本帖最后由 Akkio 于 2025-7-23 00:38 编辑
本文是 Yann LeCun 关于 “能量模型” 的访谈内容。他认为能量模型属自监督学习,借统计物理学概念,通过能量高低衡量变量相容性,可避开概率模型标准化难题,为 AI 实现抽象预测和统一世界模型奠基。其更倾向非对比训练法,开发的联合嵌入模型让预测在抽象空间进行,VICREG 和 Barlow Twins 等方法助力系统分层规划,还涉及能量模型与其他领域关联及意识相关猜想等。
在人工智能领域不断探索前沿的进程中,元宇宙首席科学家、图灵奖得主扬・勒丘恩(Yann LeCun)的研究始终备受关注。继卷积神经网络为深度学习奠定重要基础后,他将目光投向了 “能量模型” 这一概念,认为其有望成为推动人工智能向自主智能迈进的关键。
Yann LeCun 在接受 ZDNet 的访谈中着重探讨了他在几年前曾大篇幅推崇的概念:「能量模型」(energy-based models)。Yann LeCun 认为,「能量模型」开辟了通往「抽象预测」的道路,为能够进行规划的人工智能提供了「统一世界模型」。

什么是能量模型?
Yoshua Bengio、Ian Goodfellow 和 Aaron Courville 等人在 2019 年出版的《深度学习》(又称「花书」)一书中将「概率函数」定义为「描述了一个或一组随机变量呈现其每种可能状态的可能性大小」,而能量模型则与之不同,它着重简化两个变量之间的一致性关系。能量模型巧妙地借用了统计物理学中的概念,其核心思想是:当两个变量不相容时,它们之间的能量会上升;而当两个变量具有一致性时,能量则会下降1。这种特性使得能量模型能够绕开概率分布中复杂的 “标准化” 过程,大大降低了计算的复杂性 —— 要知道,在概率模型里,为了确保所有可能状态的概率之和为 1,往往需要进行大量繁琐的计算,尤其是当变量维度较高时,这种计算难度更是呈指数级增长1。
这里的 “标准化” 是概率模型中一个棘手的问题:为了确保概率总和为 1,需要对所有可能的变量状态进行复杂计算,尤其是当变量维度很高时(比如一张 1024x1024 的图像有超过百万个像素变量),这种计算几乎不可能完成。而能量模型巧妙地避开了这一点 —— 它不直接计算概率,而是通过能量高低来判断变量间的兼容性,就像物理中 “同名电荷相斥(高能量)、异名电荷相吸(低能量)” 的直观关系,大大降低了计算复杂度。
简单来说,能量模型就像一个 “裁判”,通过衡量变量间的能量高低来判断它们是否匹配。比如在处理图像时,如果两张图片展示的是同一物体的不同角度,属于相容情况,能量就会较低;若一张是动物图片,另一张是植物图片,属于不相容情况,能量就会较高。这种方式无需像概率模型那样去精确计算每种状态的可能性,而是通过能量的相对高低来快速判断变量间的关系,为后续的处理节省了大量精力2。
在机器学习领域,能量模型是一个「老」概念,至少可以追溯到 20 世纪 80 年代。但近年来,越来越多成果使能量模型变得更可行。据 ZDNet 报道,近年来随着对能量模型的思考不断深入,LeCun 围绕该概念做了几次演讲,包括 2019 年在普林斯顿高等研究院的一次演讲。
最近,LeCun 在两篇论文中描述了能量模型的研究现状:一篇是 LeCun 与 Facebook AI 实验室 (FAIR) 的同事于去年夏天共同发表的 "Barlow Twins"; 另一篇则是他与 FAIR、Inria 合作发表于今年 1 月的 "VICReg"。
正如 LeCun 在采访中所说,他目前的研究与量子电动力学有一些有趣的相似之处,尽管这不是他的重点。他关注的重点是人工智能系统的预测可以进步到何种程度。
LeCun 自己开发了一种叫做 "联合嵌入模型 (joint embedding model)" 的现代能量模型,他相信这能为深度学习系统带来 "巨大的优势", 这个优势就是 "抽象表示空间中的预测"。
抽象表示空间是相对于原始数据空间而言的。比如,一张猫的图片在原始空间是数百万个像素点的组合,而在抽象表示空间中,可能被简化为 "猫的种类、姿态、背景环境" 等关键特征的集合。这种简化让模型不必关注无关细节 (比如猫身上某根毛发的位置), 从而更高效地进行预测。
LeCun 认为,这种模型为 "预测世界的抽象表征" 开辟了道路。抽象预测能力是深度学习系统广义上的发展前景,当系统处于推断模式时,这种抽象预测机器的 "堆栈" 可以分层生成规划场景。
这种模型可能是实现 LeCun 心目中的统一 "世界模型" 的重要工具,而这种统一的 "世界模型" 将推进实现他心目中的自主人工智能,自主人工智能能够通过对场景之间的相关性和图像、语音和其他形式输入数据的相关性建模来进行规划。
以下是 ZDNet 与 LeCun 通过 Zoom 的对话记录,内容有所编辑:
01
自监督学习 vs. 无监督学习
ZDNet: 首先,为了帮助我们学习,请谈谈您经常说的机器学习中的「自监督学习」和「无监督学习」。无监督学习和自监督学习的关系是什么?
