本文系统梳理了L1与L2范数在机器学习中的数学定义、几何结构、梯度行为与优化效果,并结合现代深度学习场景,讨论了它们在模型稀疏性控制、参数稳定性、特征选择和网络压缩等方面的应用差异。通过对比两者在解空间、优化路径和实际任务中的表现,帮助读者从结构性视角理解正则化的内在机制。

1. 范数基础、L1与L2的数学定义与正则化动机
范数(norm)作为线性空间中度量“长度”与“规模”的基本工具,是许多机器学习模型构造与优化过程中的核心数学对象。在最常见的情形中,我们关心的是向量空间 Rn中某个向量 x=(x1,…,xn)的整体幅度或能量,而这正是范数提供的抽象度量。Lp 范数是一类形式统一、含义丰富的度量族,其一般定义为
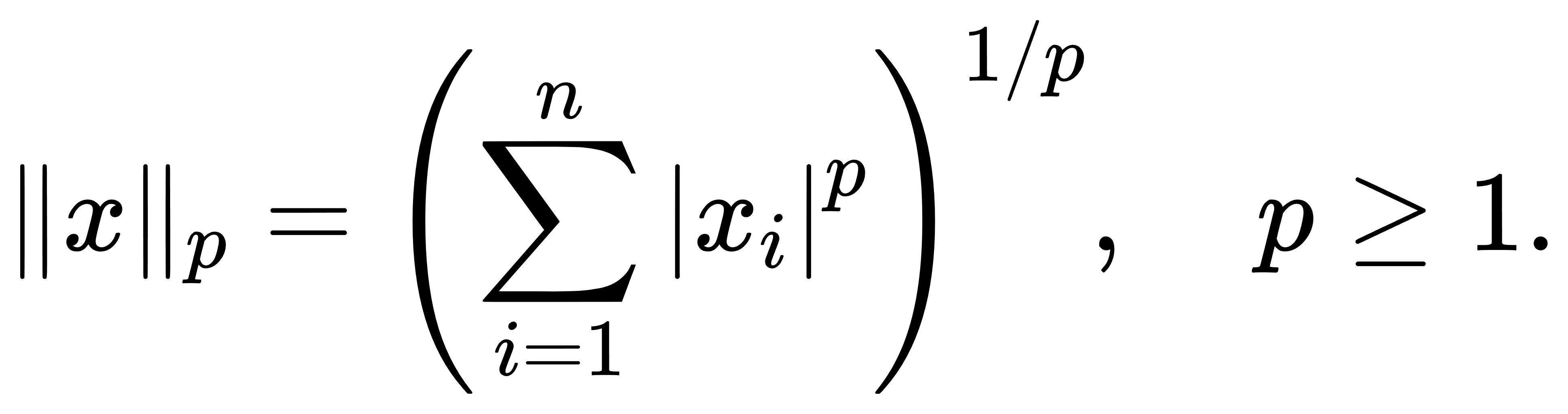
其中最常用的两个特殊情形即是 L1 范数与 L2 范数。前者为各个分量绝对值的总和,即
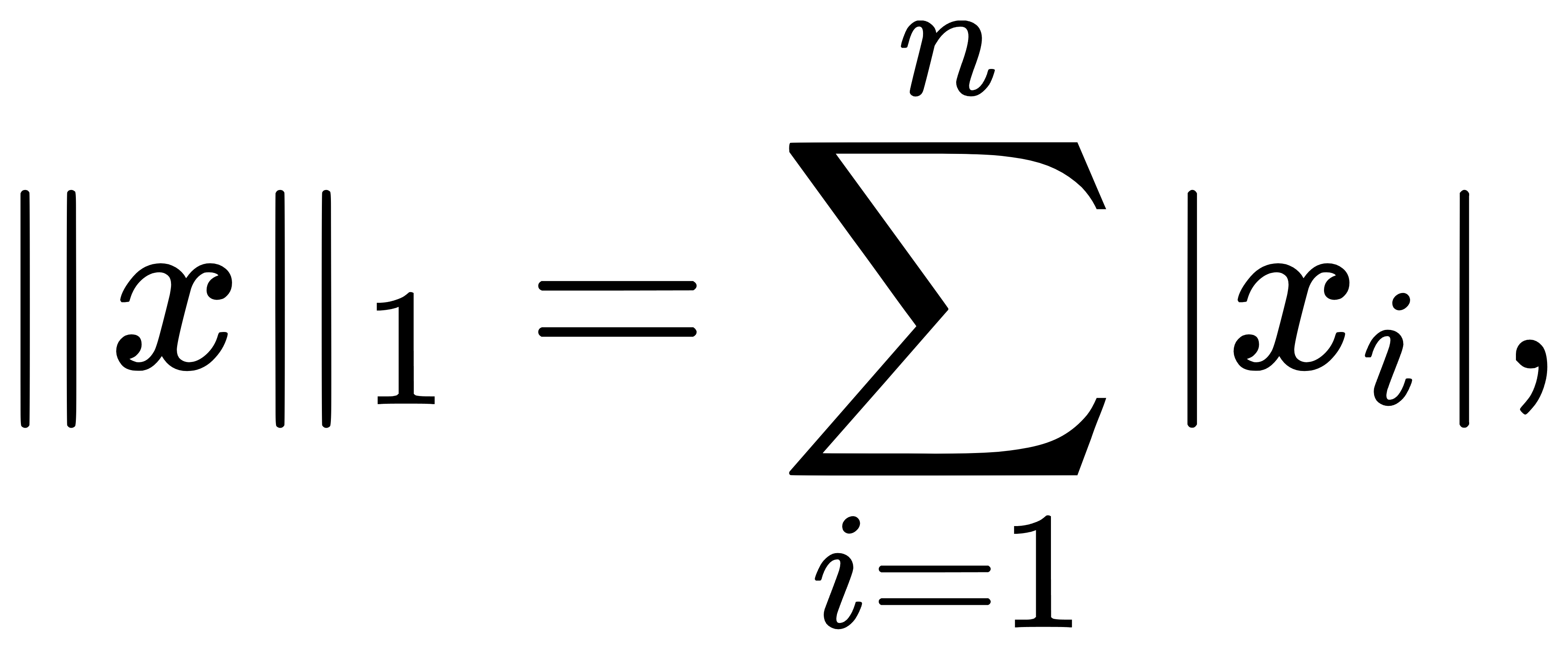
后者为欧几里得意义下的向量长度,亦即
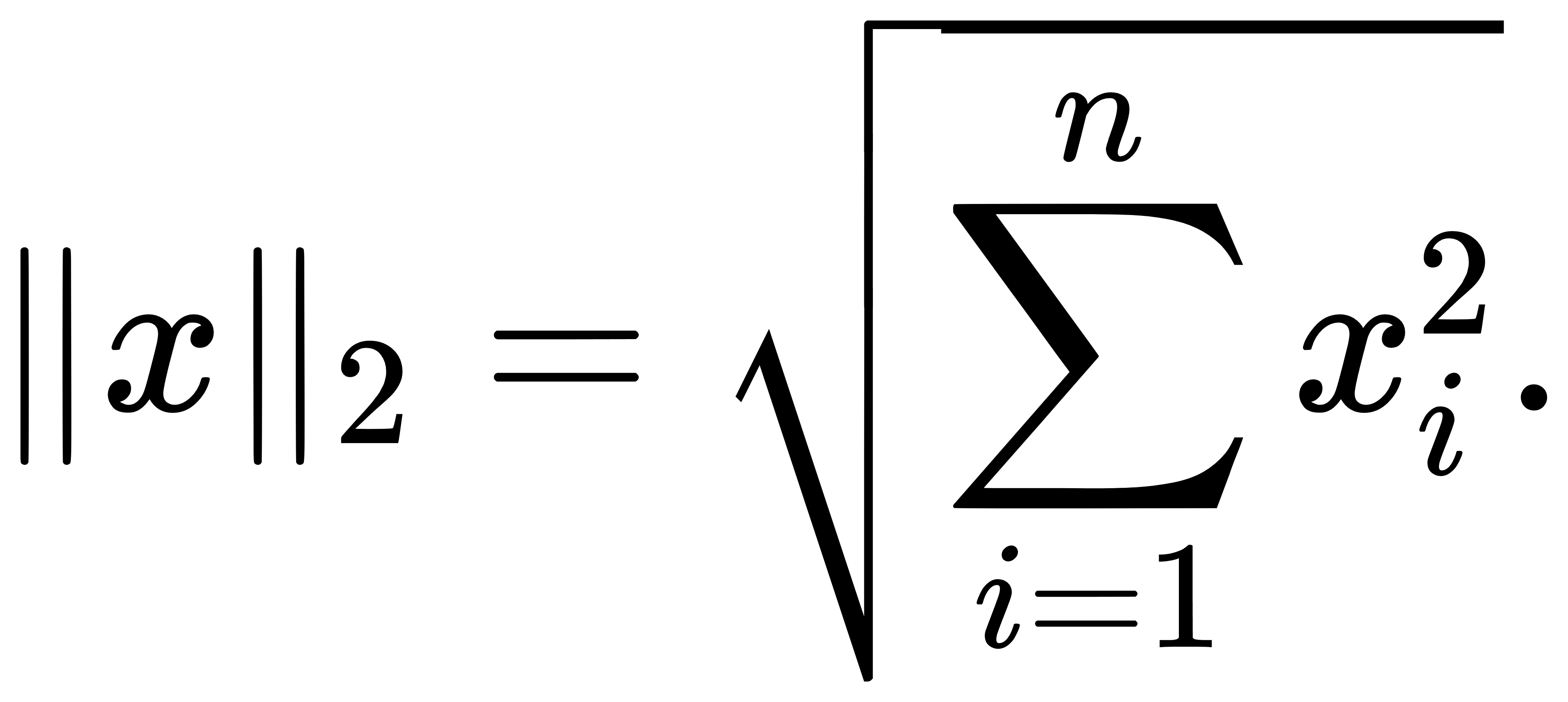
这两个范数虽然在表达形式上非常相近,但其在优化行为、解的稀疏性、几何结构以及机器学习中的效应却存在本质区别。
