|
蛋白设计新范式!MAESD 多智能体框架,让自然语言直接指导蛋白序列设计
在生物医学研究和工业生物技术领域,蛋白设计是核心研究方向之一,其成果为创新酶、治疗性蛋白和工业生物催化剂的开发奠定基础。传统蛋白设计方法高度依赖专家的生物学知识输入,普通研究者难以涉足,而现有 AI 辅助手段也未能彻底解决语义鸿沟、生物合理性验证不足等问题。
江南大学、上海交通大学等团队联合研发的MAESD(多智能体进化蛋白序列设计框架)为解决这些痛点提供了新方案,该框架将大语言模型的自然语言理解能力与进化计算结合,以自然语言指令为导向,实现了受功能和结构约束的蛋白序列进化设计,相关研究发表于《Journal of Chemical Information and Modeling》。

蛋白设计的困境:高门槛与技术瓶颈并存
蛋白设计的传统方法主要分为理性设计和定向进化两类,二者均需研究者具备深厚的分子生物学、结构分析和实验设计功底。理性设计依赖结构数据对蛋白序列进行靶向修饰,但受限于对蛋白结构和作用机制的理解不完整,常产生无功能蛋白;定向进化模拟自然选择提升蛋白功能,却存在实验效率瓶颈,二者都为非专业研究者设置了高门槛。
近年来,机器学习为蛋白设计带来变革,ProGen2、ProteinMPNN、AlphaFold2 等模型相继出现,多智能体系统和大语言模型也推动了自主蛋白设计的发展。但即便如此,现有 AI 辅助方法仍高度依赖专家知识,研究者不仅需要生物医学专业能力,还需掌握深度学习和编程技能,同时还存在三大核心挑战:一是对专家知识的依赖度仍居高不下,排除了无计算背景的研究者;二是自然语言与生物表征之间的语义鸿沟尚未解决;三是多目标优化能力不足,生物合理性验证有限,生成的序列常缺乏结构稳定性和功能必要性验证。
为突破这些瓶颈,研究团队首先提出了蛋白进化范式,以自然蛋白进化的核心逻辑为灵感,确立了功能导向初始化、迭代生成 - 验证 - 选择、保留生物合理性三大核心原则,为后续框架搭建奠定了理论基础。
MAESD 核心架构:两大模块,让自然语言对接蛋白设计
MAESD 是一个统一的自动化计算框架,核心由意图识别智能体(IRA,语义-生物翻译模块)和进化循环模块两大协作单元构成,实现了从自然语言指令到优化蛋白序列的全流程转化,同时引入结构参考信息为验证和筛选提供支撑,且仅将其用于约束和评估进化优化过程,而非直接复制序列模板。
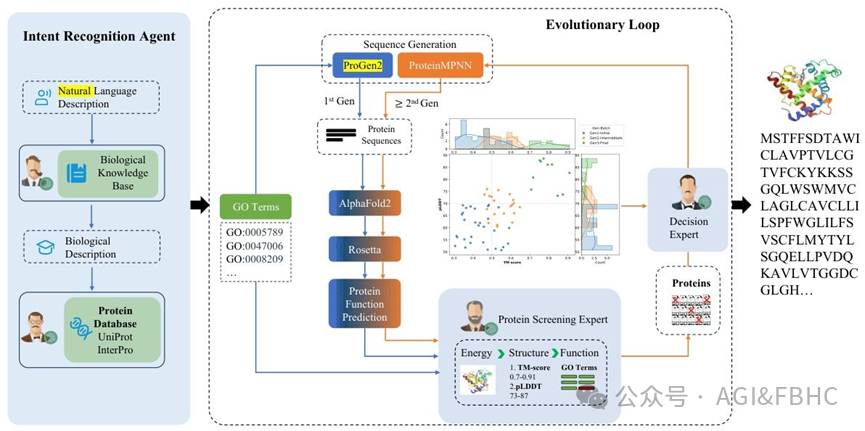
图1 MAESD 架构包含两个核心模块:左侧为意图识别智能体,该模块通过调用Uniprot、Pfam、InterPro 等生物数据库,将自然语言描述转化为蛋白结构域配置;右侧为进化循环模块,该模块整合 ProGen2、ProteinMPNN、AlphaFold2 等工具,通过对结构域组合进行多轮优化,实现蛋白序列的迭代优化与筛选.
