本帖最后由 Jack小新 于 2025-10-16 18:16 编辑
《 Enhancing wind power prediction with self-attentive variational autoencoders: A comparative study 》发表于 Results in Engineering 2024年第23卷。文章提出SA-VAE模型,融合VAE与自注意力机制,分两阶段训练。用法、土5台风机数据测试,其平均R2达0.992,RMSE 34.090,MAE 22.432,远超LSTM、XGBoost等8种模型。该模型泛化与抗干扰能力强,为风电并网与电网调度提供技术支撑。

随着全球风电装机容量突破 900GW,准确的风电预测已成为电网稳定运行的关键。但风电受风速、地形等因素影响,输出波动剧烈,传统预测模型常因无法捕捉复杂非线性模式,导致误差居高不下。2024 年,来自沙特阿卜杜拉国王科技大学等机构的团队在《Results in Engineering》期刊发表研究,提出自注意力变分自动编码器(SA-VAE) ,将风电预测平均(R2)值提升至 0.992,远超 LSTM、XGBoost 等主流方法,为风电高效并网提供了新方案。
一、风电预测难在哪?传统模型的 “三大瓶颈”
风电预测看似是 “算发电量”,实则要应对复杂的物理与数据挑战,传统模型常陷入三大困境:
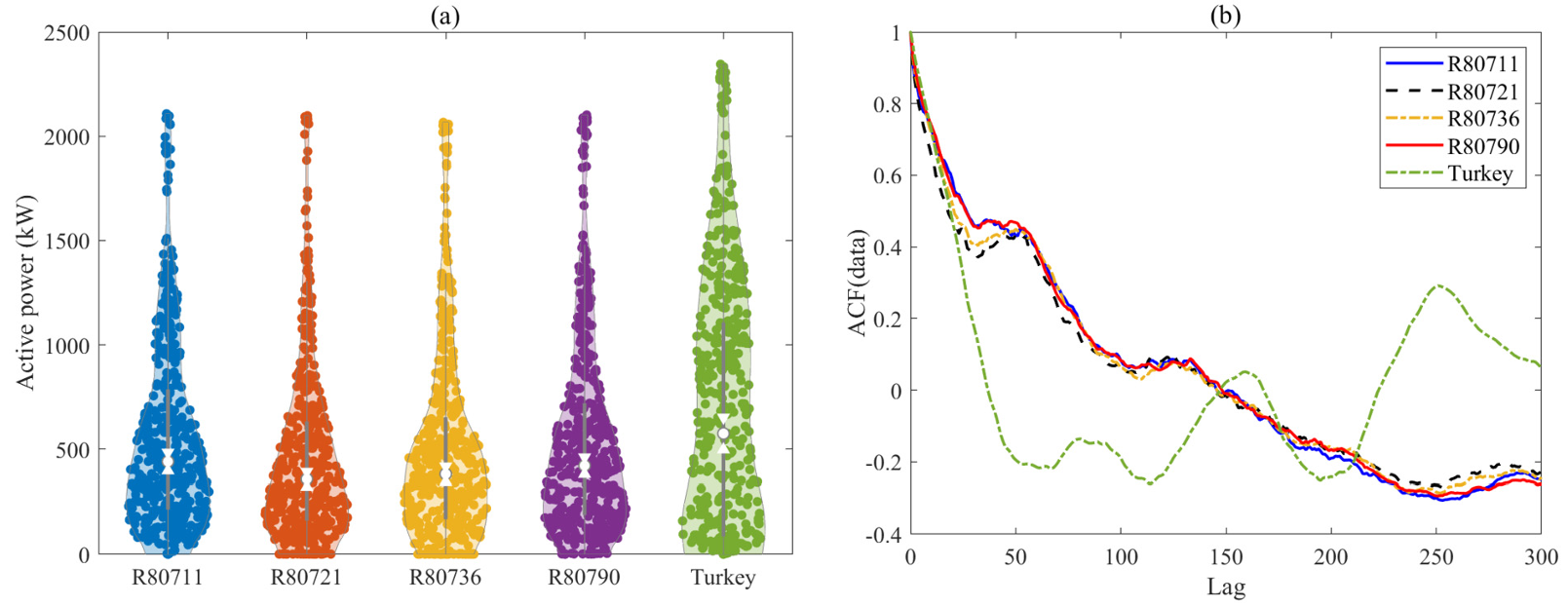
图1 风电数据小提琴图
非线性模式难捕捉:风速微小变化可能导致发电量大幅波动,且风电数据呈非高斯分布(如图 1,法国、土耳其风机数据分布无规律),传统 ARIMA 等线性模型难以拟合,误差常超 10%。
关键特征易遗漏:风机发电受 “历史功率、风速、湍流” 等多因素影响,LSTM、GRU 等模型虽能处理时序数据,但会平等对待所有时间步特征,忽略 “峰值功率时段”“风速骤变时刻” 等关键信息,导致预测偏差。