要理解为何机器学习模型普遍引入范数相关项作为“正则化项”,我们必须从泛化误差控制的角度出发。机器学习的核心目标并非只是在训练集上拟合数据,而是追求在未知样本上的良好预测性能。然而,模型的表示能力越强,拟合训练集的能力越强,其在未见数据上的行为反而可能越不稳定,即发生“过拟合”。正则化正是缓解这一问题的系统机制——通过限制参数空间、抑制极端权重,从而控制模型复杂度、提升泛化能力。范数正则项的基本形式如下:给定一个损失函数(如最小二乘、交叉熵),我们通常会最小化
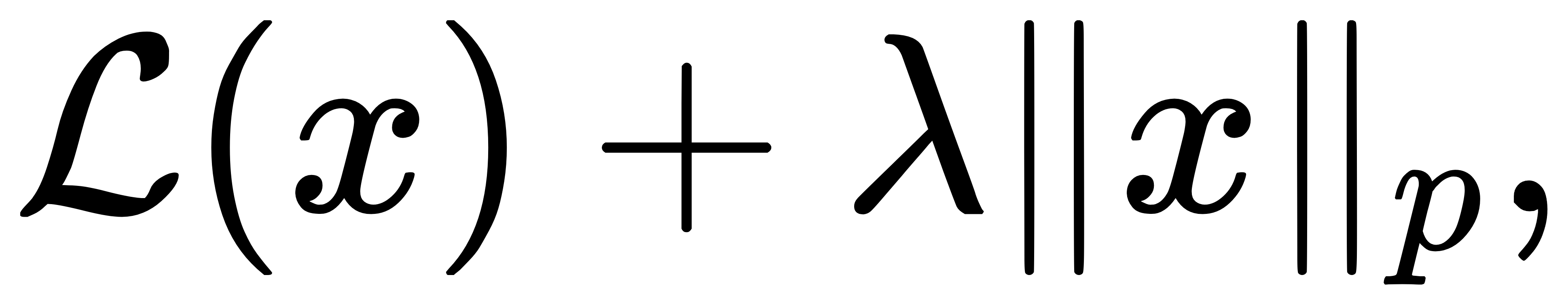
其中λ是调节拟合与正则之间权衡的超参数。L2范数在这一背景下意味着“整体缩小权重”,鼓励参数向零收缩但不直接归零;而L1范数则在优化中更偏向于产生稀疏解,直接使得某些维度上的参数变为零。这种稀疏性恰可用于自动特征选择,在高维数据场景中尤为重要。
更进一步,从贝叶斯视角出发,L2范数对应于在参数上施加零均值的高斯先验,而L1范数则对应于拉普拉斯先验,因此它们在模型不确定性、归纳偏好与先验控制方面也表现出不同的统计含义。
本文接下来的部分将围绕L1与L2范数的几何结构与优化行为展开讨论,特别是它们如何通过单位球约束影响最优解的形状与方向。
2. 几何结构与约束形状:范数如何决定最优解的方向性
在正则化优化问题中,范数项不仅是惩罚参数规模的一种方式,更直接决定了解的几何结构。在具有约束条件的优化问题中,例如

