本帖最后由 离子 于 2025-7-11 13:21 编辑
本文介绍了能量基Transformer(EBTs),一种新型的人工智能模型,旨在通过无监督学习实现类人“系统 2”思维。现有的AI模型在处理简单任务时表现优异,但在需要深度推理的任务中仍存在不足。EBTs通过将能量基模型(EBM)与Transformer架构相结合,模拟人类的推理过程,即通过能量最小化优化预测,并动态分配计算资源,量化不确定性,以及自主验证预测的正确性。实验表明,EBTs在文本、视频和图像任务中均表现出色,学习效率和推理性能超过传统Transformer模型。EBTs不仅打破了现有AI在模态和任务上的局限,还为通用推理提供了新的路径。未来,EBTs有望在多模态场景中发挥更大作用,推动人工智能向更高层次发展。
人类的思维分为两种模式:快速直觉的 “系统 1” 和缓慢深思的 “系统 2”。系统 1 依赖直觉和经验,迅速解决熟悉的问题,而系统 2 则通过逻辑推理应对更复杂的挑战。当前的 AI 模型在 “系统 1” 任务(如图像识别、文本生成)中表现卓越,但在需要复杂推理的 “系统 2” 任务(如数学证明、决策推理)中依然存在不足。
近期,Alexi Gladstone 团队在 arXiv 上发布的论文《Energy-Based Transformers are Scalable Learners and Thinkers》提出了能量基 Transformer(EBTs),该模型突破了当前 AI 在推理任务中的局限,首次通过无监督学习让 AI 自主发展出类似人类“系统 2”思维能力,从而为通用人工智能的发展铺平了道路。

1 现有 AI 的 “思维瓶颈”
现有主流 AI 模型在推理能力上存在明显局限:
模态局限:如语言模型仅能处理文本,扩散模型专注于图像生成,难以跨领域通用;
任务局限:如基于强化学习的推理模型(如 O1、R1)仅在数学、编程等可验证领域有效,在写作、创意设计等领域表现下滑;
监督依赖:需要额外的人工标注或奖励信号来训练推理能力,无法通过无监督学习自主 “学会思考”。
