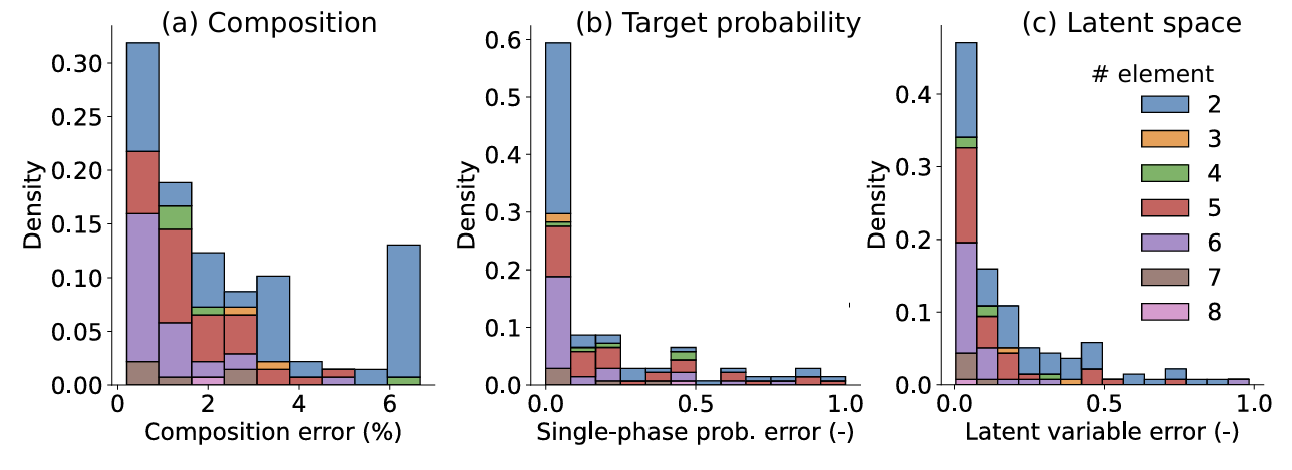
Figure 4 合金重建误差分布图
在隐空间解耦效果上,可视化结果清晰表明:单相合金与多相合金在隐空间中完全混合分布,没有形成明显分隔。这一现象直接证明,目标属性已经被完全从隐空间中剥离,隐变量z不再编码相信息,从而实现了真正意义上的解耦。这种解耦特性使得研究者可以固定材料的整体特征,单独调控目标性能,为逆向设计提供坚实基础。
在样本生成质量上,DVAE 生成的合金成分符合化学规律,元素替换遵循周期表相似性,不会出现不合理或不可制备的成分。模型不仅能生成全新合金,还能对已有合金进行迭代优化,将多相合金逐步调整为单相合金,且过程可追踪、可解释。
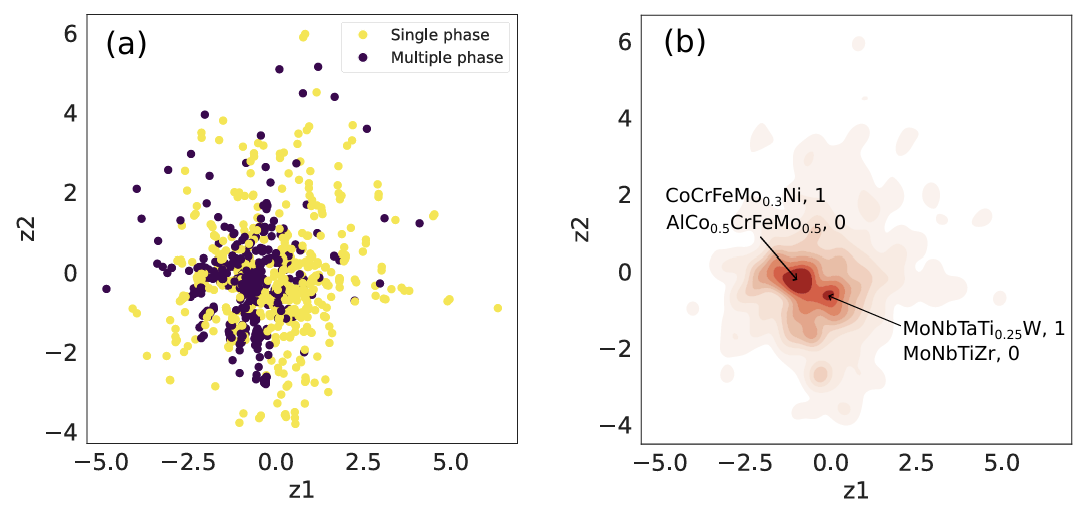
Figure 5 隐空间解耦可视化
五、逆向材料设计的三种工作模式
基于解耦隐空间与半监督生成能力,DVAE 支持三种实用化的逆向材料设计模式,覆盖从高通量筛选到定向生成的全流程需求。
第一种模式是高通量虚拟筛选。利用模型训练好的分类头,对海量未探索的成分空间进行快速扫描,直接筛选出高概率形成单相结构的合金,大幅缩小实验验证范围,显著降低研发成本。这种模式适合快速发现大量候选材料,适合初期大规模探索。
第二种模式是从隐空间定点定向生成。研究者可以先在隐空间中定位某类合金的区域,例如难熔高熵合金区域,然后设定目标单相概率,直接从隐点生成全新合金。这种方式高度可控,生成的合金保持相似的元素类型与结构特征,适合定向优化某一类材料体系。
第三种模式是迭代逆向优化,也是最具实用价值的模式。研究者输入一个已知但性能不佳的多相合金,模型自动预测其单相概率,随后反转目标概率并生成新成分,重复迭代直到满足预设阈值。在实际案例中,模型通过三步迭代,成功将一个典型多相合金逐步优化为高概率单相合金,同时保留主体元素、微调配比,完全符合实验可合成逻辑。这种模式能够直接用于现有材料的性能升级,具备高度工业化价值。
