本帖最后由 graphite 于 2025-7-23 22:04 编辑
本文梳理线性 Attention 的发展历程,指出其从模仿 Softmax Attention 起步,在 ChatGPT 推动的生成式模型需求下崛起。因解决 Softmax Attention 的二次复杂度瓶颈,线性 Attention 通过引入遗忘门、结合优化器构建 RNN 等创新形成特色,并出现反哺 Softmax Attention 的趋势,成为极具竞争力的序列建模方案。
在 2020 年作者写首篇相关文章线性Attention的探索:Attention必须有个Softmax吗?时,大家主要讨论的还是 BERT 相关的 Softmax Attention。
事后来看,在 BERT 时代考虑线性 Attention 并不是太明智,因为当时训练长度比较短,且模型主要还是 Encoder,用线性 Attention 来做基本没有优势。对此,作者也曾撰文线性Transformer应该不是你要等的那个模型表达这一观点。
直到 ChatGPT 的出世,倒逼大家都去做 Decoder-only 的生成式模型,这跟线性 Attention 的 RNN 形式高度契合。同时,追求更长的训练长度也使得 Softmax Attention 的二次复杂度瓶颈愈发明显。
在这样的新背景下,线性 Attention 越来越体现出竞争力,甚至出现了“反哺”Softmax Attention 的迹象。
一、平方复杂度
首先引入一些记号:
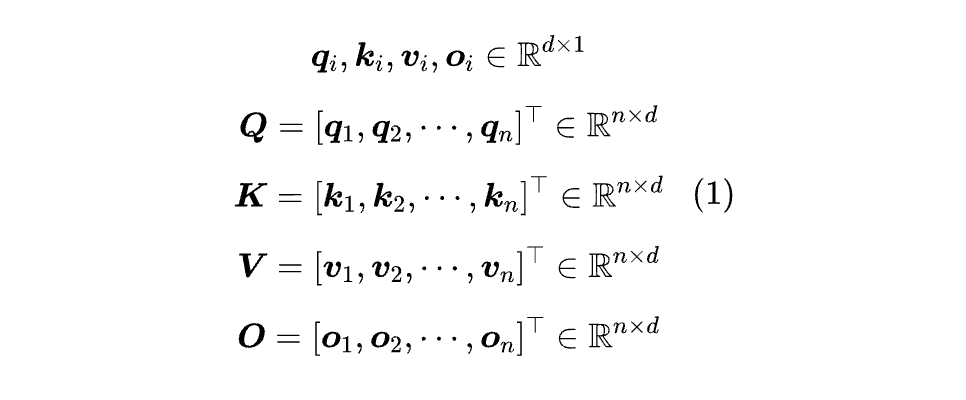
一个 Attention 模型,本质上是一个Q,K,V到O的映射。本文主要关心 Causal 场景,这意味着Ot至多跟Q[:t],K[:t],V[:t]相关。
原则上,Q,K 的 d 与 V,O 的 d 可以不一致,比如 GAU 和 MLA 便是如此,但将它们简化成同一个并不改变问题本质。
标准的 Softmax Attention,通常是指 Attention is All You Need 所提的 Attention 机制:
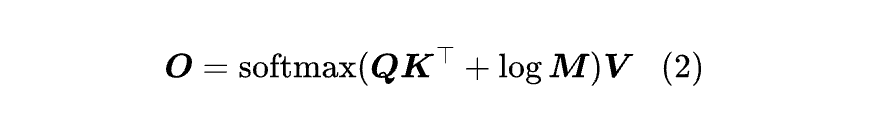
这里省略了缩放因子1/d1/2 ,softmax 因为它总可以吸收到Q,K里边, 是对第二个维度进行指数归一化,而M∈Rn*n是一个下三角阵,称为掩码矩阵,定义为:
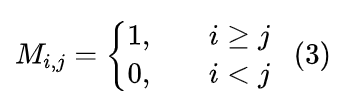
logM是指对M的分量逐一取log,其中log0=-∞。Softmax Attention 用分量形式写出来则是:
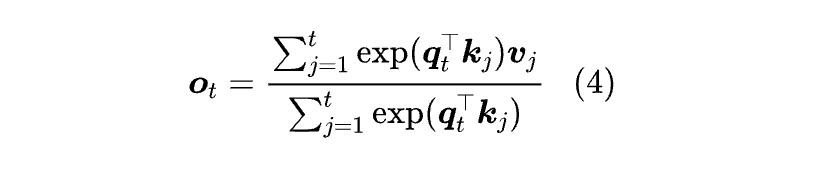
其中分母的作用主要是保持数值稳定性,另外就是如果我们给O加上 RMSNorm,那么分母也会自动消去,所以 Softmax Attention 的核心是分子部分,即:
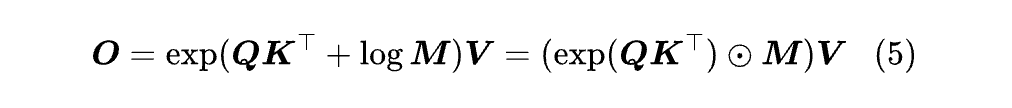
其中☉是Hadamard积,exp是逐分量取指数。不难看出,分母其实就是将V换成一个n*1的全1矩阵,如果有需要,我们再补上即可。
Softmax Attention 的标准实现需要把n*n的矩阵exp(QKT)算出来,所以空间和时间复杂度都正比于n2 。Flash Attention [1] 的出现降低了空间需求,但平方的时间复杂度依然无法避免。
二、最初的模样
线性 Attention 最早的思路主要是模仿和近似 Softmax Attention,其中最简单的方案是直接去掉exxp,得到:
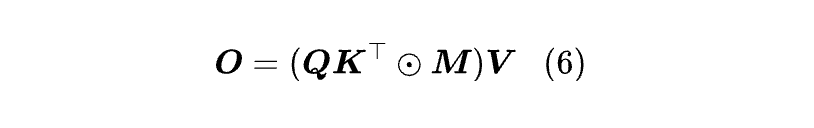
简单起见,我们约定矩阵乘法的优先级高于 Hadamard 积,这样可以省掉一组括号。为什么这个形式是“线性”Attention 的呢?