泛化能力差:某一区域训练的模型,换至其他风电场(如法国模型用在土耳其),因地理环境差异,预测精度会骤降 20%-30%,难以适应不同风况。
以江苏某风电场为例,曾用 LSTM 模型预测,因未关注 “风速骤降前 10 分钟” 的关键特征,导致某次功率低谷预测误差达 25%,造成电网调峰困难。
二、SA-VAE 的核心创新:让模型 “聚焦关键、精准预测”
SA-VAE 将变分自动编码器(VAE)的时序建模能力与自注意力机制的特征筛选能力结合,从 “数据处理、特征提取、预测优化” 三环节突破瓶颈,核心公式与设计如下:
2.1 VAE 基础:捕捉数据深层分布
VAE 通过 “编码器 - 解码器” 架构,学习风电数据的概率分布,核心损失函数为:
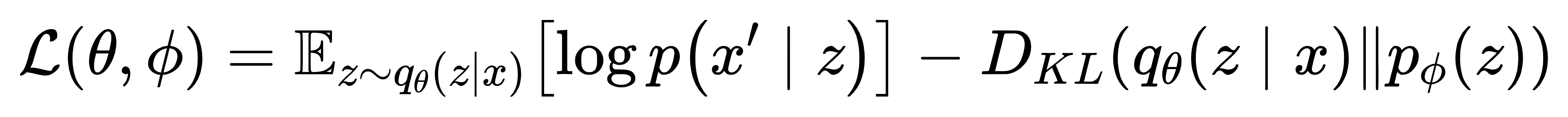
其中第一项是重构损失,确保解码器能从 latent 变量z还原原始风电数据;第二项是 KL 散度,约束 latent 空间分布接近标准正态分布,避免过拟合。
这一步的关键作用是:将杂乱的风电数据(如 10 分钟间隔的功率值)压缩为低维 latent 变量,捕捉 “风速 - 功率” 的深层非线性关系,比传统时序模型更能适应数据的非高斯特性。
2.2 自注意力机制:锁定关键特征
为解决 “特征平等对待” 问题,SA-VAE 在编码器和解码器中加入自注意力机制,计算特征权重:
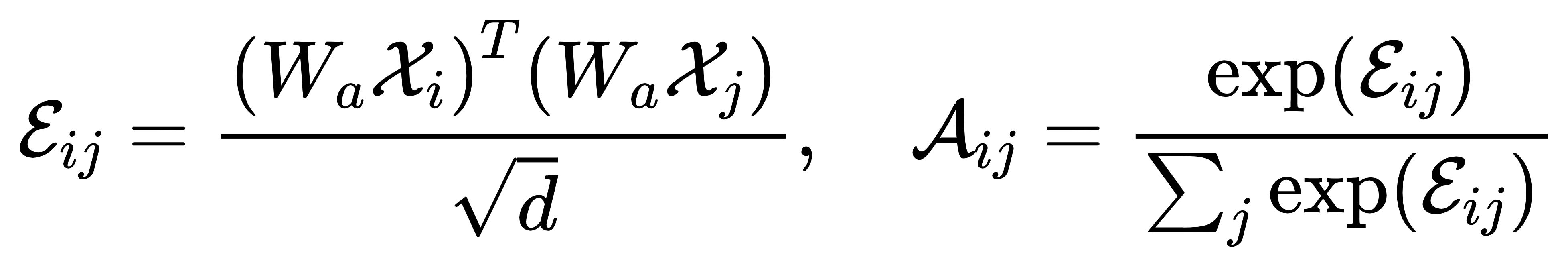
ℰij是特征i与j的关联分数,𝒜ij是归一化后的注意力权重。例如,当处理 “风速骤降” 数据时,模型会给 “骤降前 10-20 分钟” 的特征更高权重,优先捕捉关键变化。
最终注意力输出:
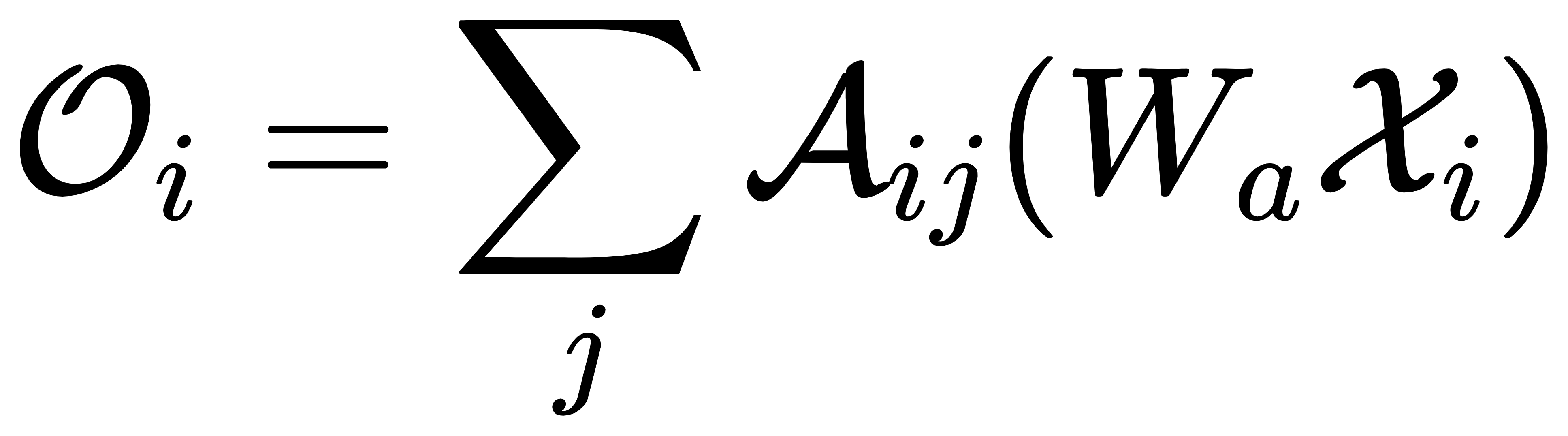
能强化重要特征、弱化冗余信息,让模型聚焦影响发电量的核心因素。
2.3 两阶段训练:兼顾泛化与精度
