本帖最后由 离子 于 2026-5-15 14:55 编辑
本文解读Cell 2026的研究《 D-SPIN constructs regulatory network models from scRNA-seq that reveal organizing principles of perturbation response 》,推出全新计算框架D-SPIN(维度可扩展单细胞扰动整合网络),直接从大规模单细胞 RNA-seq 扰动数据中构建可解释、可生成、可模拟的基因调控网络(GRN)模型。该框架统一刻画基因 / 基因程序间的调控关系,并量化基因敲低、药物处理等外部扰动如何改变细胞状态分布。在 K562 细胞大规模 Perturb-seq 数据中,D-SPIN 精准识别红系–髓系命运关键调控因子;在免疫细胞药物扰动数据中,它揭示药物组合通过叠加招募基因程序产生全新细胞状态,并能仅用少量组合实验插值预测任意剂量组合的细胞状态相图。D-SPIN 为发育调控、药物机制、免疫干预与细胞工程提供统一、可落地的网络建模新范式。

基因调控网络是细胞的 “信息处理中枢”。它决定细胞在发育中走向何种命运、在外界刺激下如何响应、在药物作用下转向哪种状态。长期以来,想要从组学数据里把这套 “电路” 画出来,一直是生物学与计算生物学的最高难度挑战之一。传统方法要么只能找相关性,不能构建可模拟的动力学模型;要么只能分析少量基因,无法扩展到全转录组;要么依赖染色质开放、基序信息,不能只从单细胞表达数据出发。
随着 Perturb-seq 等技术成熟,我们已经能在数百万个单细胞里、同时观测数千种基因敲低或药物处理的转录响应。但海量数据背后的调控逻辑依然是黑箱:一个扰动究竟激活了哪些通路、抑制了哪些程序、如何推动细胞状态改变、两种药组合会发生协同还是拮抗…… 这些问题,传统 UMAP 降维、差异基因分析根本回答不了。