为了快速理解这一点,我们不妨先考虑去掉 ⊙M 的非 Causal 版,此时成立 O=(QKᵀ) V=Q (KᵀV),注意计算 KᵀV 的复杂度是 O (nd²),结果是 d×d 矩阵,然后跟 Q 相乘复杂度也是 O (nd²),所以它复杂度是线性依赖于 n。
至于 Causal 版 (6),我们可以从分量形式理解,写出:
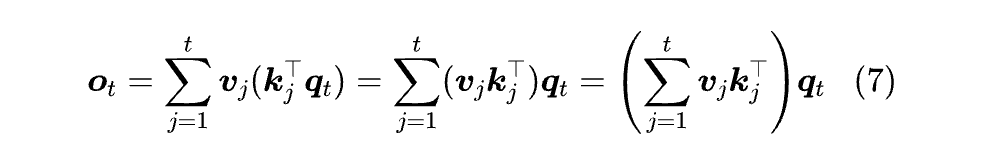
如果我们记括号部分为 Sₜ,那么有:
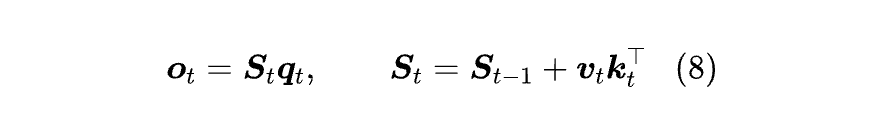
由此可见,Causal 形式的 Attention 可以写成一个以 Sₜ 为 State 的线性 RNN,因此每一步的复杂度是常数,总的复杂度正比于序列长度 n。
注意这里出现了 “线性 RNN”,它是更广义的概念,线性 Attention 属于线性 RNN 的一种,线性 RNN 也单独发展过一段时间,比如之前介绍过的 LRU、SSM 等,但最近比较有竞争力的线性架构都具有线性 Attention 的形式。
早年的线性 Attention 还有一些非常明显的模仿 Softmax Attention 的特点,比如会给式 (6) 加入分母来归一化,而为了归一化,那么 kⱼᵀqₜ 就必须非负,于是又给 Q,K 加上了非负的激活函数,以 Performer、RFA [2] 为代表的一系列工作,更是以近似 exp (QKᵀ) 为出发点来构建模型。
然而,后来的研究如《The Devil in Linear Transformer》[3] 发现,在序列长度维度归一化并不能完全避免数值不稳定性,倒不如直接事后归一化,如:
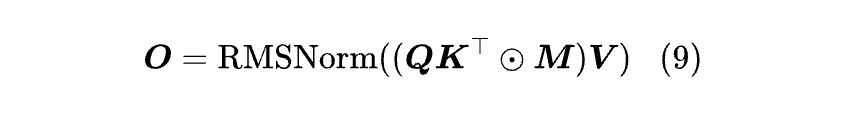
而既然不用归一化,那么给 Q,K 加非负的激活函数来保证 kⱼᵀqₜ 非负就非必须了。那给 Q,K 加 (不一定非负的) 激活函数还有意义吗?
笔者的观点是,加激活函数是大家的自由,不排除加某个激活函数能够调出更好的效果,但加激活函数并不改变线性 Attention 的形式,所以不影响我们的描述,另外就是现有的结果表明,其实不加已经足够好。
三、花式遗忘门
从式 (8) 我们可以看出,目前的线性 Attention 本质上就是个,即将所有历史信息都等权地叠加,不难想象当叠加的 token 足够多时,每个 token 的信息占比都会变得极小,于是单靠固定大小的矩阵甚至无法准确重建任意一个 token,直观类比就是每个 token 的记忆都变得模糊不清。
为了缓解这个问题,RetNet [4] 给线性 Attention 引入了遗忘效应:
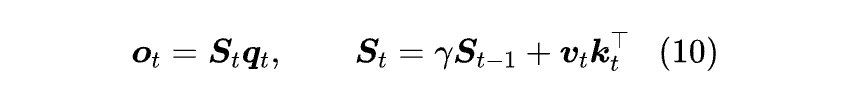
其中衰减因子 γ属于(0,1)区间,在 RetNet 中被设为常数,也有设为可训练参数的,以及将 γ 改为对角矩阵的,等等,MiniMax-01 [5] 所用的线性 Attention 也是这种。
注意,衰减因子在 RetNet 前也有,不过它们多以线性 RNN 的形式出现,如上一节提到的 LRU、SSM 等,RetNet 应该是首次将它跟线性 Attention 结合起来。
加入衰减因子后,模型会倾向于遗忘掉更为久远的历史信息,从而至少保证最近 token 的分辨率,说白了就是跟语言模型特性相符的 “就近原则 (Recency Bias)” 的体现,从而往往能工作得更好。
此外,一个值得关注的细节是 RetNet 还给 Q,K 加上了 RoPE,这相当于将衰减因子推广到复数域,从 LRU 的角度看则是考虑了复数的特征值。
尽管给 RNN 加位置编码的操作看上去似乎有点违和,但有些实验比如最近的 TransXSSM [6] 表明,给线性 Attention 加 RoPE 也有一定的正面作用。当然,这可能取决于具体的模型变体和实验设置。
式 (10) 的一个简单推广是将 γ 更换为位置 t 的函数 γₜ,这在 SSM 中已经有所体现。
后来,DFW [7]、Mamba [8]、Mamba2 [9] 等工作,将它推广成跟输入相关,形成了 “data-dependent decay” 相关的一系列工作,这跟以往 GRU、LSTM 等非线性 RNN 的 “遗忘门 (forget gate)” 其实已经非常相似了,只不过为了保持模型的线性性,去掉了遗忘门对 State (如 Sₜ₋₁) 的依赖。