其中 t>0为某个固定半径,∥x∥p即作为正则项对应的范数约束,决定了解空间的形状。此时,最优解往往发生在损失函数等高线与约束边界相切的地方,因此约束集的几何结构对解的方向、稀疏性甚至唯一性产生直接影响。
首先观察L2范数,即欧几里得范数所诱导的约束集合∥x∥2≤t。在二维空间中,这一集合正是以原点为中心、半径为 tt 的圆盘,其边界 ∥x∥2=t 是平滑且严格凸的。若损失函数为二次型(如最小二乘),其等高线同样为椭圆形,两者的相切点几乎总出现在边界的内点,且不会落在坐标轴上,因此所得最优解通常非零。这正是L2正则化鼓励所有参数“平均缩小”而非“部分归零”的几何原因。
与L2相比,L1范数诱导的约束集合 ∥x∥1≤t在二维空间中是一个菱形,其边界由多条直线段拼接而成,构成尖点结构。这种非光滑性意味着损失函数等高线更容易与约束集合在“坐标轴交点”处相切,从而使最优解具有某些坐标分量恰为零。L1正则化天然地倾向于稀疏解,其几何根源就在于约束边界上的尖点对切线方向的吸引,而在更高维度下,这种现象愈发显著:L1单位球在 Rn中具有2n个尖点。

从拉格朗日乘子法的角度,也可以重新解释上述现象。令目标函数为
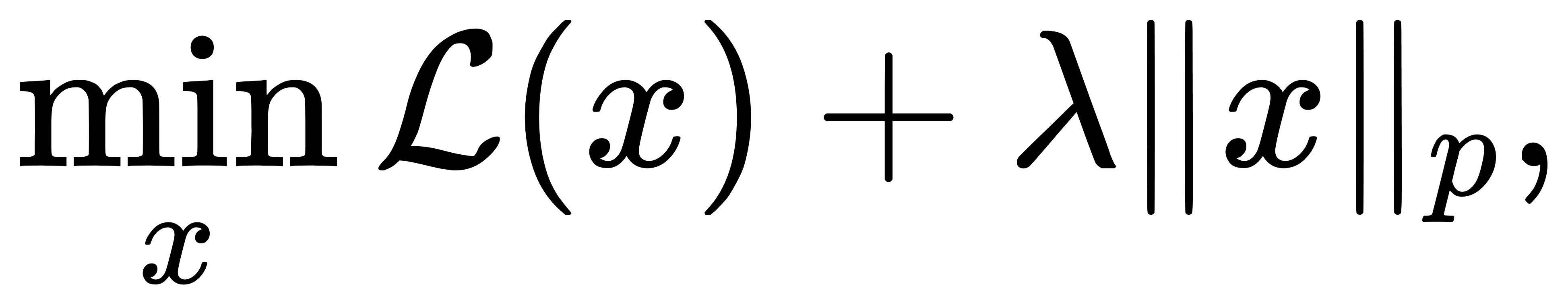
则其最优解满足
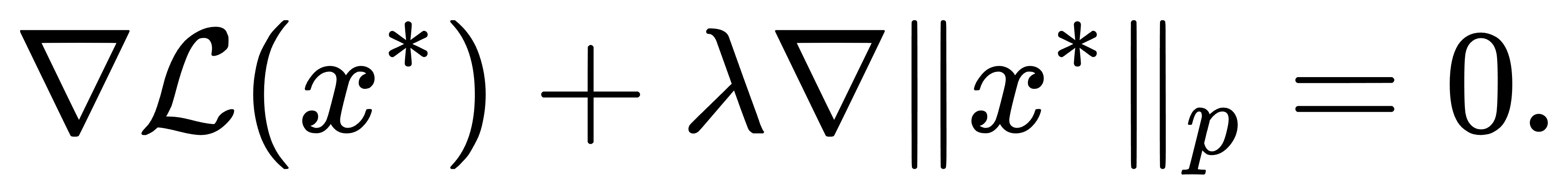