意图识别智能体:破解自然语言与生物约束的语义鸿沟
这一模块是 MAESD 的 “翻译官”,能将用户输入的自然语言生物需求,转化为可执行的蛋白设计生物约束条件,彻底改变了传统方法依赖专家构建结构输入的现状。
其工作流程分为多步:先调用 ChatGPT-4、DeepSeek-V3 等大语言模型对自然语言输入进行语义分割,过滤掉与蛋白设计无关的噪声,提取出生物学相关术语;再借助 Uniprot、Pfam、InterPro 等生物数据库,对术语进行域特异性语义扩展和匹配域检索,生成候选蛋白结构域组合;最后由 MAESD 的决策专家智能体验证这些组合的功能一致性,确保与用户设计意图匹配。
过程中还会计算每个结构域的位置倾向得分和域排列的累积位置偏差得分,让域排列更符合天然蛋白的特征,为后续序列生成提供精准的初始约束。
进化循环模块:迭代优化,守住蛋白的生物合理性
如果说意图识别智能体是 “定方向”,进化循环模块就是 “磨细节”,通过生成 - 验证的闭环循环实现蛋白序列的渐进式优化,由序列生成、蛋白筛选、最终决策三大核心功能单元组成,所有参数适配和工具调用均由智能体自主完成,大幅减少人工调参需求。
1. 序列生成:双模型协作,兼顾多样性与结构完整性
以意图识别智能体确定的结构域组合为初始输入,先由 ProGen2 完成初始序列生成,将验证后的蛋白结构域片段作为固定锚点,生成连接区域并产生多种序列变体,保证初始多样性;在后续进化迭代中,切换至结构导向探索阶段,由ProteinMPNN以 AlphaFold2 预测的结构为支架,对前序筛选出的序列进行全骨架优化,既实现序列空间的全面采样,又保留核心结构完整性。
2. 蛋白筛选:分层验证,让功能筛选更精准、更客观
蛋白筛选智能体是进化循环的核心,研究团队创新性提出结构导向的分层功能筛选(**SGHFS)**策略,打破了加权指标的局限性,按照 “核心功能位点→结构微环境→全局功能构象” 的生物优先级进行序贯验证,遵循严格的 “非补偿逻辑”—— 任一筛选层失败即被淘汰,无需主观设置权重,所有阈值均基于 PDB 结构数据确定,可完全复现。
·核心功能位点筛选:作为蛋白功能的 “必要条件”,先通过 TM-align 工具完成设计蛋白与天然模板的全局结构比对,计算功能位点匹配度(FSM),FSM≥0.7 的序列才可进入下一环节,这一阈值能保证蛋白保留 90% 以上的功能位点;
·结构微环境筛选:聚焦核心功能位点周边 5Å 的球形区域,识别氢键、疏水相互作用、盐桥三类关键非共价相互作用,计算结构微环境合理性(SMR),SMR≥0.6 的序列可继续筛选,确保核心位点有稳定的局部支撑;
·全局功能构象筛选:计算二级结构匹配率、二硫键保留率等四个与功能可及性相关的指标,取平均值得到全局构象完整性(GCI),GCI≥0.6 的序列被保留,保证核心功能位点的可及性。
整个 SGHFS 流程由 MAESD 的多智能体系统协同完成,无需任何人工干预,筛选出的序列功能成功概率超 70%,还能根据筛选失败原因实现靶向反馈,让后续进化迭代更具针对性。
此外,筛选过程还会结合 TM-score、pLDDT 评估结构合理性,通过 Rosetta 计算能量得分并对低能量序列进行骨架构象松弛,从结构、能量、功能三个维度全面验证。
3. 最终决策:帕累托前沿选择,兼顾多目标与灵活性
进化循环以 100-200 条候选序列为初代种群,每一轮迭代后,采用基于帕累托前沿的多目标选择策略,筛选出在结构、能量、功能指标上均无劣势的非支配解,作为下一轮迭代的亲本候选。