为什么我们偏爱线性 RNN 呢?因为线性 RNN 基本都能找到某种方式来并行训练,这使得它相比 Softmax Attention 更具竞争力 —— 在训练效率和推理效率上都不逊色。
其中,并行化的 “通解” 是转化为 Prefix Sum [10] 问题然后 Associative Scan,大体思路我们在《Google 新作试图 “复活” RNN:RNN 能否再次辉煌?》的 “并行化” 一节也简单介绍过。
然而,“通解” 并不是 GPU 高效的,GPU 最高效的是矩阵乘法,所以找到大量使用矩阵乘法的并行算法是最理想的,甚至都不用并行,只要找到充分使用矩阵乘法的 Chunk by Chunk 递归格式,都能明显提高训练效率。
这反过来对模型提出了要求,如只有外积形式的遗忘门才能实现这个目的,典型反例就是 Mamba,它是非外积的遗忘门,无法充分发挥 GPU 的性能,所以才有了后续 Mamba2 和 GLA [11] 等变化。
四、测试时训练
至此,线性 Attention 从最初的简单模仿 Softmax Attention,到引入静态衰减因子乃至 “data-dependent decay”,已经形成了自身的特色并在不少任务上发挥价值。
然而,这些进展多数是靠人工凭经验设计出来的,我们不禁要问:有没有更上层的原则来指导线性 Attention 甚至是一般的序列模型 (Token-Mixer) 的设计?
对于这个问题,TTT (Test Time Training)[12] 给出了自己的答案,它将序列模型的构建视为一个 “在线学习 (Online Learning)” 问题,并提出用优化器来构建 (不一定是线性的) RNN 的做法。
具体来说,它将 K,V 视作语料对 (k₁,v₁),(k₂,v₂),…,(kₜ,vₜ),根据这些语料训练得到一个模型 v=f (Sₜ;k),最后输出 oₜ=f (Sₜ;qₜ),其中 Sₜ 是模型参数,至于模型结构很大程度上是任意的。
这跟 RNN 有什么关系呢?很简单,优化器如 SGD、Adam 等,它们本质上就是一个关于模型参数的 RNN!
其实这个观点并不新鲜,早在 2017 年 Meta Learning 盛行那会就已经有研究人员提出并利用了这点,只不过当时的想法是尝试用 RNN (LSTM) 去模拟一个更好的优化器,详情可以参考《Optimization as a Model for Few-Shot Learning》[13]。
正所谓 “风水轮流转”,时隔多年 TTT 反过来提出通过优化器来构建 RNN。它的流程是这样的:首先,当前模型参数为 Sₜ₋₁,优化器 (SGD) 接收到新数据 (kₜ,vₜ),根据该数据将模型参数更新为 Sₜ = Sₜ₋₁ - ηₜ∇Sℓ(Sₜ₋₁;kₜ,vₜ),最后返回 f (Sₜ;qₜ) 的预测结果 oₜ,依此类推。
所以,TTT 所实现的 RNN 可以统一地写成:
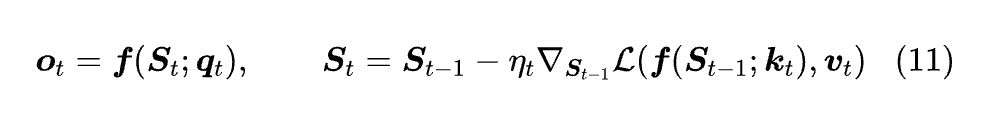
其中 ℓ(S;k,v) 是当前数据 (k,v) 在当前参数 S 下的损失函数,ηₜ 则是学习率参数,参考上一节的 “data-dependent decay”,它也可以做成 data-dependent 的。
这个形式可以覆盖非常多的 RNN 模型,比如式 (8) 和 (10) 都是它的一个特例:
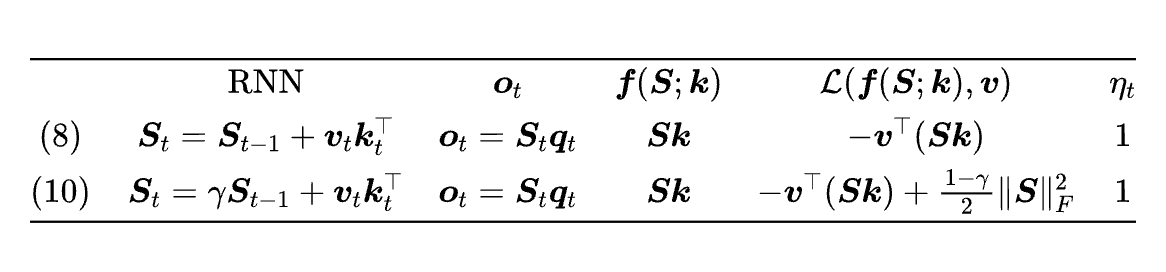
TTT 原文则致力于探索 mini-batch 下的非线性 RNN,后来的 Titans [14] 则给 TTT 的 SGD 加上了动量,再后面《Test-Time Training Done Right》[15] 则探索了 large-batch 的 TTT 用法,还探索了 “TTT + Muon” 的组合。
注意,TTT 只是利用优化器来构建 RNN,RNN 以外的参数如 Q,K,V 的可训练参数,还是将整个模型构建起来后用整体的优化器训练的。
一个更值得思考的问题是:为什么 TTT 可以成为构建 RNN 的 “指导原则” 呢?