现在,发表在Cell的 D-SPIN 框架彻底改变游戏规则。它不只是一个分析工具,而是一套能把单细胞扰动数据翻译成调控电路图的统一理论。它能自动学习基因之间的激活 / 抑制关系,能模拟细胞状态分布,能预测未做过的药物剂量组合,还能精准揪出控制细胞命运的核心开关。
一、为什么我们需要 D-SPIN:从数据到机制的巨大鸿沟
在单细胞测序时代,我们早已不缺数据。以 Perturb-seq 为例,一次实验就能敲除近万个基因,测数百万细胞,得到海量表达矩阵。但这些数据停留在描述层面,很难上升到机制层面。
第一个难题是隐藏调控关系。很多基因在正常条件下相关性极低,它们的调控被其他通路掩盖,只有在特定敲除或药物扰动下才会暴露。传统方法基于静态相关性,根本看不见这些 “隐藏边”。
第二个难题是无法建模状态分布。细胞群体不是平均表达,而是由多种状态按比例组成。扰动改变的是比例,不是单个基因。传统网络方法无法模拟这种概率分布变化。
第三个难题是不可生成、不可预测。大多数 GRN 方法只能 “事后解释”,不能生成细胞状态、不能模拟扰动、不能预测新药组合效果。而真正有用的模型必须能推演未知。
第四个难题是扩展与解释不可兼得。深度学习可以拟合数据,但像黑箱;物理模型可解释,但扩不成上千基因。D-SPIN 第一次做到:大尺度、可解释、可生成、可扰动四者合一。
D-SPIN 的核心思想非常清晰:用统一的调控网络,解释所有扰动下的所有细胞状态;用扰动数据,反推出被隐藏的真实调控关系。
二、D-SPIN 核心框架:从单细胞扰动到可模拟调控网络
D-SPIN 的输入很简单:多条件下的单细胞转录组数据,可以是 CRISPR 敲除、药物处理、信号刺激、疾病状态等。它的输出更强大:一个统一的基因调控网络 + 每个扰动对网络的作用向量。
2.1 统一网络 + 条件扰动
D-SPIN 假设:
所有扰动(敲除、药物、刺激)都不改变核心调控网络本身,只是通过改变网络中节点的激活强度,让细胞状态分布发生偏移。
这是一个高度贴近真实生物学的假设:药物不重写调控线路,只是按下不同开关。
数学上,D-SPIN 构建自旋网络模型(来自统计物理),用能量函数描述细胞状态的概率分布:
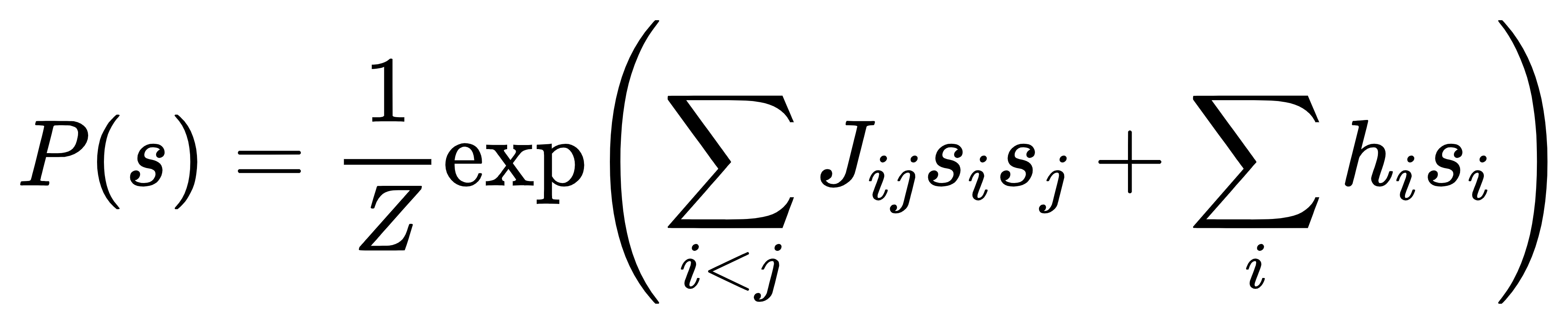
其中,si代表基因 / 程序的激活、抑制、中性状态,Jij是调控相互作用(正 = 激活,负 = 抑制),hi是外部扰动输入(药物 / 敲低的作用),Z 是归一化常数。
这个公式决定了:每一种细胞状态出现的概率。D-SPIN 的任务就是从数据中把J(网络)和h(扰动)全部学出来。
2.2 从基因到程序:双层网络更易解释
直接对几千个基因建模过于复杂,D-SPIN 自动用正交非负矩阵分解(oNMF)把基因聚成基因程序—— 也就是功能模块,比如核糖体、周期、剪切、免疫激活、红系分化、M2 巨噬等。
于是 D-SPIN 形成两套网络:
1.程序层网络:看功能模块之间如何协作、拮抗、维持稳态;
2.基因层网络:看转录因子、激酶、磷酸酶如何控制程序。
两套网络相互对应,既宏观又精细,完美兼顾可扩展性与可解释性。
2.3 三大创新能力
1.从扰动中挖掘隐藏调控:只有扰动能把被掩盖的抑制 / 激活关系暴露出来;
2.真正可生成:能模拟任何扰动下的细胞状态 UMAP 与比例;
3.高度可扩展:能处理百万细胞、千种扰动、千级基因。
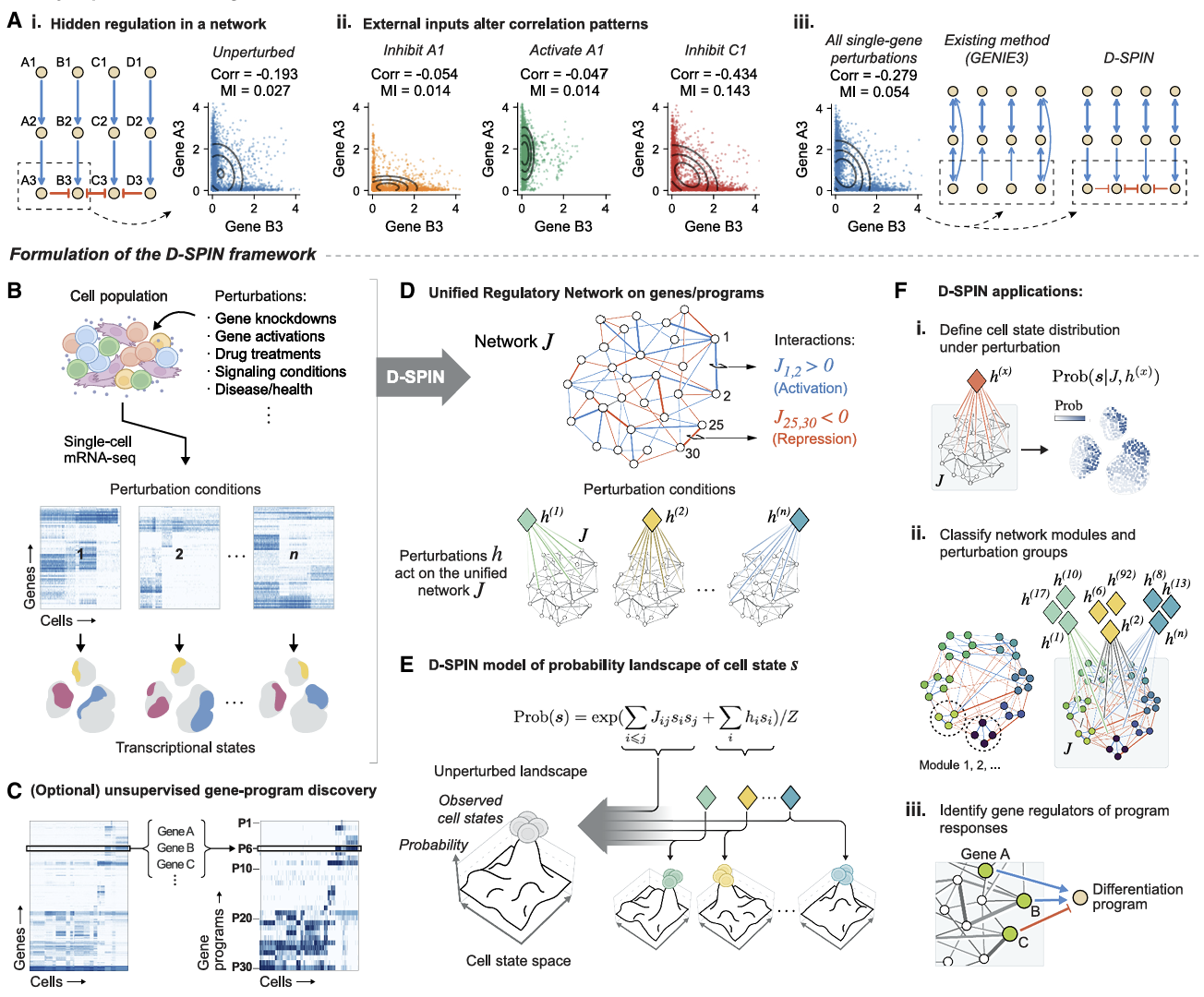
图 1 D-SPIN从单细胞扰动数据构建统一基因调控网络并模拟细胞状态分布
三、D-SPIN 重构精准调控网络,远超现有方法
研究团队在人造基准网络与真实单细胞数据上做了全面测试。
在人造的造血干细胞分化网络中,D-SPIN 重建调控边的 AUPRC 高达0.87,定向网络准确率0.77,远高于 GENIE3、GRNBoost2、PIDC 等主流工具。它不仅更准,还能正确推断调控方向,这是大多数工具做不到的。