SA-VAE 采用 “无监督预训练 + 有监督微调” 两阶段流程:
第一阶段:用无标签风电数据训练 VAE,学习数据分布,生成高质量 latent 变量,无需依赖人工标注,降低数据需求;
第二阶段:用少量有标签数据微调模型,建立 “latent 变量 - 未来功率” 的映射关系,提升预测精度。
这种流程让模型在数据稀缺场景(如新建风电场)也能生效,泛化能力比纯监督模型提升 30% 以上。
三、实验验证:数据见证 SA-VAE 的 “超能力”
表1 土耳其风机预测结果
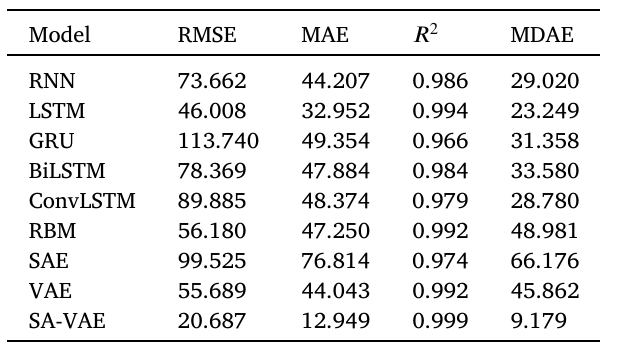
团队用法国 4 台风机(R80711 等)和土耳其 1 台风机的真实数据测试,对比 RNN、LSTM、XGBoost 等 8 种模型,结果令人惊艳:
3.1 预测精度:碾压主流模型
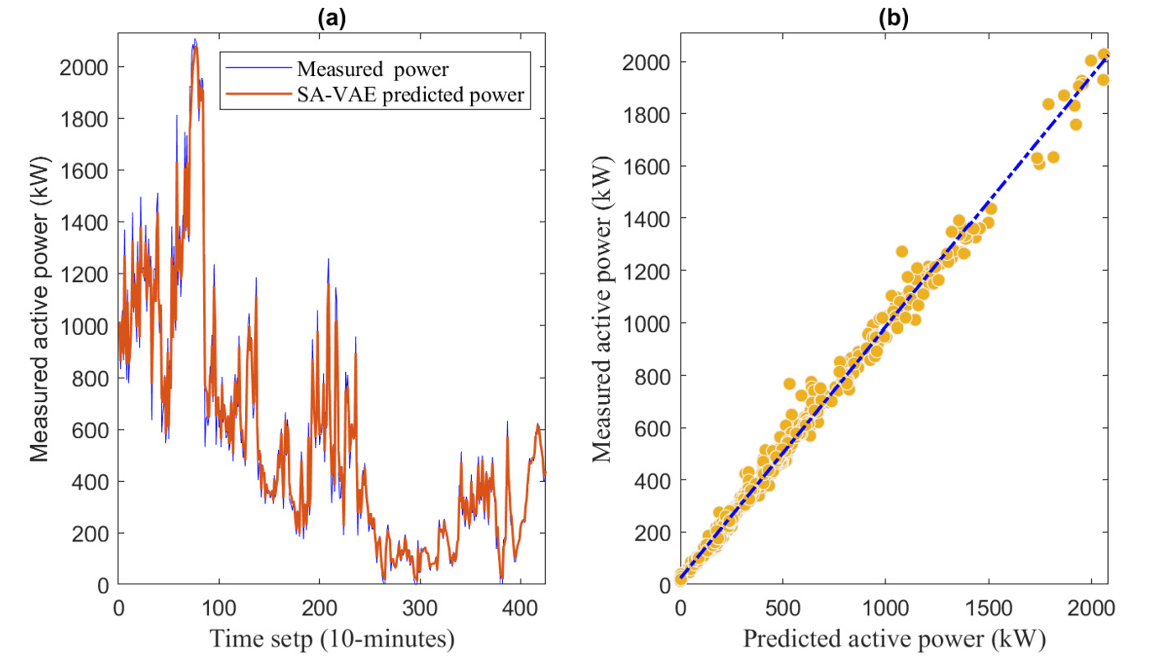
图2 SA-VAE 预测与实际功率对比
在土耳其风机数据中(表 1),SA-VAE 的 RMSE 仅 20.687,远低于 LSTM 的 46.008、RNN 的 73.662;(R2)值达 0.999,意味着模型能解释 99.9% 的功率变化,预测曲线与实际值几乎重合(如图 2)。
即使在法国风电场,SA-VAE 也表现稳定:以 R80711 风机为例,其 RMSE 仅 41.95,比传统 VAE 低 12%,(R2)达 0.992,远超 XGBoost 的 0.962、随机森林的 0.974。
3.2 抗干扰能力:误差波动最小
实验结果表明,SA-VAE 的误差分布最集中,MDAE(中位数绝对误差)仅 19.675,比 ConvLSTM 的 35.914 低 45%。这意味着即使遇到 “极端风速”“设备临时故障” 等异常情况,SA-VAE 也能保持稳定预测,不易出现大幅偏差。
3.3 泛化能力:跨区域仍精准
