本帖最后由 薛定谔了么 于 2025-9-10 15:53 编辑
《 Comparative Study of GAN and VAE 》发表于 International Journal of Computer Applications 2018 年第 182 卷第 22 期。文章对比 VAE 与 GAN(以 DCGAN 为例),在 MNIST 数据集实验中,VAE 最终 MSE 34.66,生成图较模糊但多样性高;DCGAN MSE 36.3,生成图更清晰却易模式崩溃。VAE 支持半监督与无监督学习,训练稳定;DCGAN 仅无监督,训练波动大。二者融合模型(如 VAE-GAN)可兼顾清晰度与多样性,为生成模型优化提供方向。

在 21 世纪 10 年代深度学习浪潮中,无监督学习因 “无需人工标注即可挖掘数据规律” 的特性,成为突破监督学习数据依赖瓶颈的关键方向,而生成模型正是这一领域的核心探索成果 —— 它让机器从 “识别数据” 迈向 “创造数据”,为图像生成、语音合成、数据增强等应用提供了技术基石。
在众多生成模型中,2013 年提出的变分自动编码器(VAE)与 2014 年诞生的生成对抗网络(GAN),迅速成为两大 “明星架构”:VAE 以概率建模为核心,首次实现了对数据分布的可解释性建模;GAN 则凭借 “对抗博弈” 思路,刷新了生成样本的逼真度上限。
在这样的技术背景下,《 Comparative Study of GAN and VAE 》通过实验系统对比了生成对抗网络(GAN)与变分自动编码器(VAE)的核心差异。这两种模型作为无监督学习领域的 “明星选手”,虽同为生成数据而生,却因设计思路不同,在图像生成、数据分布建模等场景中表现出截然不同的优势与局限,而二者的融合更开启了生成模型的新可能。
一、从 “目标” 看 GAN 与 VAE 的本质不同
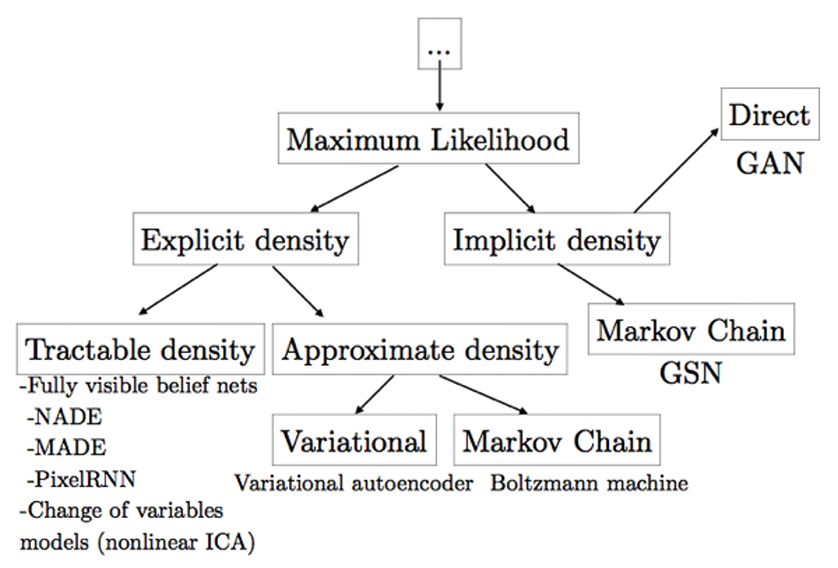
图1 生成模型分类图谱
在机器学习中,生成模型的核心目标是 “学习数据分布,生成新样本”,但 GAN 与 VAE 实现这一目标的路径完全不同,可类比为 “艺术家创作” 的两种思路:
VAE:精准建模的 “数据分析师” :VAE 更像 “先搞懂数据规律,再按规律创作”。它通过 “编码器 - 解码器” 结构,先将输入数据(如 MNIST 手写数字)压缩成低维潜在空间的概率分布(而非固定向量),再从这个分布中采样并重构出原始数据。比如生成手写数字 “3” 时,VAE 会先学习 “数字 3 的轮廓、笔触粗细” 等特征的概率范围,再按这个范围生成新样本,确保生成结果符合数据的整体规律。
GAN:对抗博弈的 “艺术家与评论家” :GAN 则是 “在竞争中迭代优化”。它包含两个网络:生成器(艺术家)负责从随机噪声中生成样本,判别器(评论家)负责判断样本是 “真实数据” 还是 “生成伪造数据”。二者如同 “猫鼠游戏”—— 生成器努力让作品骗过判别器,判别器则努力提升辨别能力,最终生成器能产出以假乱真的样本。比如生成 “3” 时,GAN 不会刻意建模 “3 的特征规律”,而是通过一次次 “被判别、被修正”,逐渐优化生成效果。
二、GAN 与 VAE 如何实现 “数据生成”?