在更大规模的模拟网络中(模块化、随机、无标度),随着扰动数量增加,D-SPIN 准确率持续上升,最高接近0.94,而传统方法几乎停滞。这证明:D-SPIN 真正在利用扰动信息,而不只是表达相关性。
速度方面,D-SPIN 在百万细胞量级上比其他方法快几个数量级,是唯一能处理超大规模 Perturb-seq 的网络模型。
更关键的是,在真实 K562 Perturb-seq 数据中,D-SPIN 推断的调控网络与ChIP-seq 实验高度吻合,早期精度是随机的11–15 倍,即便不使用任何基序或染色质开放数据,依然超过依赖先验的工具。
这意味着:D-SPIN 仅凭单细胞表达,就能画出接近实验金标准的调控网络。
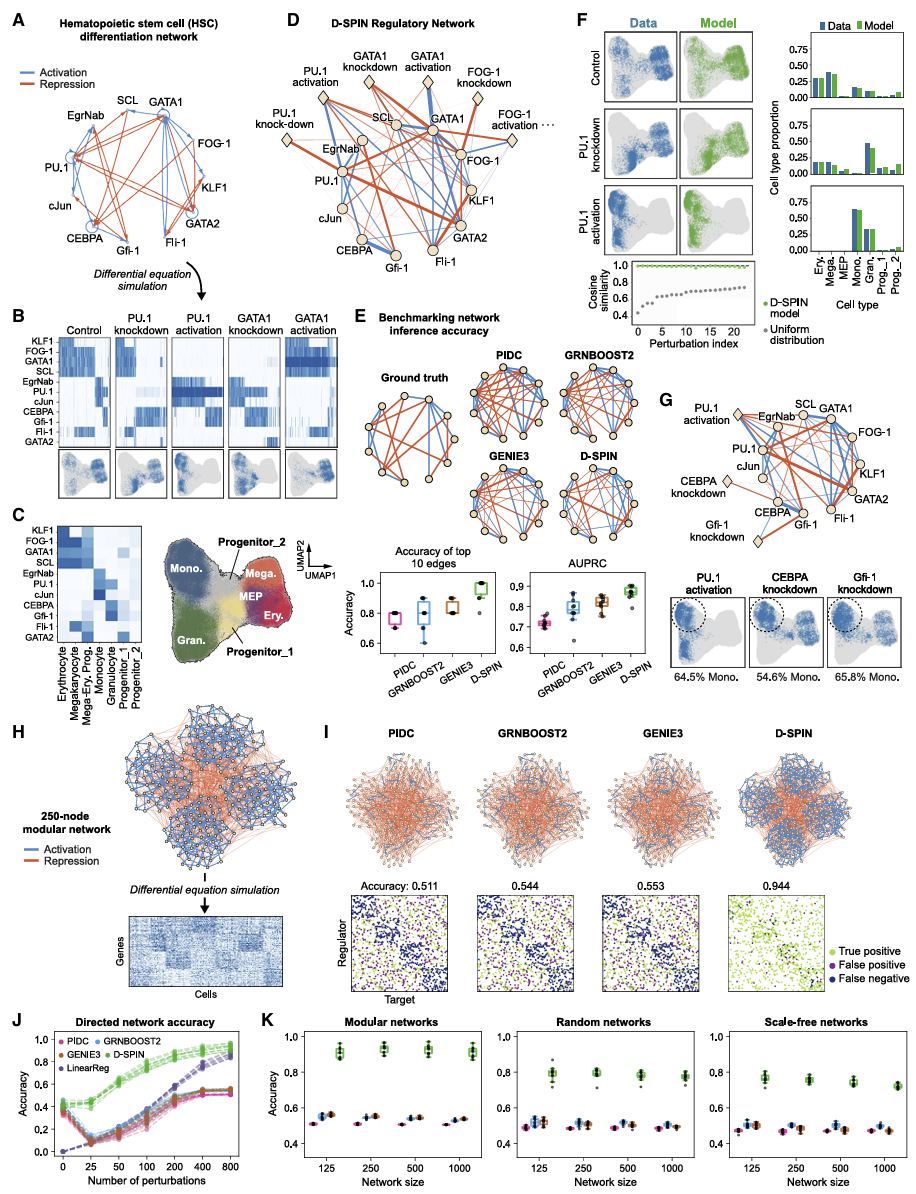
图 2 D-SPIN 在定向 / 非定向调控网络推断上显著优于现有方法
四、解码 K562 细胞全局调控架构:扰动揭示稳态策略
研究把 D-SPIN 用在目前最大规模的 K562 Perturb-seq 数据(9867 个基因敲除,200 万细胞),得到惊人的全局图景。
D-SPIN 自动把转录组聚成30 个基因程序,对应转录、翻译、周期、DNA 复制、蛋白酶体、RNA 剪切、线粒体、红系、髓系等核心功能。然后构建程序间调控网络,发现网络高度模块化:同一模块内以激活为主,模块之间以抑制为主。
这种结构正是细胞稳态维持的物理基础:功能模块协同,不同功能相互制衡。
更震撼的是,D-SPIN 发现细胞面对扰动时,只会采取四种稳态策略:上调代谢、上调转录、上调翻译和上调降解。
每种策略都是 “损伤–补偿” 模式:比如敲低转录,细胞会上调代谢;敲低核糖体,细胞会上调整合酶。这是第一次在全转录组尺度看到细胞的全局应激调控逻辑。