默认迭代 5 轮后终止(可按需调整),将最终的非支配解集作为候选集,用户可根据自身需求(如功能活性优先、结构稳定性优先)选择最优序列。这种设计既通过迭代优化保证了序列的结构完整性和功能有效性,又为用户提供了灵活的选择空间,实现了蛋白序列空间的高效探索。
进化优化的 “智慧调节”:突变策略与参数自适应
为让进化迭代更高效,MAESD 设计了针对性的突变策略和进化参数自适应规则,深度耦合多智能体协作框架和 SGHFS 筛选机制。
在突变位点的选择上,首先避免突变核心功能位点,优先选择AlphaFold2预测结构中pLDDT<70的区域。同时,为了保持序列多样性,还会为非核心区域分配部分突变位点。若序列未通过SGHFS筛选,系统将根据筛选失败的具体原因,进行相应的调整。突变过程还会结合SGHFS结果和UniProt数据库中的同源蛋白信息,动态调整氨基酸偏好参数,从而提高关键氨基酸的选择权重。
进化参数方面,温度参数(调控序列多样性)、功能位点固定参数、氨基酸偏好参数均由智能体根据迭代反馈动态优化,形成 “生成 - 评估 - 参数优化” 的闭环,让进化过程始终贴合设计目标。
实验验证:MAESD 全面优于基线模型,兼具性能与创新性
研究团队在由 UniProtKB/Swiss-Prot、Pfam-A Seed、PDB 构建的数据集上对 MAESD 进行了全面验证,对比了 GPT-4、DeepSeek-V3、ProtAgents、ProGen2 等多个基线模型,从结构、功能、序列特征等多维度评估其性能。
结构更合理:高置信度与模板相似性兼备
MAESD(结合 GPT-4/DeepSeek-V3)生成的蛋白序列,经 AlphaFold2 预测的 pLDDT 分别达 89.3、91.5,TM-score 达 0.682、0.679,远高于 GPT-4、DeepSeek-V3 等基线模型,甚至优于 ProtAgents。这表明 MAESD 设计的蛋白具有高结构置信度,且与天然蛋白的结构相似度显著,同时还能保持与已知天然蛋白的可区分性,并非简单的模板复制。
功能更保守:匹配天然蛋白核心功能特征
以设计 “长链脂肪酸延伸循环限速酶” 为例,MAESD 生成的蛋白与 PDB 数据库中对应的人类脂肪酸延伸酶 ELOVL7(PDB ID:6Y7F)结构叠合的 RMSD 仅 1.69Å,跨膜结构域、底物结合口袋等核心功能区域高度保守,同时在其他区域与天然蛋白存在差异,实现了 “功能保守、结构新颖” 的设计目标。
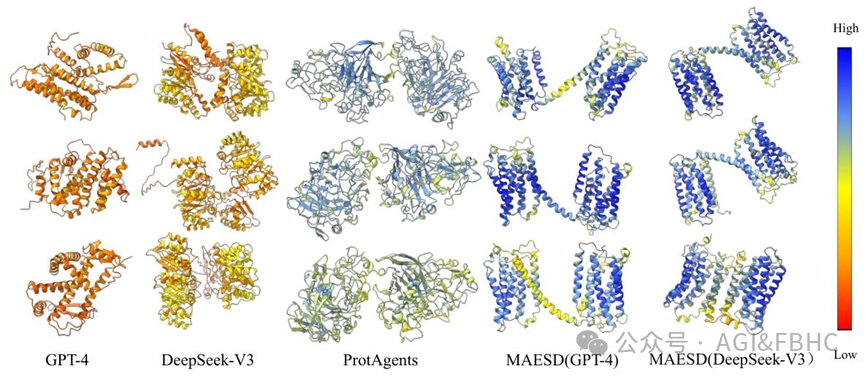
图2 不同模型设计蛋白的结构可视化对比.
序列更优质:多样、新颖且符合生物特征
对 MAESD 生成的 100 条序列进行分析发现,其与天然同源蛋白的平均序列一致性约 65.5%,且分布范围广,未出现序列坍缩;同一条自然语言指令生成的序列间平均一致性仅 61%,仅 2% 的序列对一致性超 80%,证明 MAESD 能在满足功能和结构约束的前提下,保持序列多样性。
同时,MAESD 生成的蛋白氨基酸组成与天然蛋白高度契合,无明显的组成偏倚,在结构相似性与序列分歧之间实现了良好平衡,符合天然蛋白的进化规律,具备高度的生物合理性。
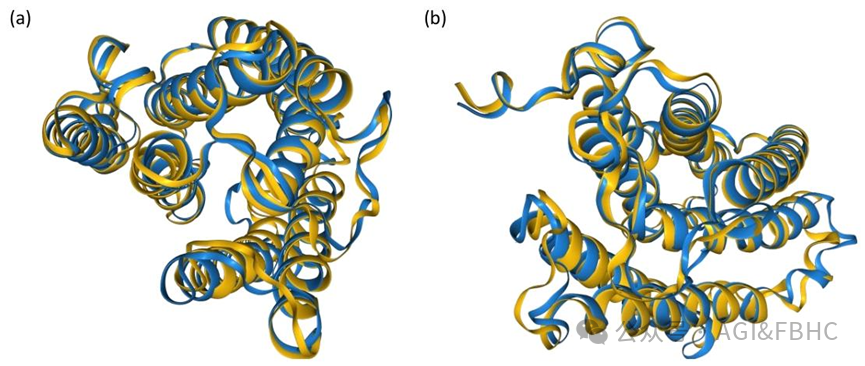
图3 子图 a 和子图 b 为示意图,展示了 6Y7F 蛋白与两款全新设计蛋白的结构比对情况,该两款全新设计蛋白是基于 6Y7F 的主要功能描述而构建的.