对于p=2,由于 ∇∥x∥2=x /∥x∥2几乎处处可导,梯度方向连续平滑,因此解不易落到轴上。而当p=1时,∇∥x∥1处不存在,需采用次梯度(subgradient)进行分析,解的结构就容易卡在不光滑点上,即形成稀疏项。
就比如,二维线性回归模型中,最小化残差平方和 ∥Ax−b∥22并分别加入∥x∥1与∥x∥2的正则项。通过绘制等高线与单位球,可以清晰看到Lasso(L1正则)给出的解往往落在坐标轴上,而岭回归(L2正则)则呈现均匀缩小的特征。
理解了这些约束集合所决定的“最优解形状”,我们便能从几何直觉过渡到优化行为的剖析,L1与L2正则对求解路径、变量进入模型的动态影响,这是下一章的重点。
3. L1与L2范数在优化中的行为与梯度结构差异
理解L1与L2正则项在最优化问题中的作用,不仅需要掌握其几何意义,更要看清它们在梯度空间中的具体表现。机器学习中的许多模型本质上都可以归结为一个目标函数的最小化问题,而正则项正是以“软约束”的形式加入其中,引导优化算法搜索到更有意义、更稳定的解。
我们先从L2范数出发。在损失函数中加入L2正则项,即求解如下问题:
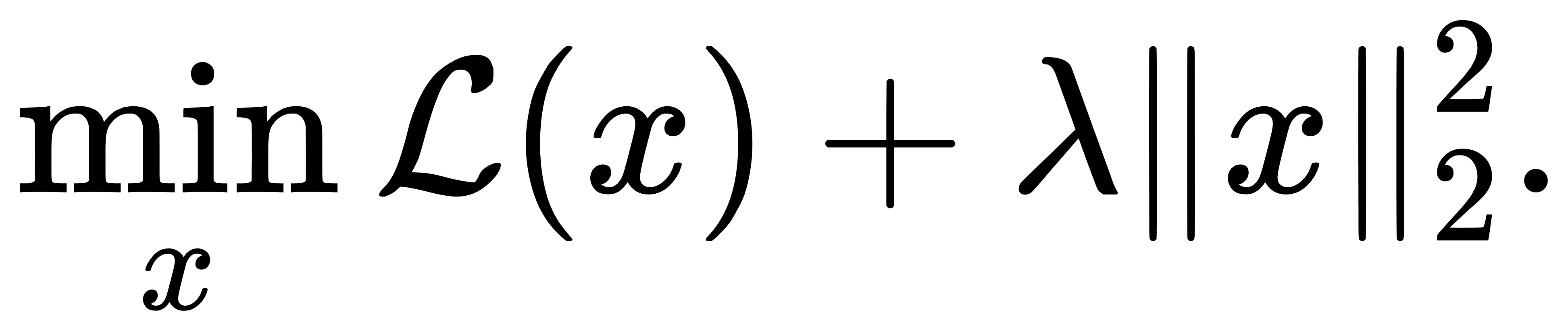
由于L2范数平方函数 ∥x∥22=∑xi2是处处可导的,其梯度表达非常简单,直接有

这意味着L2正则化在优化过程中,会持续产生一个线性拉回的力,把参数推向零点,但又不会让参数直接变为零。每个维度都会被同等对待,被等比例地压缩,使得整个解向量“收缩”而不是“筛选”。这也解释了为什么岭回归(L2正则)最终几乎不会得到稀疏解。