同时,D-SPIN 直接定位红系–髓系命运的核心调控因子,包括 KLF1、GATA1、PU.1、NPM1 等,其中多个是传统差异分析完全找不到的。尤其重要的是,它发现 NPM1 通过核质转运抑制两者分化,解释了 BCR-ABL1 如何阻断分化,直接提供可药靶点。
五、免疫药物调控机制:组合用药通过叠加程序创造新状态
研究团队进一步建立了502 种免疫调节药物 + 150 万单细胞的大规模数据集,覆盖 T 细胞激活、巨噬细胞极化、抗炎、表观调控等。
D-SPIN 把复杂的免疫细胞分成28 种状态,并构建统一调控网络,然后自动把药物分成 7 类:强抑制剂、弱抑制剂、糖皮质激素、M1 诱导剂、表观修饰剂、毒性剂等。
每一类都有独特的程序响应:强抑制剂(达沙替尼、他克莫司)全面关闭免疫激活;糖皮质激素强烈诱导 M2 巨噬程序;TLR 激动剂特异性激活 M1 炎症程序;表观药物带来应激与破坏态。
最关键的发现是:药物组合通过 “叠加招募基因程序” 产生全新细胞状态。
例如,达沙替尼 + 卤倍他索组合,既抑制免疫,又强推 M2 程序,产生一种超抑制型巨噬细胞,单用任何一种药都得不到。
D-SPIN 从机制上证明,两种药通过完全独立的调控通路控制 M2 程序。Src 抑制剂通过 IRF1/CSF1R 通路,而糖皮质激素通过 TSC22D3/DUSP1/MAFB 通路。
因为通路不重叠,效果可以叠加。这是组合用药能产生新状态的根本原因。
六、颠覆性预测:仅用 1 组组合,插值全剂量相图
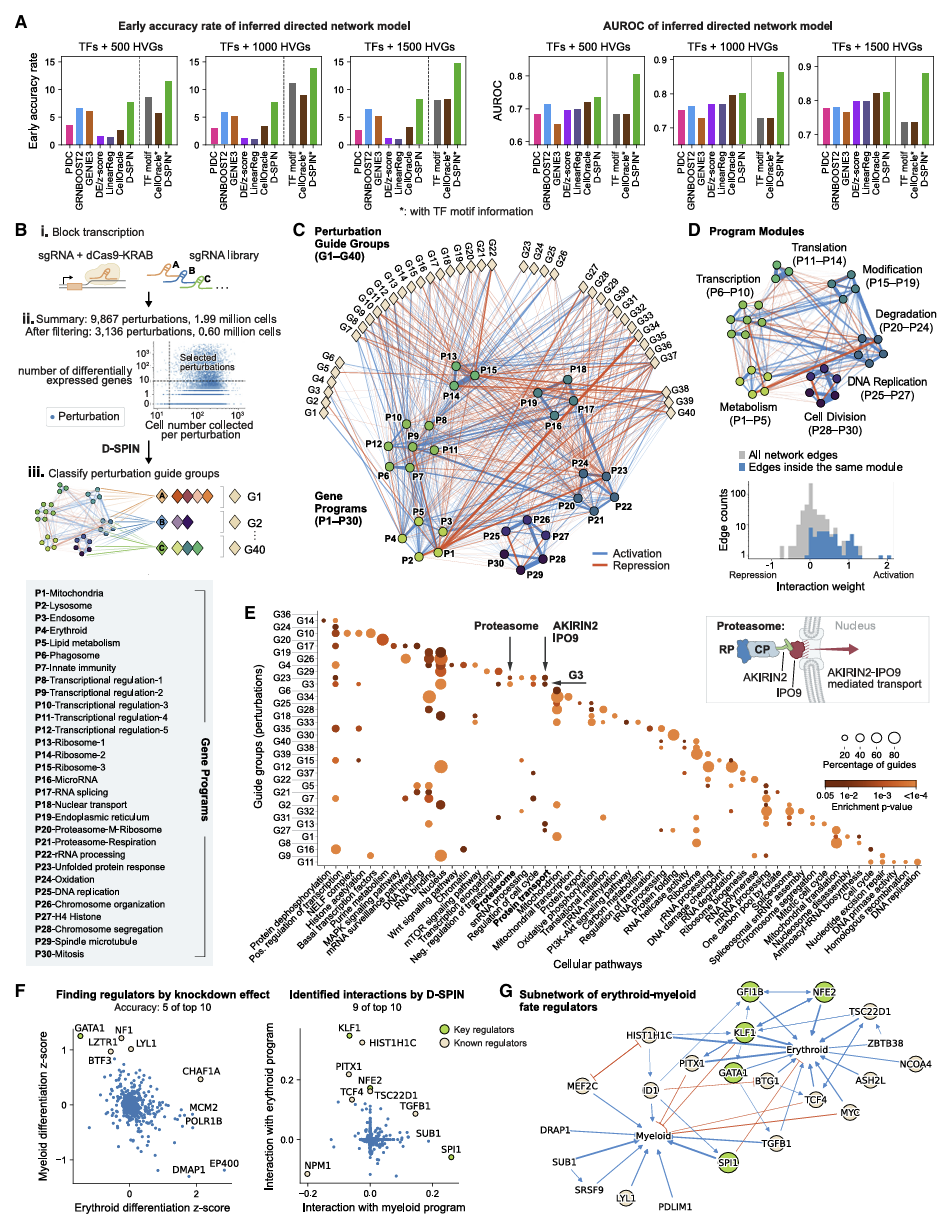
图 3 药物组合通过叠加基因程序产生新巨噬细胞状态及 D-SPIN 剂量相图插值预测
药物组合筛选成本爆炸,不可能试遍所有剂量。D-SPIN 给出终极方案:
只测单药 + 1 组饱和剂量组合 → 预测所有剂量的细胞状态。