例如,传统 Transformer 模型在生成文本时,每个 token 的计算量固定,即使遇到复杂推理也无法 “多花时间”;扩散模型虽能通过多步去噪提升图像质量,但无法自主判断 “何时停止优化”,必须依赖预设的去噪步骤。
2 EBTs:让 AI 像人类一样“深思熟虑”
2.1 能量基模型:AI 的“验证器”
EBTs的核心创新之一是采用了能量基模型(EBM)。传统的生成模型直接输出结果,而能量基模型不直接生成结果,而是为每个“输入 - 预测”对分配一个“能量值”,这个值可以看作是该预测与输入的匹配度。能量越低,表示预测越接近正确答案;能量越高,表示预测不合适。
能量基模型的“能量最小化”过程模拟了人类在推理时的思维方式:先提出假设,再通过验证和修改不断优化。
(1)能量函数: 对于一个输入 x 和一个预测结果 ŷ ,模型会计算一个能量值 E(x, ŷ),表示预测的合理性:
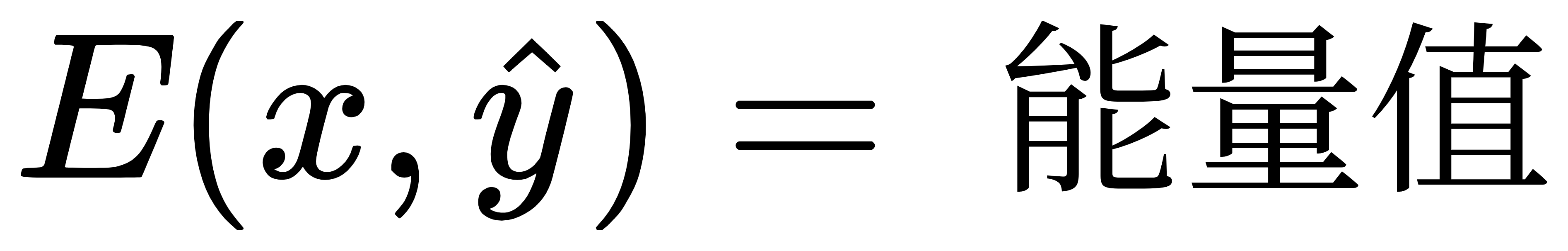
其中,能量值越低表示预测与输入匹配度越高。
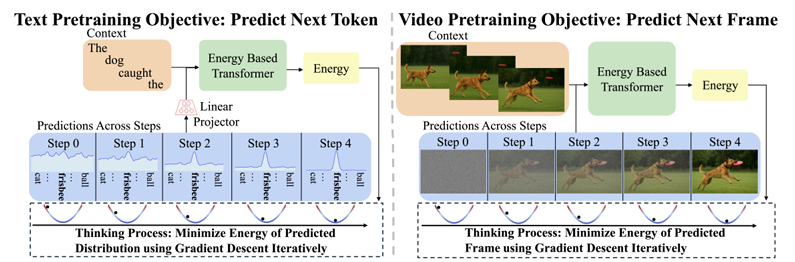
图1 EBT的自回归建模
(2)梯度下降优化过程: EBT通过梯度下降法优化预测结果,直到找到最优解,即能量值最小。具体地,模型会从一个初始的随机预测 ŷ0 开始,通过优化过程不断调整预测,直到能量收敛:
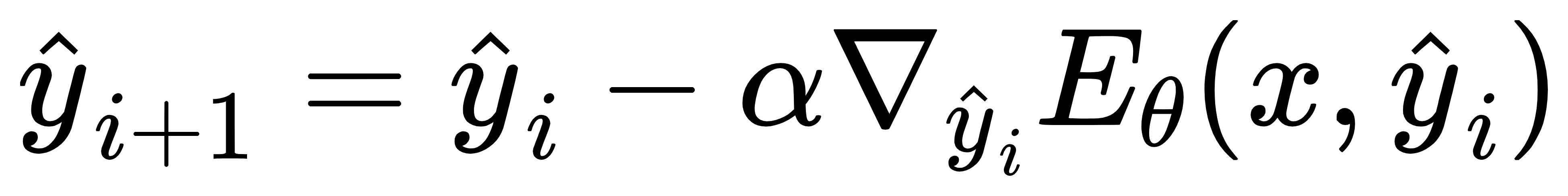
其中,α 是学习率,表示每步优化的幅度; ∇ŷi E(x, ŷi) 是能量对预测的梯度。
2.2 Transformer 架构:高效的“思考工具”
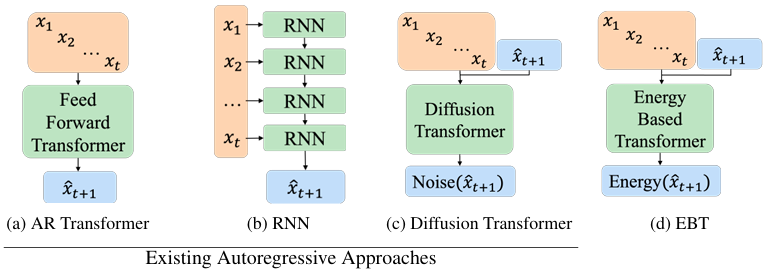
图2 自回归 Transformer 与其他架构的对比
Transformer的并行计算能力和注意力机制使其成为高效处理序列任务的理想架构。EBTs引入Transformer架构,通过并行计算和注意力机制解决了传统能量基模型的规模化问题。
EBTs包括两种变体:
自回归 EBT(类似 GPT):主要用于文本生成等序列任务,模型逐步生成一个序列。
双向 EBT(类似 BERT):支持图像去噪、填充式生成等任务,模型能够同时处理序列中的前后信息。