与此不同,L1正则项的梯度结构要复杂得多。考虑
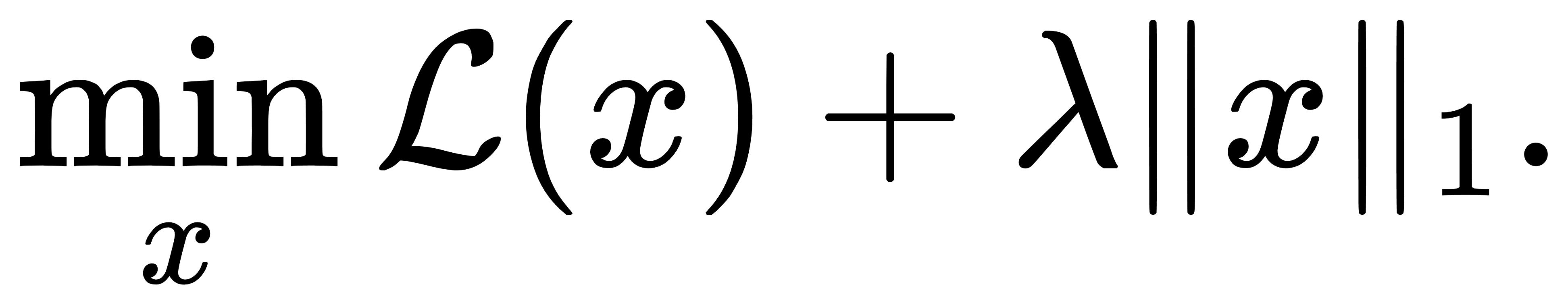
L1范数在 xi=0处不可导,梯度不存在,此时我们引入次梯度(subgradient)的概念。在 L1 正则中,每个分量的次梯度为:

因此,L1正则在零点附近的梯度不是一个确定的方向,而是一个区间。优化算法在这里会“卡住”一部分维度,促使它们停在零点。这种在非光滑点停住的机制,是L1正则能够实现特征选择、产生稀疏解的核心所在。而为了在实际中处理这种不可导的问题,人们通常采用坐标下降法或近似方法进行优化。其中最著名的是软阈值操作(soft-thresholding),即在每次参数更新时,先按照无正则项的方向更新,然后施加一个“向零拉回”的阈值操作,其形式为:
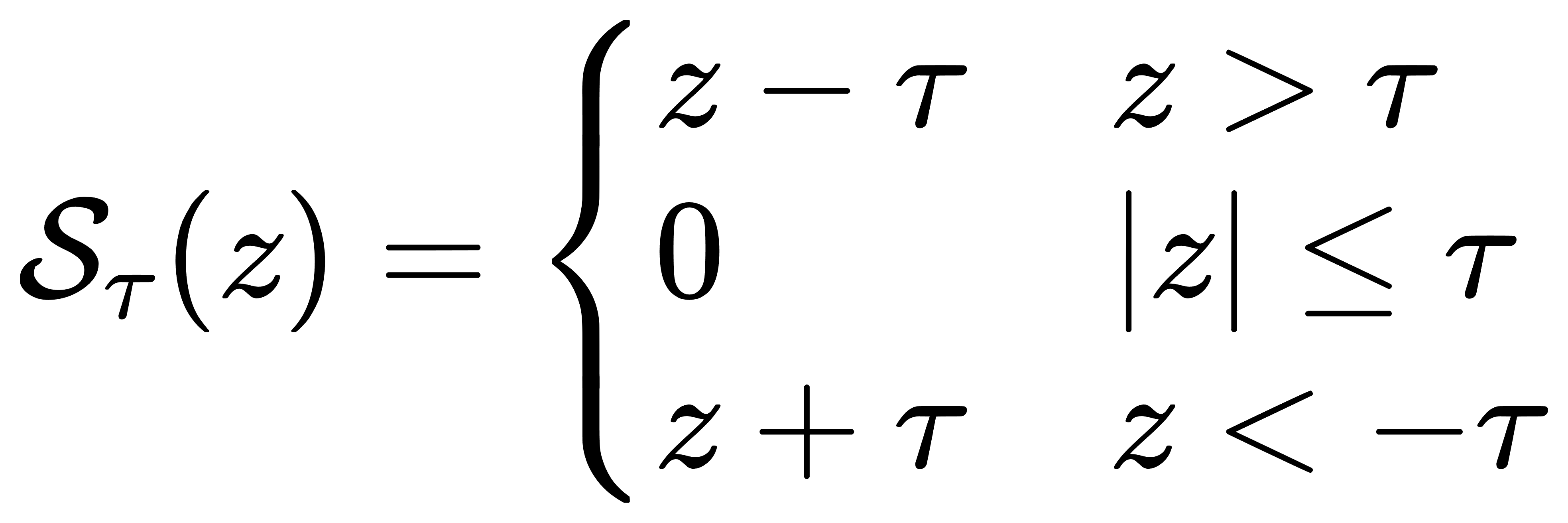
这一步骤在Lasso等算法中广泛使用,它等价于在保持解接近原有梯度方向的同时,自动将较小的维度“推成”零值。
而从优化路径的角度来看,L1和L2正则也呈现出截然不同的轨迹。以最小二乘回归为例,使用L2正则时,随着正则系数λ的逐步增大,所有变量的系数会逐步缓慢缩小,呈现出连续、平滑的衰减路径。