模型用Sigmoid 叠加 + 互作项拟合程序响应:
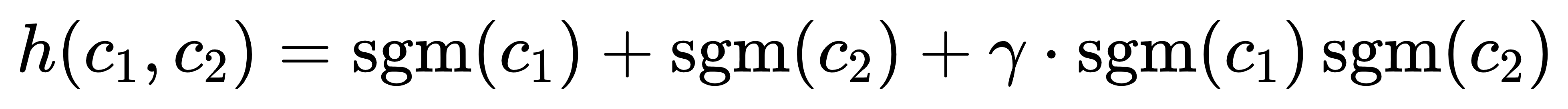
只要学出互作系数𝛾,就能插值整个剂量平面。
结果惊人:只用1 组组合,预测准确率从 0.72→0.84;能画出完整的巨噬细胞状态相图;准确捕捉 “超抑制 M2” 区域。
这说明未来组合用药筛选可以从百万次实验,降到十次以内。
七、科学意义:细胞调控从黑箱进入电路图时代
D-SPIN 的出现,标志着基因调控网络研究进入全新阶段。
第一,它不依赖额外组学,仅凭单细胞转录组与扰动,就能构建可模拟、可解释、可预测的调控网络。
第二,它统一了基因与程序、稳态与扰动、单药与组合,提供通用框架。
第三,它实现了从观测到预测的跨越,能推演未做过的实验,指导药物开发与细胞工程。
第四,它用统计物理模型提供了细胞稳态与命运转换的统一数学理论。
从发育生物学、肿瘤耐药、免疫治疗到合成细胞设计,D-SPIN 都能画出底层电路图,让细胞不再是黑箱。
八、总结
基因调控网络是细胞的核心操作系统,但长期无法从数据中系统解析。Cell 发表的 D-SPIN 框架,用统计物理模型与可扩展机器学习,实现了从大规模单细胞扰动数据到统一调控网络的端到端构建。
它能揭示隐藏调控、识别命运开关、分类药物机制、解释组合效应、预测剂量相图。在 K562 细胞中,它定位红系–髓系调控核心;在免疫细胞中,它阐明药物叠加创造新状态的机制;在计算效率与精度上,全面超越现有工具。
D-SPIN 不仅是一项技术突破,更是一套理解细胞如何处理信息、维持稳态、响应药物的基础理论。它让我们真正进入可建模、可模拟、可控制的细胞工程时代。
论文链接:https://www.sciencedirect.com/science/article/pii/S0092867426004630?via%3Dihub | 





