模块不可替代:各单元协同支撑框架性能
消融实验结果显示,移除意图识别智能体(IRA)、蛋白筛选专家(PSE)、决策专家(DE)、进化循环(EL)任一模块后,MAESD 的各项性能指标均出现显著下降,其中 IRA 的移除会导致功能保守得分(FCS)从 69.6 骤降至 26.2,说明精准的初始生物约束是后续迭代优化的基础,各模块的协同作用是 MAESD 高性能的关键。
此外,语义 - 生物翻译测试显示,MAESD 的 IRA 在将自然语言转化为 GO 术语、识别蛋白结构域方面的精确率、召回率、F1 值均远超 GPT-4、BioMedLM 等基线模型;进化循环模块在迭代 5 轮后,设计性能显著优于 ProGen2、ProteinMPNN,证明了迭代优化的价值。
展望与未来:从计算设计到实验验证,持续降低研究门槛
MAESD 的出现,将自然语言处理与进化计算深度融合,实现了蛋白设计流程的自动化,大幅降低了对专家知识和计算技能的依赖,让更多非专业研究者能够参与到蛋白设计研究中。该框架的代码和相关数据集已开源,为领域研究提供了重要的工具支撑。
当然,MAESD 目前仍存在一定局限性,其功能实现仍依赖大语言模型理解自然语言指令,且尚未开展湿实验验证。研究团队表示,未来将围绕三大方向继续优化:一是构建全面的生物知识图谱,提升术语理解能力,减少语义模糊性,降低对大语言模型的依赖;二是采用更快的算法替代现有结构预测方法,提升计算效率,减少资源消耗;三是开发自优化提示词,强化多智能体间的协作,进一步减少人工干预。同时,湿实验验证也将纳入后续研究,通过实验验证设计蛋白的实际功能,让计算设计与实验应用更好地结合。
从 “专家专属” 到 “自然语言直达”,MAESD 为蛋白设计领域打开了新的大门。随着技术的不断优化和实验验证的推进,这一多智能体进化框架有望在酶工程、抗体研发、工业生物催化等领域发挥重要作用,为生物医学和生物技术的创新发展注入新动能。
论文信息
论文题目:MAESD: A Unified Multi-Agent Evolutionary Framework for Protein Sequence Design
发表期刊:Journal of Chemical Information and Modeling, 2026, DOI: https://doi.org/10.1021/acs.jcim.5c02580
作者:Ze Song, Hailong Yang, Zhaohong Deng, Xiaoyong Pan, Hongbin Shen, Shudong Hu, Yanqi Zhong
研究团队:来自江南大学人工智能与计算机学院、上海交通大学、江南大学附属医院的研究人员
代码开源:https://github.com/nnnnnnz/MAESD
本研究得到国家自然科学基金(62176105)的资助,是团队在蛋白质工程与人工智能交叉领域的最新成果。未来,AGI&FBHC 团队将继续深耕生物信息学与 AI 的融合研究,推出更多高效、实用的算法模型,为生命科学研究提供更强的 AI 支撑。
文章转载自微信公众号:AGI&FBHC
原文链接:https://mp.weixin.qq.com/s/kVTEg92hJVNL01XxZIHIzw?mpshare=1&scene=1&srcid=0312nTACGDEN5prE0ZRAUuuD&sharer_shareinfo=7cf647676ca590e9a8212a51d37a92ea&sharer_shareinfo_first=7cf647676ca590e9a8212a51d37a92ea&from=industrynews&color_scheme=light#rd | 





