而在L1正则中,不同变量的系数会分批次地“突然进入模型”,变量之间的稀疏性分界清晰,表现为路径中的“折线”形状。这种路径结构使得Lasso具备一种“变量筛选器”的功能,可以在模型学习过程中自动判断哪些变量有意义、哪些可以忽略。
从另一个角度看,L1与L2的差异也体现在梯度范数上。L2正则给出的梯度在整个空间中都是连续的,不会出现突变,因此适用于牛顿法、共轭梯度法等依赖二阶信息的优化算法。而L1的非光滑性使得传统优化方法难以直接应用,需要依赖次梯度下降、迭代阈值收缩(ISTA)或其加速版本FISTA等方法来处理。因此L2正则更适用于参数稠密、稳定性要求高的模型;L1正则则更偏向于特征冗余多、解释性要求强的建模情境。
4. L1与L2范数在现代机器学习中的应用与扩展
在现代机器学习系统中,L1与L2范数的使用早已超越了传统回归模型的范畴,它们作为正则化策略深入嵌入到深度学习、稀疏建模、特征选择、网络压缩、图模型等多个领域。尽管本质上只是控制参数规模的数学结构,但范数的选取方式却在很大程度上决定了模型的稀疏性、鲁棒性和解释能力。尤其是在高维、复杂模型结构中,如何在泛化能力与表达能力之间找到平衡,L1与L2的选择成为建模策略中的关键一环。
L2范数,作为一种“均匀收缩”的机制,仍是神经网络中最常见的正则化方式。在深度网络的训练中,它通常以权重衰减(weight decay)的形式实现,即在每次梯度更新时附加一项与当前权重成正比的惩罚项,使参数整体偏向更小的幅度。