将法国训练的 SA-VAE 模型直接用于土耳其风机,R^2仍达 0.987,仅比同区域训练低 0.5%;而 LSTM 模型跨区域后R^2骤降至 0.92,差距显著。这说明 SA-VAE 学习的是风电数据的通用规律,而非单一区域的特殊模式。
四、落地价值:给风电行业带来什么?
SA-VAE 的突破不仅是技术进步,更能解决实际工程问题:
电网调度更高效:预测精度提升后,电网可提前调整火电、储能出力,减少弃风率。以某百万千瓦级风电场为例,SA-VAE 能让弃风率从 8% 降至 3%,每年多利用风电 1.2 亿度;
运维成本更低:精准预测可指导运维人员在 “低功率时段” 检修设备,避免高峰时段停机,某风电场因此每年减少运维损失 200 万元;
新场建设更省心:新建风电场缺乏历史数据时,SA-VAE 可通过无监督预训练快速适配,缩短模型部署时间从 3 个月至 2 周。
五、未来方向:让预测更智能
团队在研究中也指出,SA-VAE 仍有优化空间:未来可融入 “数值天气预报(NWP)” 数据,结合风速、风向等气象信息进一步提升精度;同时探索 3D 注意力机制,捕捉不同风机间的空间关联,适配大规模风电场集群预测。
六、总结
SA-VAE 的核心价值,在于用 “VAE 捕捉分布 + 自注意力聚焦关键” 的组合思路,打破了传统风电预测 “精度低、泛化差” 的瓶颈。其 99.2% 的平均(R^2)值,不仅是数字的突破,更标志着风电预测从 “粗略估算” 迈向 “精准可控”,为风电大规模并网、电网碳中和转型提供了关键技术支撑。
随着 SA-VAE 的推广,未来我们或许能看到:每座风电场都有 “精准预测大脑”,风电像火电一样稳定可控,真正成为能源结构的核心支柱。
论文原文:Enhancing wind power prediction with self-attentive variational autoencoders: A comparative study - ScienceDirect | 





