2.3 系统 2 思维:动态分配计算、量化不确定性、自主验证预测
相比现有模型,EBTs展示了人类“系统 2”思维的核心特征,通过以下三大优势在推理时表现出色:
(1)动态分配计算资源
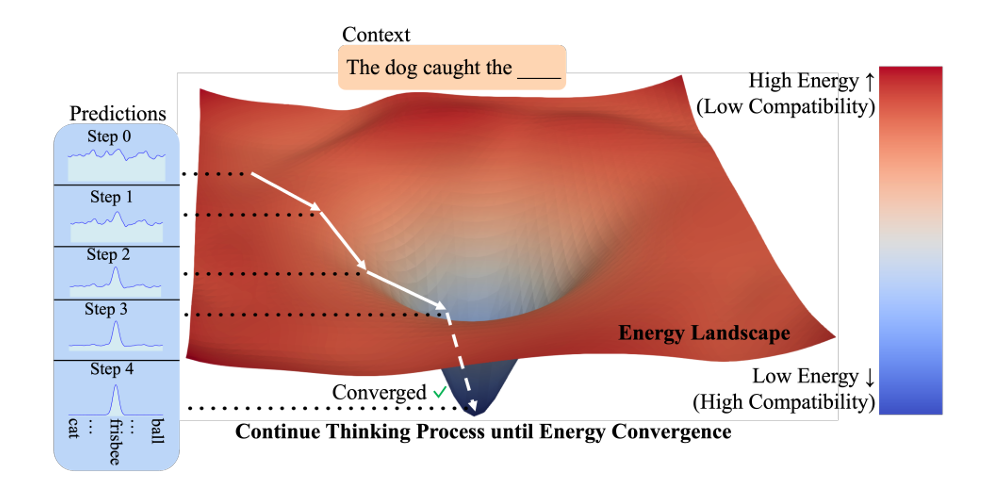
图3 EBT思考过程的可视化
人类在面对不同问题时会根据问题的难度分配不同的思考时间。EBTs通过能量最小化的迭代次数动态调整计算量:对于简单问题,模型能够快速收敛,而对于复杂问题,模型则会进行更多的迭代。
例如,在文本生成中,当生成常见词汇(如“的”、“是”)时,EBTs能量会迅速下降,预测迅速收敛;而在生成复杂的术语(如“能量基模型”)时,模型需要更多的迭代步骤。
(2)量化不确定性
在推理过程中,人类会对自己决策的把握程度进行评估。EBTs通过能量值的变化体现这种不确定性:能量快速下降且稳定,表示预测可靠;能量波动且难以收敛,则表示预测存在较大不确定性。
例如,简单的数学问题(如 2 + 2 = 4)会迅速得到稳定的能量值,而复杂的哲学问题(如“量子力学的本质是什么”)则会导致能量波动较大。
(3)自主验证预测
与生成答案相比,验证答案通常更为容易。EBTs将验证过程嵌入模型核心,通过能量值评估当前预测的可靠性,从而决定是否继续思考或输出最终答案。
决策公式:
当能量值足够低时,模型判断预测是正确的,停止优化。
当能量值较高时,模型继续迭代,直到找到最优解。
3 实验:EBTs的“超能力”

图4 EBTs在推理时的性能提升
EBTs在文本、视频和图像三大模态中均表现出显著优势。以下是实验结果的简要总结:
3.1 文本推理:学习更快,思考更深
学习效率:EBTs在RedPajamaV2语料库上进行预训练时,其学习速度比传统Transformer快35%,并且在数据量、参数量、计算量等方面具有更高的“缩放率”。
推理提升:EBTs在GSM8K数学题、SQuAD问答等任务上,通过增加推理步骤(即“多思考”),其性能比传统Transformer提高了29%。尤其在面对陌生题型时,EBTs展示了更强的推理能力。