Yann LeCun: 嗯,我认为自监督学习是一种特殊的无监督学习方式。无监督学习这个术语有点复杂,在机器学习的背景下不是很好定义。当提到无监督学习时,人们会想到聚类算法和 PCA (主成分分析), 以及各种可视化方法。
而自监督学习基本上是去尝试使用对于非监督学习来说相当于监督学习的方法:也就是使用了监督学习方法,但训练的神经网络没有人为提供的标签。比如说我们可以取一段视频,给机器看一段视频片段,然后让它预测接下来会发生什么。或者也可以给机器看两段视频,然后问它这个视频是另一个视频的后续吗?我们要做的不是让机器预测后续,而是让它告诉你这两个场景是否相容。或者向机器展示同一个物体的两个不同的视图,然后问它,这两个东西是同一个物体吗?在你给系统的所有数据基本上都是输入数据的情况下,自监督学习本质上没有真人的监督。
ZDNet: 近年来您做了几次演讲,包括 2019 年在新泽西州普林斯顿高等研究院 (IAS) 的演讲,以及最近 2 月份百度主办的关于深度学习基于能量的方法的演讲。这些基于能量的模型属于非监督学习的自监督部分吗?
YL: 是的。基于能量的模型中一切都能被假设。比如我给你 X 和 Y;X 是观察,模型应该捕获 Y 关于 X 的相关性。例如,X 是一个视频的片段,Y 是同一视频的另一个片段,向系统展示 X 和 Y, 系统就应该告诉我 Y 是不是 X 的后续。或者说给系统展示两张图片,系统就应该告诉我两张图是彼此相关还是两张完全不同的图片。能量衡量的是相容性或不相容性,对吧?如果 X 和 Y 是相容的,能量就是零,如果能量比较大,那 X 和 Y 就是不相容的。
我们有两种方法来训练基于能量的模型。第一种方式是向模型展示一对相容的 X 和 Y, 第二种是向模型展示一对不相容的 X 和 Y, 比如连不上的两个视频片段,两个根本不相同的物体的图片。对于这些不相容的 XY 对,我们需要设置高能量,而对于相容的 XY 对则降低能量值。
这是对比的方法。至少在某些情况下,我发明这种对比方法是为了一种叫做 "孪生网络 (siamese nets)" 的自监督学习方法。我以前很喜欢这种方法,但现在我改变主意了。我认为这种方法注定要失败。我不认为对比方法无用,但肯定是有不足之处的,因为这种方法不能很好地适应这些东西的维度。正如那句名言:幸福的家庭都是相似的;不幸的家庭各有各的不幸。
以图像识别为例,两张相同的猫的图片(相容对)可能只有 “拍摄角度、光线” 等少数差异;但不相容对的差异可以是 “物种、体型、颜色、背景” 等无数种。如果模型要通过对比方法学习区分,就需要见过所有可能的不相容组合 —— 这在高维图像空间中几乎不可能,因为组合数量会随维度呈指数增长,例如 1000 维空间中,可能的组合数是 2^1000,远超宇宙中原子的数量。
两个图像相同或相容的情况比较少,可是两幅图像却可以有很多不同的地方,而且空间是高维的。所以,基本上我们需要指数级量的对比能量样本来推动这些对比方法的工作。对比方法仍然很受欢迎,但在我看来这种方式的能力真的很有限。所以我更喜欢非对比法或者所谓的正则法。
而这些方法都是基于这样一种想法,即构造能量函数时,你赋予其低能量值的空间体积是有限的。这可以用损失函数或能量函数中的一个术语来解释,这个术语指的是最小化空间的体积,空间体积就可以某种方式使能量降低。我们有很多这样的例子,其中一个例子就是积分稀疏编解码,这个概念可以追溯到 20 世纪 90 年代。近来我真正感到有兴趣的是那些应用于自监督学习的非对比方法。
02
能量模型是未来的方向吗?
