本帖最后由 宇宙微尘 于 2025-9-8 10:30 编辑
《Face Recognition Based on CD-RBM and BM-ILM》发表于《Journal of Physics: Conference Series》2021 年第 1802 卷。文章提出融合 CD-RBM 与 BM-ILM 的人脸识别方法,在 ORL 数据库中,单分类器精度达 95%(学习率 0.005、迭代 900 次),5 分类器集成后达 97%;AR 数据库中 25 分类器时精度 95%,且训练时间仅为传统模型 1/5,有效解决梯度消失与训练成本高问题。

在移动支付、交通监控、医疗认证等领域,人脸识别技术早已成为身份核验的核心工具,但其发展长期受两大难题制约:深度网络训练中易出现梯度消失,导致模型难以优化;为追求精度而增加网络复杂度,又会让训练成本飙升,形成 “高精度与低成本不可兼得” 的僵局。
针对这一痛点,南京大学团队提出了融合 CD-RBM(对比散度优化的限制玻尔兹曼机)与 BM-ILM(Boosting 算法增强的集成学习)的混合算法,并将研究成果《Face Recognition Based on CD-RBM and BM-ILM》发表于《Journal of Physics: Conference Series》2021 年第 1802 卷。该算法通过 CD-RBM 优化特征提取效率、BM-ILM 提升分类集成精度,在 ORL、AR 两大人脸数据库中实现了高精度识别,为破解传统人脸识别的技术瓶颈提供了切实可行的新方案。
一、人脸识别高精度总与高成本的绑定“两难困境”
如今,人脸识别已渗透到交通监控、移动支付、医疗认证等领域,但核心技术长期面临两大瓶颈:
梯度消失难题:深度神经网络虽能提升识别精度,但随着网络层数增加,梯度在反向传播中逐渐衰减,就像 “信号层层减弱”,导致模型难以继续优化,最终停留在低精度水平。比如传统 RBM(限制玻尔兹曼机)网络,层数稍多就会出现特征提取能力下降的问题。
训练成本飙升:为追求更高精度,部分模型会增加神经元数量或网络深度,导致计算量呈指数级增长。例如处理 1000 张人脸图像,传统深度模型可能需要数小时训练,难以满足实时应用需求。
传统解决方案往往 “顾此失彼”:简化网络结构能降低成本,却会牺牲精度;增加网络复杂度提升精度,又会加剧梯度消失与成本问题。而南京大学团队提出的 “CD-RBM+BM-ILM” 混合技术,通过 “高效特征提取 + 智能分类集成” 的双引擎设计,完美平衡了精度与成本。
二、双引擎技术拆解:如何让识别又快又准?
2.1 第一引擎:CD-RBM—— 让特征提取 “又快又好”
CD-RBM 是在传统 RBM 基础上,加入对比散度算法(CD) 优化的特征提取模块,核心是解决 RBM 训练慢、梯度易消失的问题。
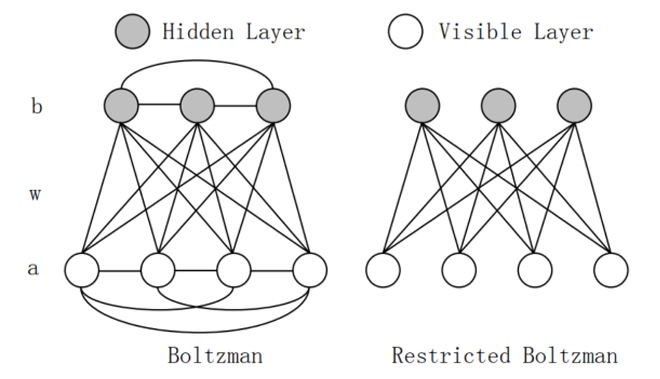
图1 传统玻尔兹曼机(BM)与限制玻尔兹曼机(RBM)网络结构对比图