RNN 的核心目标,是将历史数据有效地压缩到一个固定大小的 State 中,而模型参数正好是固定大小的,训练模型某种程度上就相当于把训练数据压缩到模型权重中,TTT 正是利用了它跟 RNN 目标的高度契合性。
说直白一点,如果将 RNN 视为一个压缩任务,TTT 将模型 f 视为 “解压器”,它的权重则是 “压缩包”,而压缩算法则是 SGD,压缩率则是损失函数。
这样一来,我们就不用花心思构建递归格式了,转而构建模型 f 和损失 ℓ,一个 RNN 强不强、靠不靠谱,我们也只需看对应的 f 和 ℓ 就可以心中有数。
除此之外,TTT 用 Online Learning 构建 RNN,意味着所得 RNN 必然非常契合 ICL (In Context Learning) 任务,这也是 TTT 作为 “指导原则” 的优势。
此前《Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers》[16] 甚至反过来,将 Softmax Attention 去掉 Softmax 成线性 Attention 来解释它的 ICL 能力,用现在的视角看它就是构造了对应的 TTT 出来。
五、除旧而迎新
例如,最早的线性 Attention 对应的损失函数是 -vᵀ(Sk),这一看就是个不大靠谱的目标,因为它是无下界的,这可能会导致 S 趋于无穷。
相比之下,RetNet 往损失函数加入了 L2 正则项,避免了这种风险,从优化角度看也缓解了过拟合的风险,从而得到一个更好的 RNN。
然而,用内积作为损失函数虽然简洁且有一定道理,但它不是直接鼓励 Sk = v,所以并非一个理想的回归损失。更好的目标函数应该是平方损失,即 1/2‖Sk - v‖²,将它代入到 TTT 的公式 (11) 得到:
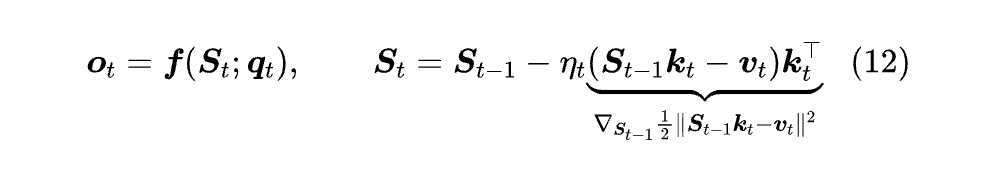
这便是 DeltaNet,这个名字出自《Parallelizing Linear Transformers with the Delta Rule over Sequence Length》[17],更早则是由《Linear Transformers Are Secretly Fast Weight Programmers》[18] 提出。
留意到 ηₜ(Sₜ₋₁kₜ - vₜ) kₜᵀ = (Sₜ₋₁(√ηₜkₜ) - (√ηₜvₜ))(√ηₜkₜ)ᵀ,这意味着 ηₜ 总可以吸收到 kₜ,vₜ 的定义中去,所以我们接下来的分析都只考虑 ηₜ=1 的情况:
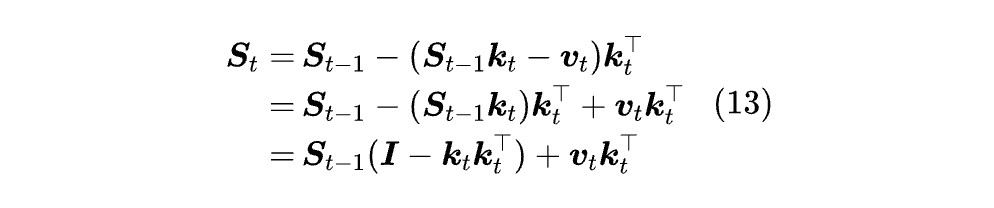