2.1 VAE:用 “概率与重构” 生成数据
VAE 的核心是 “变分推断”,通过两个关键步骤实现数据生成:
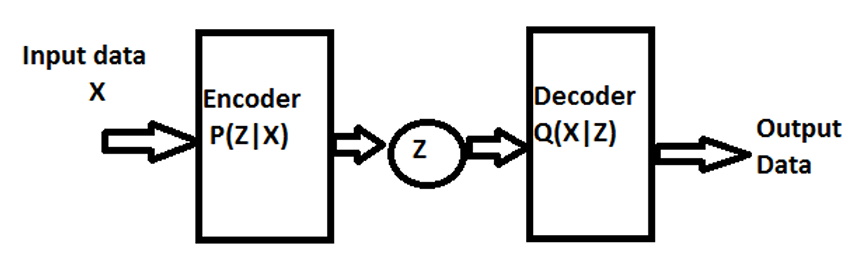
图2 变分自动编码器(VAE)架构图
步骤 1:编码器 —— 将数据压缩成概率分布
编码器接收原始数据(如 28×28 的 MNIST 图像),输出潜在变量Z的概率分布(通常是正态分布),即Q(Z|X)。比如输入数字 “3”,编码器会输出 “Z的均值为 [0.2, -0.5]、方差为 [0.1, 0.08]” 的分布,这个分布包含了 “3” 的关键特征信息。
步骤 2:解码器 —— 从分布中采样并重构
解码器从编码器输出的分布中随机采样一个Z,再将其还原为原始数据维度(如 28×28 图像),即P(X|Z)。为确保生成质量,VAE 的损失函数包含两部分:
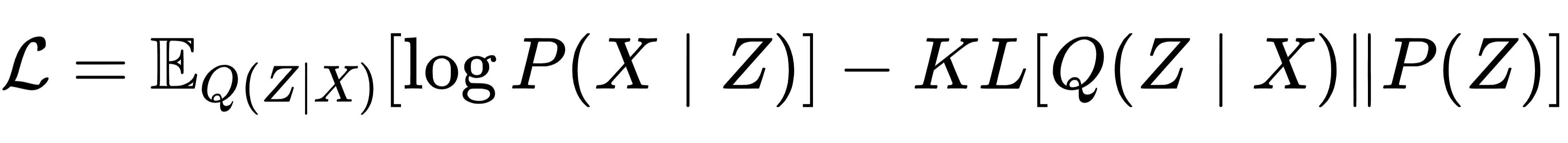
第一部分是 “重构损失”:确保解码器能从Z中精准还原原始数据,比如生成的 “3” 与真实 “3” 的像素差异要小;
第二部分是 “KL 散度”:约束编码器输出的分布Q(Z|X)接近预设的先验分布P(Z)(通常是标准正态分布),避免潜在空间数据分布混乱,确保生成样本的多样性。
实验中,VAE 在 MNIST 数据集上的表现可直观体现其特点:训练初期(1-5 个 epoch)生成的数字模糊且边缘粗糙,但随着 epoch 增加(至 100 个),图像逐渐清晰;若仅优化重构损失,生成样本会缺乏多样性(比如只生成少数几种 “3”);若仅优化 KL 散度,生成样本则会模糊不清 —— 只有平衡两者,才能既保证清晰度又兼顾多样性。

图3 VAE 在 MNIST 数据集上不同训练 epoch 的生成图像对比图
2.2 GAN:用 “对抗博弈” 生成数据
以实验中使用的 DCGAN(深度卷积 GAN)为例,其核心是 “minimax 博弈”,通过生成器与判别器的交替训练实现数据生成:
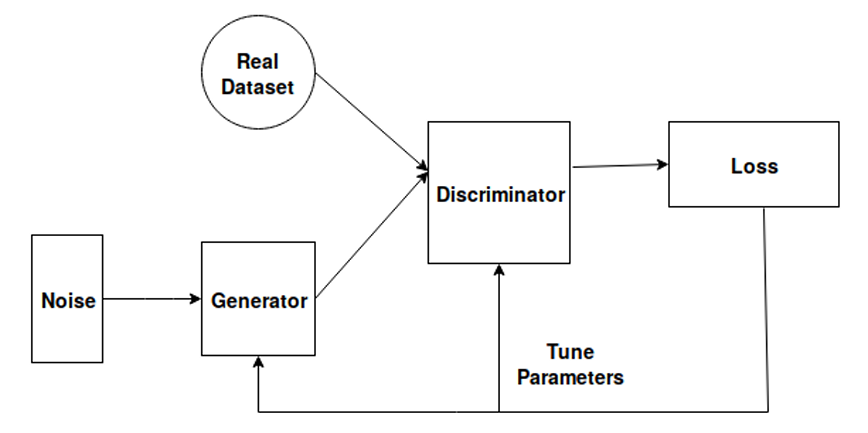
图4 生成对抗网络(GAN)架构图
生成器(G):从噪声到样本的 “创作者”
生成器接收随机噪声Z(如 100 维向量),通过反卷积层将其逐步放大为目标数据维度(如 28×28 图像),即G(Z)。比如输入噪声向量,生成器会输出一张类似手写数字的 “伪造图像”。