ZDNet: 你在演讲里讨论过 "正则化的基于潜变量能量的模型"(regularized latent variable energy-based model), 也就是 RLVEB。你认为 RLVEB 就是未来的发展方向吗?RLVEB 是否能引领 2020 年代或者 2030 年代的发展?
YL: 让我这么说吧:自从卷积网络之后,我对机器学习的东西就没那么感兴趣了。(笑) 我不确定 RLVEB 是不是新的卷积网络,但我对此真的很兴奋。当我在 IAS 演讲时,我满脑子都是 RLVEB。RLVEB 是生成模型,如果你想把它应用到视频预测之类的任务上,你给它一段视频,可以让它预测下一段视频。
在过去的几年里,我也改变了我的想法。现在,我最喜欢的模型不是从 X 预测 Y 的生成模型,而是我所谓的联合嵌入模型。我们取 X, 通过一个编码器运行它 (如果你想的话,也可以用一个神经网络来运行); 取 Y, 并通过另一个编码器运行它;然后预测就会发生在这个抽象的表示空间中。这就是一个巨大的优势。
为什么我改变了主意?我改变主意是因为我们之前不知道该怎么做。现在我们有一些方法可以派上用场。这些方法是在过去的两年中出现的。我正在推动的实际上有两个方法:一个叫 VICREG, 另一个叫 Barlow Twins。
VICREG(方差 - 不变性 - 协方差正则化)的核心是三个约束:1. 方差约束:确保每个特征维度都有足够的区分度(避免特征冗余);2. 不变性约束:让同一物体的不同变形(比如旋转、缩放后的图像)在嵌入空间中距离相近;3. 协方差约束:消除不同特征维度间的冗余关联(比如 “物体颜色” 和 “背景颜色” 应独立)。而 Barlow Twins 则通过最小化两个嵌入向量的交叉相关性,让模型学习更鲁棒的特征 —— 简单说,就是让模型 “关注本质差异,忽略无关干扰”。
ZDNet: 那么在接下来的 5 到 10 年里,你认为我们会在这方面看到什么进展呢?
YL: 我认为现在我们至少有了一种方法来让我们研究可以学习在抽象空间中进行预测的系统。在学习抽象预测的同时,系统也可以学习预测在抽象空间中随着时间或状态的变化会发生什么。对于一个自主的智能系统来说,这是非常重要的部分,例如,系统有某种世界模型,可以让你提前预测世界将会发生什么,也可以预测行为的后果。因此,给定对世界状态的估计以及你正在采取的行动,系统会给到你一个在你采取行动后世界状态的预测。
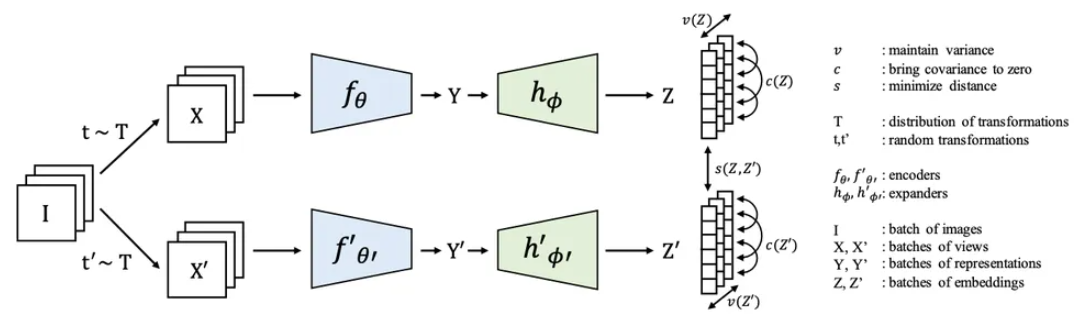
图注:基于能量的模型:"VICREG" 是 "自监督学习的方差 - 不变性 - 协方差重新正则化 (Variance-Invariance-Covariance Re-Gularization For Self- Supervised Learning)" 的缩写,是 LeCun 在基于能量的神经网络架构上的最新研究成果。一组图像在两个不同的管道中转换,每个扭曲后的图像会被发送到编码器,该编码器实质上是对图像进行压缩。然后,投影仪 (也被称为 "扩展器") 会将这些压缩的表示解压成最终的 "嵌入", 即 Z 维。正因为这两种嵌入之间的相似性不受其扭曲的影响,程序才能够找到合适的低能量级别去识别出某些东西。(图源:FAIR)
这个预测还取决于一些你无法观察到的潜变量。比如,当你开车的时候,你的前面有一辆车。这辆车可能刹车,可能加速,左转或右转。你不可能提前知道车辆的情况,这就是潜变量。所以整体架构是这样的,取最初的视频集 X 和未来的视频 Y, 将 X、Y 嵌入到某个神经网络中,从而得到 X 和 Y 的两个抽象表示。然后在这个空间里做一个关于某个潜变量的基于能量的预测模型。