这种方式不仅能避免权重值无限放大造成的不稳定问题,也在一定程度上缓解了过拟合现象。需要特别指出的是,尽管在形式上 weight decay 与 L2 正则类似,但在实际实现中(如 Adam 等自适应优化器下)二者的作用机制略有差异,前者影响动量的累积行为,后者则是从目标函数角度直接施加约束。因此,在不同优化器下,其正则效果和动态表现也可能存在偏差。
相比之下,L1范数因其稀疏性诱导能力,在模型压缩与可解释建模中显示出独特优势。在深度神经网络中,通过对卷积核权重、注意力权重或通道激活值引入 L1 正则,可以实现结构性的神经网络剪枝(pruning),在不显著降低模型性能的前提下,压缩参数量,提升计算效率。这一做法在边缘计算、移动设备部署等资源受限场景中尤为重要。
L1范数也在特征选择任务中广泛使用。尤其是在预训练语言模型、图神经网络、以及基于多模态融合的任务中,模型往往面临大量冗余输入维度。通过在输入投影层或中间表示层引入 L1 正则,可以促使模型自动丢弃无效输入通道,从而提升泛化能力并降低解释复杂度。在图结构数据建模中,L1范数也常用于邻接矩阵稀疏化,或构造稀疏传播结构,以增强图模型的表达局部性。
实际任务中很多模型并不满足纯L1或L2的使用前提。随着ML技术的不断更迭,为了实现强稀疏与高稳定性的共同目标,Elastic Net被广泛采用,其实也就是同时引入L1和L2正则项。其目标函数为