如果有需要,我们再把 kₜ,vₜ 换成 √ηₜkₜ,√ηₜvₜ,就可以将 ηₜ 恢复出来。对比线性 Attention 最早的形式 (8),DeltaNet 的区别是在加 vₜkₜᵀ 前多减了个 (Sₜ₋₁kₜ) kₜᵀ,其中 Sₜ₋₁kₜ 可以理解为新输入 kₜ 在旧模型 Sₜ₋₁ 下的预测结果。
直观来想,“先减后加” 就是先移除模型对 kₜ 的旧认知,然后根据 (kₜ,vₜ) 补充新认知,达到 “除旧迎新” 的效果。这个规则称为 “Delta Rule”[19],正是 DeltaNet 一词中 “Delta” 的来源。
Delta Rule 并不新鲜,它又称为 Least Mean Square [20]、Widrow-Hoff Algorithm 等,已经是上个世纪 60 年代的产物了。事实上,这个领域完全新的东西很少,很多改动都可以追溯到某个 “上古时期” 的工作,目前的努力主要集中在挖掘其中能 Scalable 的部分。
六、求逆与推广
前面我们说了,线性 RNN 最理想的 (即 GPU 高效的) 并行算法是充分使用矩阵乘法的形式。为了完成这一目标,我们先将 DeltaNet 写成:
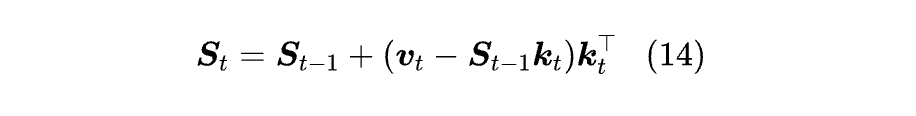
记 uₜ = vₜ - Sₜ₋₁kₜ,那么 Sₜ = Sₜ₋₁ + uₜkₜᵀ,也就是说它只是在最早的线性 Attention 基础上把 V 换成了 U = [u₁,u₂,…,uₙ]ᵀ,将它迭代 t-1 次,我们有:
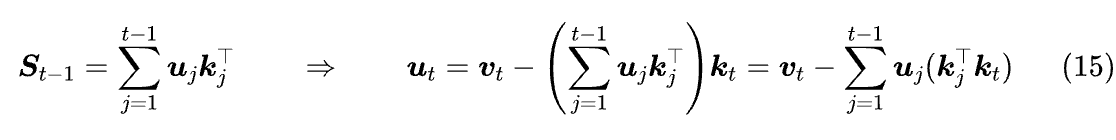
最后的等式写成矩阵形式是 U = V - (KKᵀ⊙M⁻) U,其中 M⁻=M-I,这是一个线性方程组,它的解可以直接表示为:
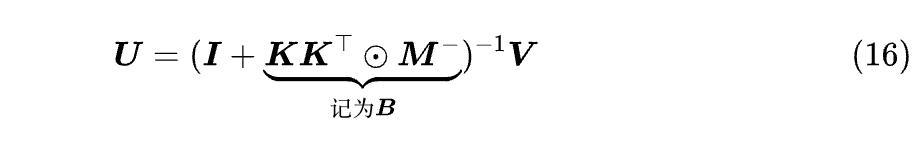
这里出现了 (I+B)⁻¹,一个 n×n 矩阵的逆,标准复杂度是 O (n³),比 Softmax Attention 还高!不过好在我们不需要显式的逆而是只要 U,这可以转化为解方程组 (I+B) U=V,复杂度降到 O (n²)。
进一步地,利用 I+B 是下三角阵以及 B 的低秩结构,可以将复杂度降到线性,写成分块矩阵乘法后就可以充分利用 GPU。这些细节只能请大家阅读原论文了,本文先把主要数学原理介绍清楚。
DeltaNet 之后,Gated DeltaNet (GDN)[21] 进一步地将遗忘门引入到 DeltaNet 之中,这倒是可以预料的变化。Gated DeltaNet 的原始引入方式是:
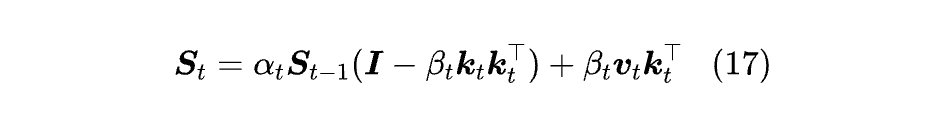
但个人认为,这个提法其实显式打破了 Delta Rule,更好的提法应该是像 Comba [22] 一样,只乘到第一个 Sₜ₋₁ 上:
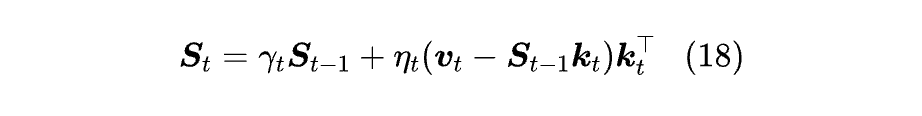