重点是,这个模型在预测世界抽象表示的时候,是不能预测世界上所有的细节的,因为这个世界上的很多细节可能是不相关的。在路上驾车的时候,可能会在路边的一棵树上看到一片叶子上非常复杂的部分。模型是绝对不可能预测这个的,或者说你也不想投入任何精力或资源来预测这点。所以这个编码器本质上可以在被问到之前就消除这些信息。
ZDNet: 你认为在未来的 5 到 10 年会出现一些具体的里程碑吗?或者目标?
YL: 我预见到的是,我们可以使用「JEPA」(Joint Embedding Predictive Architecture) 架构来了解世界的预测模型,以一种自监督的方式学习感知表示而又不需要为特定的任务训练系统。因为系统学习了 X 和 Y 的抽象表示,我们可以把它们堆叠起来。所以,一旦我们学会了对周围世界的抽象表示,能够做出短期预测了,我们就可以叠加另一层,从而可以学习更抽象的表示并获得做出长期预测的能力。
JEPA 的分层规划可以用自动驾驶举例:最上层负责 “从家到机场” 的宏观规划(选择路线、避开拥堵);中间层将宏观目标分解为 “上高速、下匝道” 等中观任务;最下层则处理 “方向盘角度、油门力度” 等微观控制。每一层都基于上一层的抽象预测结果工作,且只关注与自身任务相关的特征 —— 比如上层不会关心 “车轮的具体转速”,下层也不必知道 “最终目的地是哪里”。
所以让系统通过观察和观看视频来了解世界是如何运作是很重要的。因为婴儿基本上是通过观察这个世界来学习的,学习直观的物理,学习我们所知道的关于这个世界的一切。动物也会这样做。我们想让我们的机器通过观察来学会了解世界是如何运作的。但是到目前为止,我们还没有做到这一点。因此在我看来,使用 JEPA 并以分层的方式检查它们,是实现系统观察学习的途径。
JEPA 能给予深度学习机器的另一个好处是推理能力。目前有一个争议:深度学习擅长的只有感知,因为输入和输出是明确的。但如果你想要一个系统具备推理能力与规划能力呢?世上存在具备一定的推理和规划能力的复杂模型,但这样的模型并不多。
那么,我们如何让机器去规划呢?如果我们有一个世界预测模型,如果我们有一个能让系统预测自己行为后果的模型,就可以让系统想象其行动路线并预测将会产生的结果。然后将这些信息提供给一些内部函数,这些函数会描述某个任务是否已完成。接着,通过优化,可能使用梯度下降法找出使目标最小化的一系列行动。我们现在不是在讨论学习;我们现在讨论的是推理与规划。事实上,我现在描述的是一种经典的计划和模型预测控制的最优控制方法。
最优控制的不同之处在于,我们用的是一个经过学习的世界模型,而不是一种固定的模型。我们的模型包含了所有可以处理这个世界的不确定性的变量,因此可以成为自主智能系统的基础,能够预测未来并计划一系列行动。
我想从这里飞到旧金山,那我就需要去机场,赶飞机等等。要去机场,我就需要离开我的大楼,沿着街道走一段,然后打一辆出租车。要离开我的大楼,我就需要离开我的椅子,走向门,打开门,走向电梯或楼梯。要做到走向电梯或者楼梯,我需要弄清楚如何把这些动作分解成一毫秒一毫秒的肌肉控制。这就叫做分层规划。我们希望系统能够做到这一点,但目前我们还不能真正做到如此。这些通用架构可以为我们提供这些东西。这是我的希望。
03
能量模型与其他方法之间的干丝万缕
ZDNet: 你描述能量模型的方式听起来有点像量子电动力学的内容,比如 Dirac-Feynman 路径积分或者波函数。这只是一种比喻,还是说也许这两者实际上是一致的?