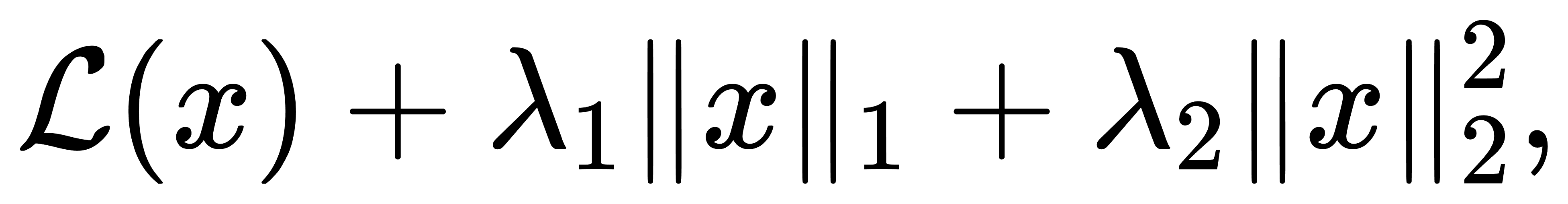
这种范数组合的结构,使得模型能在变量选择的同时保持鲁棒性,避免Lasso中变量相关性高时不稳定的解路径问题。而对于更复杂的模型结构,还出现了Group Lasso、Sparse Group Lasso等变种,分别针对结构化变量组和局部块的稀疏性进行建模。这类结构范数尤其适用于Transformer中多头注意力、ResNet中的通道裁剪、甚至是元学习框架中的元参数选择。再进一步的话,则可引入非凸稀疏范数(如 ℓ0近似、SCAD、MCP 等)理论上能带来更精确的稀疏控制。
在贝叶斯视角下,L2正则对应于对参数施加零均值的高斯先验,L1则对应于拉普拉斯先验。也正因为此,L1与L2正则常常被用作“频率学派”机器学习对“贝叶斯建模”的一种显式近似。更广泛的变种如 horseshoe prior、spike-and-slab 分布等也开始在深度网络中进行实现,用于将稀疏控制从优化框架转向生成建模框架,从而提升不确定性表达能力。
可以看到,范数正则项虽结构简单,却在各种建模细节中扮演着结构约束、稀疏诱导、压缩调控、泛化控制等多重角色。在理解其几何结构与优化行为的基础上,合理地选择或构造范数,往往是高质量模型设计的关键一步。 | 