它相当于将损失函数取 1/2‖Sk - v‖² + (1-γ)/η‖S‖_F²。当然,从数学上来说,这两个提法都是等价的:
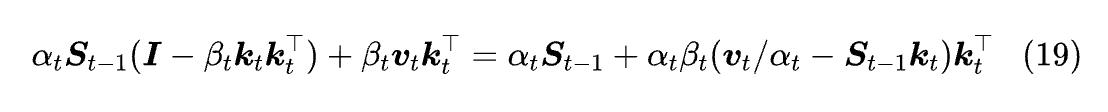
即 γₜ=αₜ,ηₜ=αₜβₜ 然后把 1/αₜ 吸收到 vₜ 就可以转化为后者了。所以说,这两个形式在数学上并没有区别,由于多数 αₜ 会接近于 1,所以能力上估计也没啥区别 (Comba 说 (18) 会好一点),只不过后者更直观地保留了 Delta Rule 的样子。
从理论上来说,Gated DeltaNet 也可以写成 DeltaNet 的形式,因为只需要定义 αₜ=∏ⱼ₌₁ᵗγⱼ,那么式 (17) 两边同时除以 αₜ,就得到:
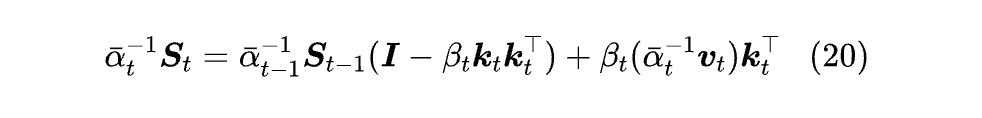
然后结合 oₜ = Sₜqₜ = (αₜ⁻¹Sₜ)(αₜqₜ),可以发现只需要分别将 αₜqₜ,αₜ⁻¹vₜ 设置为新的 qₜ,vₜ,那么就能简化成 DeltaNet 的形式。
不过,这个结果只有在某些情况下具有理论推导的价值 (比如推导下一节的 Attention 矩阵),因为实际计算中,不管怎么参数化,对于足够大的 t,αₜ 和 αₜ⁻¹ 之一必有溢出的风险。
DeltaNet 之后还有另一个推广 DeltaProduct [23],它是将 k,v 扩展若干倍后再做 DeltaNet 或者 Gated DeltaNet,试图增强模型的状态追踪能力。
不过,就笔者的审美而言,与其像 DeltaProduct 那样扩展常数倍,还不如像《时空之章:将 Attention 视为平方复杂度的 RNN》一样尝试平方复杂度的 RNN,看有没有机会超越 Softmax Attention。
七、反哺进行时
说到超越 Softmax Attention,开头提到,如今的线性 Attention 不仅能与 Softmax Attention 一较高低,甚至开始 “反哺” 它。这看似不可思议,但细思之下并不难理解。
某种意义上,这些年 Softmax Attention 一直在退步,从 MHA、GQA 到 MQA 都是为了压缩 KV Cache 而做减法。而线性 Attention 没有 KV Cache 问题,所以一直往更好的方向前进。
为了更好看出这一点,我们不妨将前面提到的 Attention 机制都以矩阵形式写出来:
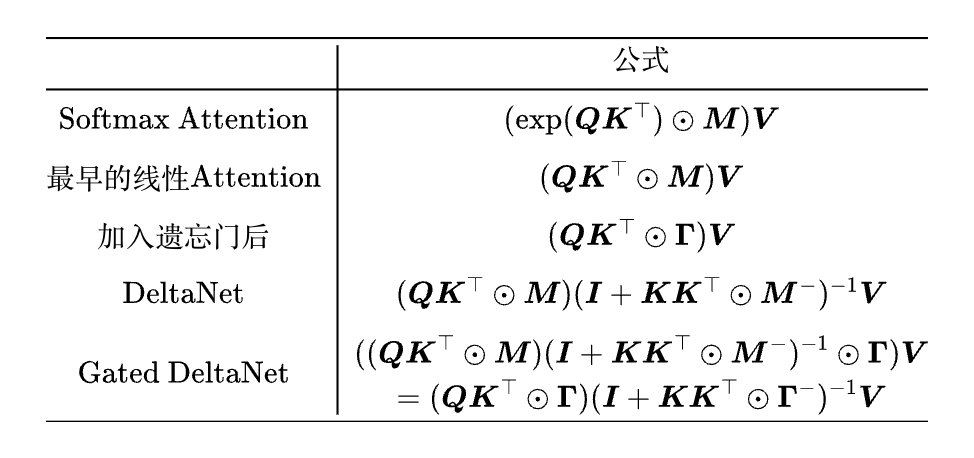
其中:
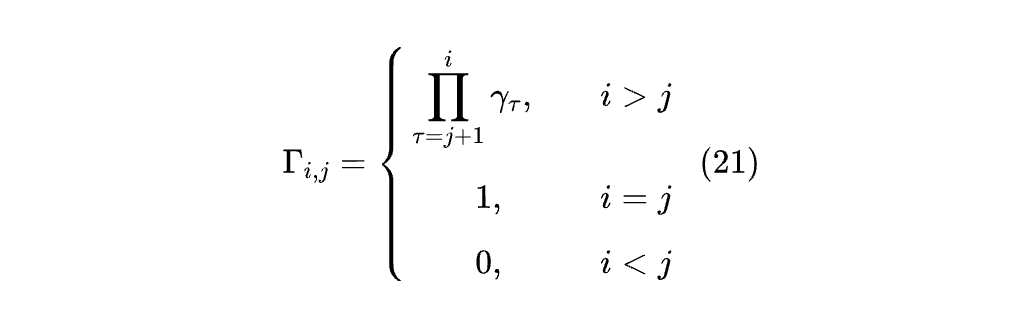
以及 Γ⁻=Γ-I。这样看来,Softmax Attention 的形式还仅停留在最早的线性 Attention 那会 (当然这也证明了它的强大)。那 “反哺” 怎么实现呢?