六、双重可解释性:从模型结构到事后分析
DVAE 从设计之初就以可解释性为核心目标,提供两层可解释性,彻底告别黑箱生成。
第一层是模型原生的解耦可解释性。目标属性与隐变量在概率结构上相互独立,目标属性由物理先验特征直接预测,每一次生成和调控都有明确的对应关系,研究者可以清晰判断调控方向与预期结果。这种透明性使得模型决策可追溯、可验证、可信任。
第二层是基于 SHAP 值的事后可解释性。研究采用 SHAP 分析对分类头进行全局与局部解释,明确量化各物理特征对单相形成的贡献方向与大小。结果显示,较小的原子尺寸差、较低的混合熵、较高的熔点和较高的体模量更有利于单相形成。这一结论与经典材料科学规律高度一致,证明模型不仅学得准,而且学得 “有物理道理”。双重可解释性使 DVAE 不仅能生成新材料,更能揭示材料设计的内在规律,为理论研究与专利撰写提供关键依据。
七、结论与展望
本研究提出的解耦变分自编码器(DVAE)为逆向材料设计提供了一套数据高效、可控生成、全程可解释的完整解决方案。通过将目标性能从隐空间中彻底解耦,结合半监督学习与物理先验,DVAE 在标注数据有限的情况下仍能保持高精度,实现从性能需求到材料成分的直接逆向生成。在高熵合金体系中的验证表明,该方法不仅预测准确、生成可靠,而且具备清晰的可解释性与实用化潜力。
该框架不局限于高熵合金,可轻松扩展到多种材料体系,包括固态电池材料、催化材料、高温超导材料、高分子材料等,尤其适合多元素、高维度、数据稀缺的复杂材料设计。未来,结合更多结构特征、多目标性能扩展与主动学习策略,DVAE 有望进一步提升生成能力与泛化性能,成为下一代智能材料研发平台的核心引擎,推动新材料发现从 “试错筛选” 迈入 “精准定制” 的新时代。
论文链接:https://www.cell.com/cell/fulltext/S0092-8674(26)00463-0 | 





