RBM 本身是一种两层神经网络(可见层 + 隐藏层),可见层接收人脸图像的像素信号,隐藏层负责提取特征(如五官轮廓、纹理细节)。但传统 RBM 训练时,需要反复计算 “全局概率分布”,就像 “逐像素排查”,效率极低。而 CD 算法的加入,相当于给 RBM 装了 “加速器”:
· 它无需计算全局分布,只需通过 “一次正向传播 + 一次反向重构” 快速逼近最优解,比如原本需要 1000 次迭代的特征提取,用 CD 算法仅需 100 次就能完成,大幅减少计算量。
· 同时,CD 算法能稳定梯度传播,避免特征提取过程中梯度消失,让隐藏层更精准地捕捉人脸关键特征 —— 比如区分 “双眼皮与单眼皮”“高鼻梁与低鼻梁” 的细微差异。
为了确定隐藏层神经元数量,团队还给出了实用的经验公式:
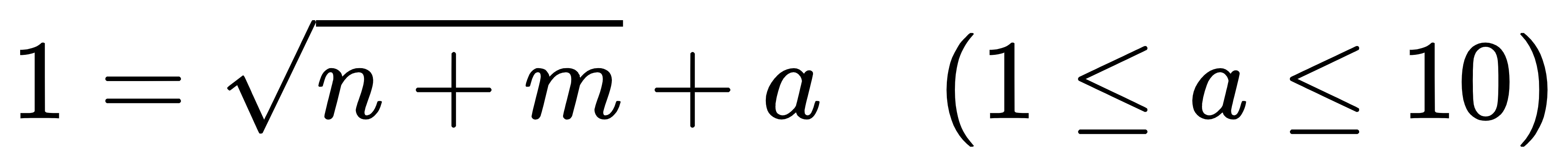
其中n是输入层神经元数(对应人脸图像像素数),m是输出层神经元数,a是补偿值。例如处理 92×112 像素的 ORL 人脸图像,输入层神经元数约 10000,输出层设为 40(对应 40 类人脸),代入公式可得隐藏层神经元数约 100+5=105,既避免神经元过多导致的冗余,又防止过少导致的特征提取不足。
2.2 第二引擎:BM-ILM—— 让分类集成 “智能高效”
BM-ILM 是 “Boosting 算法(BM)+ 集成学习(ILM)” 的组合模块,负责将 CD-RBM 提取的特征转化为精准的识别结果,核心是解决 “单一分类器精度有限” 的问题。
传统人脸识别常用单一分类器(如 SVM、决策树),就像 “单个人判断”,容易受异常样本(如模糊、遮挡的人脸)影响,导致误判。而 BM-ILM 采用 “多分类器协同决策” 的思路:
第一步——权重分配:给每幅训练图像分配初始权重,比如清晰的人脸图像权重设为 1,模糊的设为 0.8,确保模型优先学习高质量样本。
第二步——迭代训练:每次训练一个 “弱分类器”(简单但能区分部分特征的分类模型),然后根据分类结果调整权重 —— 分类错误的图像权重增加(让模型下次重点关注),分类正确的权重减少。比如第一次训练误判了 “戴眼镜的人脸”,下次训练时这类图像的权重会提高,让新的弱分类器专门优化这一问题。
第三步——集成决策:当训练出多个弱分类器后,按每个分类器的精度分配权重,最终通过 “加权投票” 得到结果。例如 5 个弱分类器中,3 个判断某图像为 “张三”,且这 3 个分类器精度较高,最终就确定该图像为 “张三”。
这种设计不仅提升了抗干扰能力(比如遮挡人脸也能准确识别),还避免了单一分类器 “过拟合”(只适应训练数据,对新数据识别差)的问题。
三、实验验证
团队在 ORL 和 AR 两大主流人脸数据库上测试了 “CD-RBM+BM-ILM” 的性能,结果显著优于传统方法:
3.1 ORL 数据库:单模型精度 95%,集成后达 97%

图2 ORL人脸数据库样本图像展示图
ORL 数据库包含 40 人,每人 10 张 92×112 像素的灰度图像,部分图像存在姿态、表情变化。