判别器(D):真假样本的 “裁判”
判别器接收样本(真实数据X或生成器输出的G(Z)),输出样本为 “真实数据” 的概率(0-1 之间),即D(X)或D(G(Z))。比如输入真实 “3”,判别器输出概率接近 1;输入生成的模糊 “3”,输出概率接近 0。
对抗训练:目标函数的 “猫鼠游戏”
GAN 的训练目标是求解以下 minimax 问题:
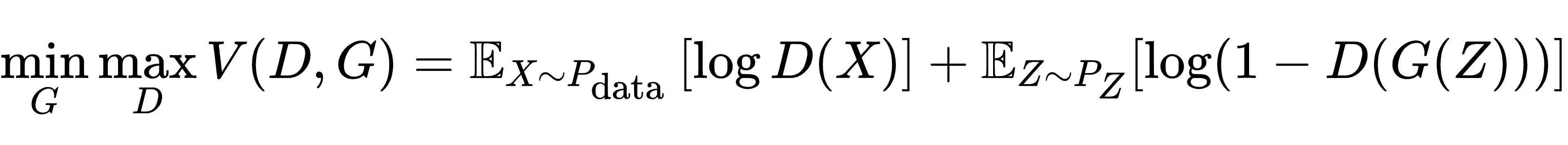
判别器D的目标:最大化V(D,G),即让真实样本的log D(X)尽可能大(接近 1),让生成样本的log(1-D(G(Z)))尽可能大(D(G(Z))接近 0);
生成器G的目标:最小化V(D,G),即让生成样本的log(1-D(G(Z)))尽可能小(D(G(Z))接近 1,骗过判别器)。
实验中,DCGAN 的生成效果呈现典型特点——训练初期(1-2 个 epoch)生成的几乎是 “乱码”,随着判别器与生成器的博弈(至 100 个 epoch),图像逐渐清晰;且 DCGAN 生成的数字边缘更锐利,细节比 VAE 更丰富 —— 但代价是训练不稳定,损失值会频繁波动,甚至出现 “模式崩溃”(比如只生成数字 “3” 和 “7”,忽略其他数字)。
三、GAN 与 VAE 的核心差异与适用场景
通过实验数据与可视化结果,可从 5 个关键维度对比 GAN(以 DCGAN 为例)与 VAE 的差异:
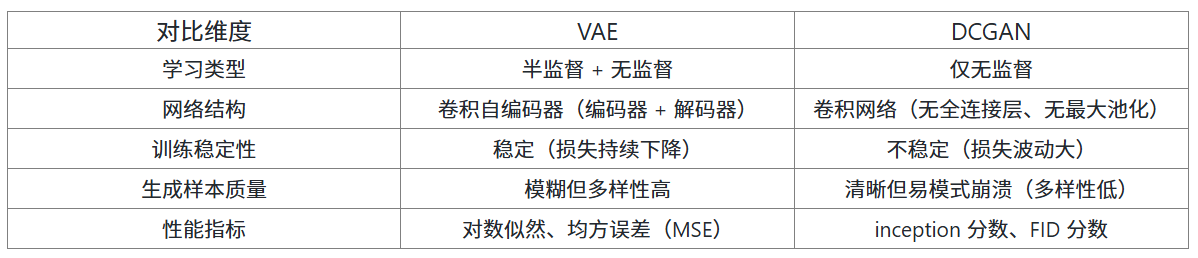
3.1 生成质量:GAN 更清晰,VAE 更均衡
VAE:实验中 VAE 的最终 MSE 为 34.66,生成的图像虽能识别,但整体偏模糊(比如数字边缘有 “毛边”),这是因为解码器输出的是 “分布均值”,相当于 “平均化” 了所有可能的样本特征;
GAN:DCGAN 的 MSE 为 36.3(略高于 VAE),但生成的图像更清晰锐利,细节更丰富(比如数字 “3” 的弯曲弧度更自然),这是因为对抗训练迫使生成器不断优化细节以骗过判别器。
3.2 多样性与稳定性:VAE 更可靠,GAN 易 “翻车”
VAE:由于 KL 散度约束,潜在空间数据分布更均匀,生成样本的多样性更高(能覆盖 MNIST 的 10 个数字),且训练过程稳定,损失持续下降;