3.2 视频预测:捕捉动态更精准
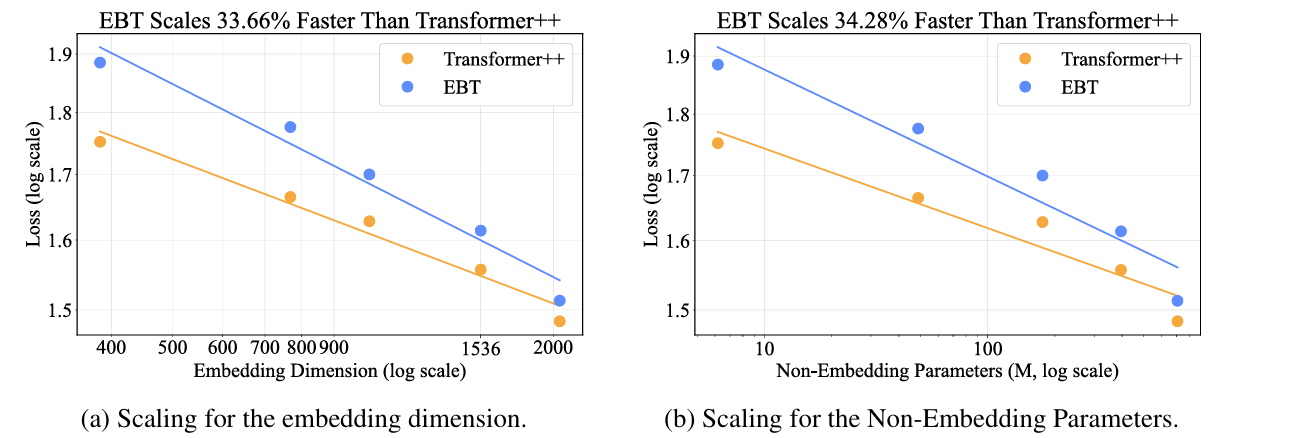
图5 视频学习中的EBT与传统模型的对比
在Something Something V2视频数据集上,EBTs通过增加模型规模,能够比传统Transformer更快地提高预测精度,表现出了在视频帧间动态关联捕捉上的优势。
3.3 图像去噪:少步骤,高质量
表1 图像去噪任务中的EBT与DiT对比

与扩散Transformer(DiT)相比,EBTs在图像去噪任务中仅使用1%的计算步骤,就能获得更高的峰值信噪比(PSNR),并且能够更好地适应“分布外噪声”。
4 创新价值与未来方向
4.1 创新价值
EBTs通过无监督学习实现了跨模态、通用的“系统 2”思维,打破了现有模型的模态局限、任务局限和监督依赖,展示了其在多个领域的潜力。
通用推理:EBTs不仅能在文本、图像、视频等多个领域中表现出色,还能在推理过程中动态分配计算资源,实现更高效的学习和推理。
效率跃升:EBTs的学习阶段和推理阶段都表现出了超越传统模型的效率,特别是在跨模态推理中,EBTs展示了更好的可扩展性。
可解释性:通过能量值,EBTs为AI决策提供了可追溯的“思考轨迹”,增强了推理过程的透明度。
4.2 未来方向
多模态场景:将EBTs应用于更复杂的多模态场景,实现跨文本、图像、语音的统一推理。
高效推理:结合循环神经网络(如Mamba)提升计算效率,探索基于蒙特卡洛树搜索的复杂推理能力。
5 结语
EBTs 的出现标志着 AI 从 “被动执行任务” 向 “主动思考决策” 迈进了关键一步。它不仅在学习效率和推理能力上超越了现有模型,更重要的是证明了:无监督学习足以让 AI 发展出类人思维的核心特征。或许在不久的将来,EBTs 能像人类一样,在解数学题时反复演算,在创作诗歌时字斟句酌,真正成为兼具 “直觉” 与 “深思” 的智能体。
论文链接:https://arxiv.org/abs/2507.02092v1
github:https://github.com/alexiglad/ebt | 





