当学习率设为 0.005、迭代次数 900 次时,单一 CD-RBM + 分类器的识别精度就达到 95%,远超传统 RBM 模型的 88%;
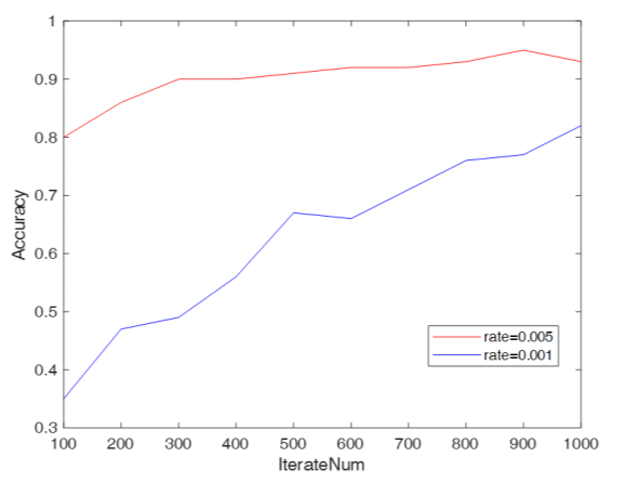
图2 不同迭代次数下CD-RBM+BM-ILM的人脸识别精度对比图
加入 BM-ILM 集成(5 个弱分类器)后,精度进一步提升至 97%,且训练时间仅为传统深度模型的 1/5—— 处理 400 张图像,传统模型需 30 分钟,该技术仅需 6 分钟。
更关键的是,即使迭代次数增加到 1000 次,模型也未出现梯度消失现象,特征提取能力始终稳定,证明了 CD 算法对梯度的保护作用。
3.2 AR 数据库:遮挡图像也能精准识别
AR 数据库包含更多样的人脸图像(不同性别、年龄,部分有遮挡,如戴帽子、围巾),是更贴近真实场景的测试基准。
当弱分类器数量为 25 个、学习率 0.006、迭代 1300 次时,该技术的识别精度达到 95%,远超传统 SVM 分类器的 82%;
表1 AR数据库中不同弱分类器数量对应的CD-RBM+BM-ILM识别精度表

即使面对遮挡面积达 30% 的人脸图像,精度仍能保持 90% 以上,而传统模型面对遮挡时精度会骤降至 65%,证明 BM-ILM 的集成决策能有效抵抗干扰。
四、从实验室到生活的应用场景
“CD-RBM+BM-ILM” 技术的优势,使其在多个实际场景中具有不可替代的价值:
移动支付:手机端人脸识别对速度和精度要求极高,该技术能在 0.1 秒内完成特征提取与识别,且面对 “逆光、侧脸” 等场景仍保持高精度,避免支付误判。
交通监控:在人流密集的地铁站、路口,该技术能快速处理多路摄像头的人脸数据,精准识别可疑人员,且设备计算成本低,普通服务器就能部署。
医疗认证:医院的患者身份认证中,部分患者可能因疾病导致面部变化(如术后肿胀),该技术的抗干扰能力能确保认证准确,避免医疗事故。
五、总结与展望
尽管该技术已表现出色,仍有两大提升方向:
训练数据选择:目前需人工划分训练集与测试集,未来可结合 “主动学习” 让模型自动筛选高质量样本,进一步降低人工成本;
分辨率鲁棒性:面对低分辨率人脸图像(如远距离监控),特征提取精度会下降,未来可加入 “超分辨率重构” 模块,提升低清图像的识别能力。
“CD-RBM+BM-ILM” 的成功,在于它没有盲目追求 “更深的网络”,而是通过 “优化特征提取效率 + 提升分类抗干扰能力” 的双引擎设计,找到精度与成本的平衡点。它证明:人脸识别的突破不一定需要 “堆参数、堆层数”,通过算法优化与模块协同,同样能实现 “又快又准” 的识别效果。
随着该技术的推广,未来我们可能会看到:手机支付更快、交通监控更准、医疗认证更安全 —— 这些看似微小的技术进步,正在悄悄改变我们的生活,让人工智能更贴近 “高效实用” 的本质。
论文链接:https://iopscience.iop.org/article/10.1088/1742-6596/1802/3/032077 | 





