YL: 这并不是比喻,而且两者其实是有些不同的,并非完全一致。比如你有一个潜变量,这个潜变量可以取很多不同的值,通常你要做的就是遍历这个潜变量所有可能的值。这可能有些不切实际。所以你可以从某个分布中对潜变量抽样,然后计算可能结果的集合。但是,实际上你最终要计算的是一个代价函数,这个代价函数给出了一个你对潜变量的可能值求平均的期望值。这看起来很像一个路径积分。路径积分实际上就是计算多条路径的能量之和,至少在传统意义上是如此。在量子方法中,你不是在把概率或分数相加,而是在把复数相加,而复数可以互相抵消。虽然我们一直在考虑这样的事情 (至少我一直在思考同样的东西), 但我们的研究中没有这样的内容。这个在上下文中没有用到,但是潜变量的边际化和路径 / 轨迹的总和是非常相似的。
ZDNet: 你曾做出两个相当惊人的断言。一是深度学习的概率方法已经过时。二是你说你正在讨论的基于能源的模型与 20 世纪 80 年代的方法有一些联系,例如 Hopfield 网络。请问能详细说明一下这两点吗?
YL: 我们需要放弃概率模型的原因是,我们可以对两个变量 X 和 Y 之间的相关性建模,但如果 Y 是高维的,如何表示 Y 上的分布呢?我们真的不知道该怎么做。我们只能写出一个非常简单的分布,一个高斯分布或者高斯分布的混合分布之类的。如果你想用复数概率去度量,我们不知道怎么做,或者说我们知道的唯一方法就是通过能量函数去度量。所以我们只能写一个能量函数,其中低能对应着高概率,高能对应着低概率,这就是物理学家理解能量的方式,对吧?问题是我们一直不太理解如何标准化。统计学、机器学习和计算物理学等领域里有很多论文都是有关如何解决这个棘手问题的。
我所倡导的是忘掉概率模型,只考虑能量函数本身。它甚至不需要使能量变成可以标准化的形式。最终的结果是,你应该有一种损失函数,当你训练你的数据模型,使得相容的能量函数低而不相容的能量函数高的时候,你就把损失函数最小化。就是这么简单。
ZDNet: 和 Hopfield 网络之间的关系呢?
YL: Hopfield 网络和 Boltzmann 机器当然与此相关。Hopfield 网络是以一种非对比的方式训练的能量模型,但效率很低,所以没什么人用 Hopfield 网络。
Boltzmann 机器基本上是 Hopfield 网络的一个对比版本,你得到数据样本并降低其能量,你生成其他样本并提高其能量。这种方法在某种程度上更令人满意,但也不是很有效,因为这种对比的方法不能很好地扩展。因为这个原因,这个方法也没有被使用。
ZDNet: 那么,正则化的、基于潜变量能量的模型 (RLVEB) 真的可以被认为是 Hopfield 网络的 2.0 版本吗?
YL: 我不那么认为。
04
"意识是人类大脑局限性的结果"
ZDNet: 你提出了另一个相当惊人的论断,即 "只有一个世界模型" 并认为意识是人类大脑中 "一个世界模型的刻意配置"。你说这可能是个疯狂的假设。这是你的猜想吗?这到底是一个疯狂的假设,还是有什么证据可以证明呢?在这个案例里有什么证据呢?