GAN:容易出现 “模式崩溃”—— 实验中曾出现生成器反复生成 “1” 和 “9”,忽略其他数字,这是因为判别器过于强大时,生成器会 “投机取巧”,只生成能骗过判别器的少数样本;同时,GAN 的损失值波动大,难以判断训练是否收敛。
3.3 适用场景:按需选择
选 VAE:若需要稳定生成、保证样本多样性,或需半监督学习(如少量标签数据辅助训练),优先选 VAE。比如生成多种风格的手绘草图(Google 的 SketchRNN)、合成音乐(Google 的 Magenta MusicVAE)。
选 GAN:若追求高清晰度的生成样本,且能接受一定的训练不稳定性,优先选 GAN。比如生成逼真的卡通角色、超分辨率图像(SRGAN)、跨域图像转换(如马变斑马的 CycleGAN)。
四、突破局限:GAN 与 VAE 的 “强强联合”
既然 GAN 与 VAE 各有优劣,研究者自然想到 “融合二者优势”,其中最经典的是VAE-GAN。它的结构如图 6 所示:
· 保留 VAE 的编码器,将解码器替换为 GAN 的生成器;
· 用 GAN 的判别器计算损失,同时保留 VAE 的 KL 散度约束;
· 最终生成的样本既具备 GAN 的清晰度,又拥有 VAE 的多样性,实验中其生成效果远超单一模型。
此外,还有 “对抗自编码器(AAE)”“自注意力 GAN(SAGAN)” 等融合模型,它们的核心思路都是 “用 VAE 的概率建模解决 GAN 的稳定性问题,用 GAN 的对抗训练提升 VAE 的生成质量”,推动生成模型向 “更清晰、更多样、更稳定” 的方向发展。
五、总结与展望
GAN 与 VAE 作为生成模型的两大支柱,分别代表了 “对抗博弈” 与 “概率建模” 两种思路:VAE 如同 “稳扎稳打的工程师”,用严谨的概率分布保证生成的可靠性与多样性;GAN 则像 “敢闯敢试的艺术家”,在对抗中突破细节极限,生成更逼真的样本。
如今,二者的融合已成为主流方向 —— 不再纠结 “选 GAN 还是选 VAE”,而是通过组合创新解决单一模型的局限。未来,随着注意力机制、扩散模型等技术的融入,生成模型将在更广阔的领域发挥作用:从生成个性化医疗影像辅助诊断,到创造虚拟世界的场景与角色,再到为 AI 绘画提供更丰富的创意素材,持续为无监督学习开辟新的可能性。
文献链接:https://www.ijcaonline.org/archives/volume182/number22/30062-2018918039/ | 





