YL: 这是个猜想,一个疯狂的设想。任何关于意识的东西,在某种程度上都是猜想。因为我们一开始并不知道意识是什么。我认为意识是一种错觉。我想表达的是,意识被认为是人类和一些动物拥有的一种能力,我们认为意识体现了这些生物的智慧,这有点可笑。我认为意识是我们大脑局限性的结果,因为我们的大脑中有一个单一的、类似于世界模型的引擎,我们需要一些东西来控制这个引擎,这个东西就是意识。于是我们产生了人类有意识的错觉。如果我们的大脑变得无限大,不再有限制,我们就不需要意识了。
LeCun 的观点可以这样理解:人类大脑的算力有限,无法同时处理所有信息,因此需要 “意识” 来集中资源处理关键任务(比如开车时专注路况);而无意识则处理自动化任务(比如呼吸)。如果 AI 系统有无限算力,能同时模拟所有可能的未来场景,就不需要 “意识” 这种 “资源分配工具”—— 它可以直接计算出最优解。这也解释了为什么人类在熟练一项技能后(比如熟练驾驶),任务会从意识转向无意识:因为大脑将其交给了 “自动化模块”,节省资源给其他任务。
至少有一些证据表明我们脑中或多或少存在一个单一的模拟引擎。比如,我们基本上在同一时间只能尝试一项意识任务,我们专注于任务,我们会想象我们计划的行为的后果。你一次只能做一件事,或者你可以同时做多件事,但这些多个任务是我们训练自己不用思考就能完成的潜意识行为。比如我们可以一边开车一边和身边的人说话,只要我们练习开车的时间足够长,开车就已经成为一种下意识的行为。所以在刚开始学开车的几个小时里,我们做不到一边开车一边说话,我们必须集中精力才能完成驾驶,因为我们必须使用我们的世界模型预测引擎来找出所有可能发生的可怕情况。
ZDNet: 如果这只是一种猜想,那么它对你目前的工作并没有什么实际意义,不是吗?
YL: 不,有一定意义。我提出的这个自主人工智能模型有一个可配置的世界模型模拟引擎,其目的是规划和想象未来,填补你无法完全观察到的空白。可配置的单一模型会带来计算优势,可以让系统在任务之间共享知识,这些知识是你通过观察或基本逻辑之类的东西学到的。使用你配置的大模型要比使用一个完全独立的模型来处理不同的任务要有效得多,因为不同的任务可能需要单独训练。但是我们已经看到了,对吧?以前在 Facebook (当 Meta 名字还叫 Facebook) 的时候,我们用视觉来分析图像,做排序和过滤,基本上对于不同的任务,我们都有专门的神经网络和专门的卷积网络来解决。而现在我们有一个大的网络,什么任务都能处理。我们以前有好几个 ConvNets, 现在我们只有一个。
我们看到了这种简化。我们现在甚至有可以做所有事情的架构:同一个架构就可以处理视觉、文字、口语。这种架构必须分别接受三个任务的训练,而这个架构 data2vec, 是一种自监督的方法。
ZDNet: 真有意思!感谢你的分享。
05
总结
这篇访谈主要围绕 Yann LeCun 对 “能量模型” 的研究展开。LeCun 认为能量模型借鉴统计物理学概念,通过衡量变量间的相容性(能量低则相容,能量高则不相容),避开了概率模型中复杂的标准化过程,为人工智能实现 “抽象预测” 和 “统一世界模型” 奠定基础。
能量模型属于自监督学习范畴,其训练方法有对比法和非对比法(正则法),LeCun 更倾向于后者,因对比法在高维数据处理中扩展性差。他开发的 “联合嵌入模型” 让预测在抽象表示空间进行,还提到 VICREG 和 Barlow Twins 两种方法,认为这为系统学习抽象预测、实现分层规划提供可能。
此外,访谈还涉及自监督学习与无监督学习的关系、能量模型与量子电动力学及 Hopfield 网络的联系,以及 LeCun 关于意识是人类大脑局限性结果的猜想等内容,展现了能量模型在自主人工智能发展中的重要意义。
文章改编转载自微信公众号:AIoT产品
原文链接:https://mp.weixin.qq.com/s/p9N5It1F7oCpd97Yl3aa0Q
采访链接:https://www.zdnet.com/article/metas-ai-luminary-lecun-explores-deep-learnings-energy-frontier/ | 





