首先我们需要一种方法把 Softmax Attention 转化为线性 Attention,这个并不难,早在《Transformer 升级之路:作为无限维的线性 Attention》[24] 我们就总结了三种将 Softmax Attention 转化为无限维线性 Attention 的方案。
总之,就是存在一个映射 φ,将 Q,K 从 n×d 映射到 n×∞,满足 exp (QKᵀ)=φ(Q)φ(K)ᵀ,这称为 “核技巧”。
那接下来的事情就简单了,我们只需将上述表格中的线性 Attention 的 Q,K 换成 φ(Q),φ(K),最后再设法恢复并归一化,就得到新的 Softmax Attention 变体了。例如,代入到遗忘门的公式,我们有:
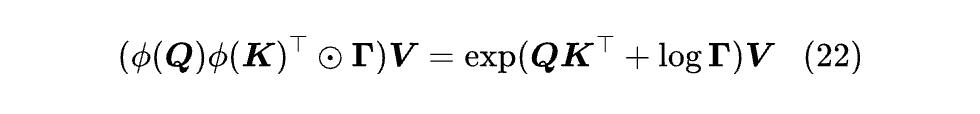
如果 γₜ 取常数,那么其实就是《Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation》[25] 所提的 ALIBI,而如果 γₜ 是依赖于输入的,那么就是《Forgetting Transformer: Softmax Attention with a Forget Gate》[26] 所提的 FoX。
一个更有意思的结果是《Understanding Transformer from the Perspective of Associative Memory》[27] 所提的 DeltaFormer,顾名思义它是 Softmax Attention 的 DeltaNet 版本。将 DeltaNet 的 Q,K 换成 φ(Q),φ(K),我们有:

如果要归一化,我们将换成即可。相比 Softmax Attention,DeltaFormer 将原本的 AV 改成了 A (I+B)⁻¹V,注意到:
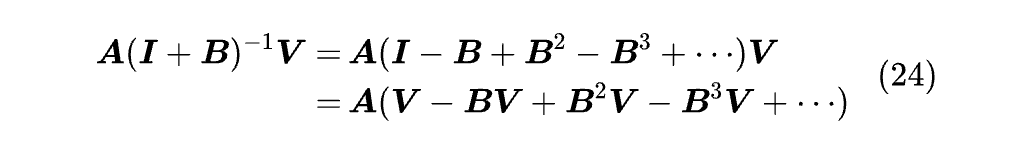
所以 DeltaFormer 相当于先用 K,K,V 算多次 Attention,将结果叠加起来后作为新的 V,再跟 Q,K 算一次 Attention,这个特性让它对 Multi-Hop 的任务有奇效 (比如 Code)。
此外,DeltaFormer 的这个特点还意味着它跟 MQA 特别搭配,因为 (I+B)⁻¹V 这部分只有 KV 参与,而对于 MQA 来说 K,V 只有 Single-Head,计算量相比 MHA 会明显降低。
不过,在笔者看来,这种固定系数的叠加可能是 “没有免费午餐”,比如笔者的实验结果显示,DeltaFormer 的语言模型损失并无太大变化,这意味着如果某些任务的损失明显降低,必然有另一些任务的损失上升了。
八、硬核编码术
还有一个值得关注的反哺工作是 PaTH Attention,出自《PaTH Attention: Position Encoding via Accumulating Householder Transformations》[28],它从位置编码的角度将 DeltaNet 反哺到 Softmax Attention。
我们在《Transformer 升级之路:旋转位置编码的完备性分析》指出,对于任何正交矩阵 Ω,Rₘ=Ωᵐ 都是广义的 RoPE。
除了旋转矩阵,还有哪些容易构建的正交矩阵呢?
PaTH 用的是 Householder 矩阵 [29]:设 w 是任意模长为 √2 的列向量,那么 I - wwᵀ 是一个正交矩阵,这我们在《从一个单位向量变换到另一个单位向量的正交矩阵》[30] 也推导过,几何意义是镜面反射。
容易看出,这跟 DeltaNet 中 Sₜ₋₁ 所乘的 I - kₜkₜᵀ 是一样的,所以 PaTH 干脆把这部分照搬过来,即放弃 Ωᵐ 这个形式,也放弃 ‖w‖=√2 的约束,直接用一系列 I - wwᵀ 连乘来表达位置信息:
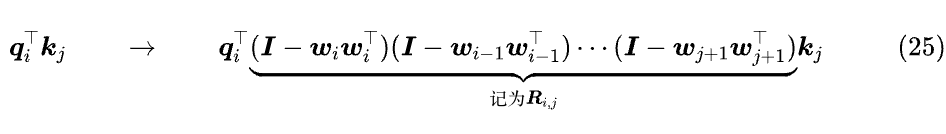
将 Rᵢⱼ 写成递归形式是 Rᵢⱼ=(I - wᵢwᵢᵀ) Rᵢ₋₁ⱼ,Rⱼⱼ=I。对比 DeltaNet 的式 (13),上式相当于 vₜ 恒等于零,但初值 S₀ 不再是零。使用 “求逆来相助” 一节同样的过程,我们可以得到:
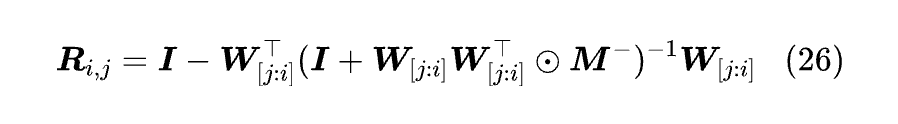
其中 W=[w₁,w₂,…,wₙ]ᵀ,切片按 Numpy 来理解,如 W₍[j:i]₎=[wⱼ₊₁,wⱼ₊₂,…,wᵢ]ᵀ,切片优先级高于转置。
注意求逆的是下三角阵,三角阵有一个重要特性,逆矩阵的对角线元素等于原矩阵对角线元素的倒数,如果是分块三角阵则对角块也满足这个特性,于是我们可以写出:
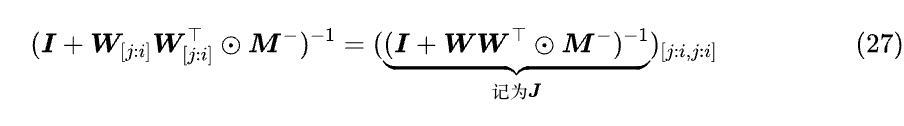
接下来的变换,写成分量形式可能好理解一些:
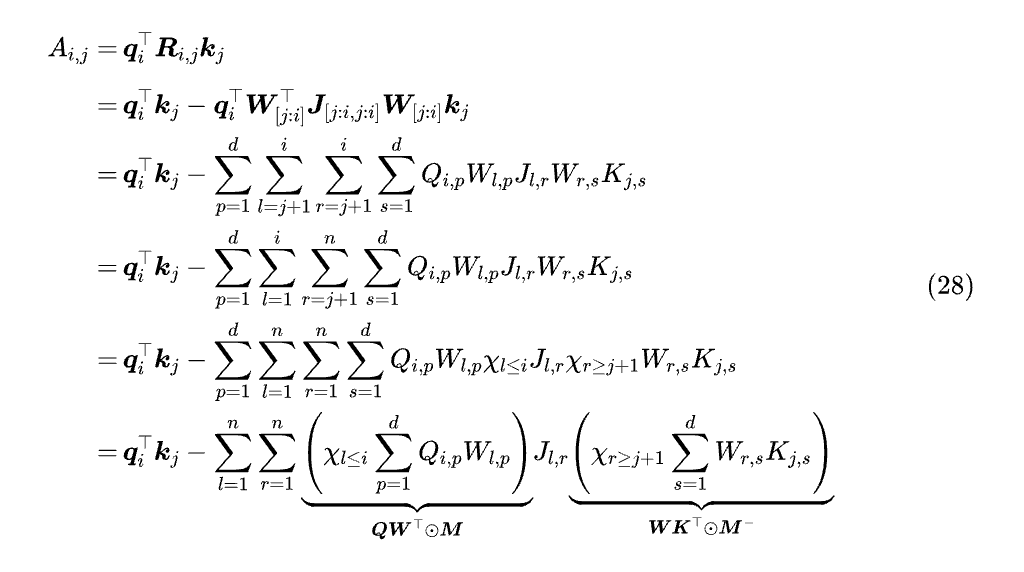
这里有几个关键点:比较巧妙的是第 4 个等号,它利用了 J 是下三角矩阵这一点,所以 l<r 时 Jₗᵣ 自动为零;第 5 个等号,χ 为示性函数,满足下标的条件时为 1,否则为 0。
第 6 个等号,当我们分别处理 p,s 两部分求和时,结果是 QWᵀ 和 WKᵀ,而乘 χₗ≤ᵢ 刚好表示保留 QWᵀ 的下三角部分 (连同对角线),而乘 χᵣ≥ⱼ₊₁ 则表示保留 WKᵀ 的下三角部分 (不包括对角线)。
至此,我们可以把整个 (Softmax 之前的) 注意力矩阵写出来:
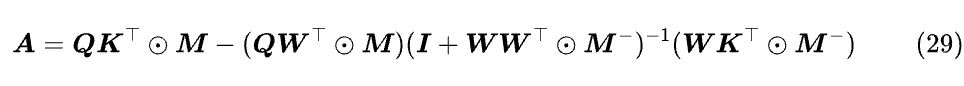
有没有被震惊到?这还没完。直接求逆复杂度是 O (n³),这肯定无法接受,还要想办法利用 WWᵀ 的低秩特点将复杂度降低到 O (n²),然后还要推反向传播,最后写成类似 Flash Attention 的高效实现,这些细节大家只能看原论文挖掘了,总之全程都非常硬核。
从位置编码的角度看,PaTH 是 CoPE (Contextual Position Encoding)[31] 的一种,它的位置并不是编号,而是根据上下文内容自动生成的位置信号。
类似地,FoX 也可以看成是 Contextual 版的 ALIBI。上下文相关的位置信息是当前线性 Attention 的主要特征,也可能是反哺 Softmax Attention 的主要方向。
九、化简乐无穷
我们不妨再深入点探讨一下 PaTH,这不仅有助于我们了解 PaTH,也能帮助我们更熟悉 DeltaNet,两者本身就是高度相关的。这一节我们从 PaTH 的两个特例入手,它可以帮助我们更好地理解 PaTH 与 DeltaNet 的关联。
第一个特例是 W=K,代入到 (29) 得到:
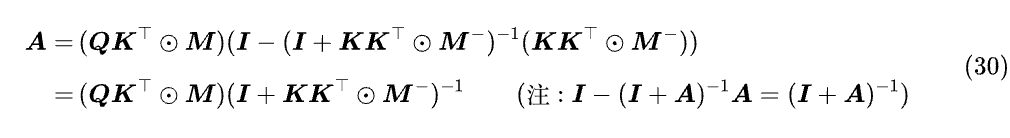
有没有觉得有点熟悉?这刚好就是 DeltaNet 的 Attention 矩阵!从这个特例看来,PaTH 和 DeltaFormer 的区别就在于,DeltaFormer 基于核技巧,给 DeltaNet 的 QKᵀ 和 KKᵀ 分别加上 exp,而 PaTH 直接给 DeltaNet 的 Attention 矩阵加上 exp。
第二个特例是重新引入 ‖w‖=√2 这个约束,此时 I - wwᵀ 是正交矩阵,我们引入:
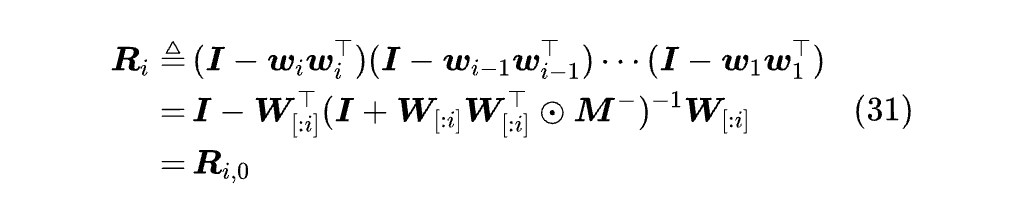
那么 Rᵢⱼ=RᵢRⱼᵀ。这个等式意味着我们可以像 RoPE 一样,用绝对位置的方式实现相对位置的 PaTH,即只需要给每个 qᵢᵀ,kⱼᵀ 都乘上 Rᵢ,然后套用 Softmax Attention 的实现就行。那么乘 Rᵢ 是什么运算呢?重复上一节的展开过程,我们有:
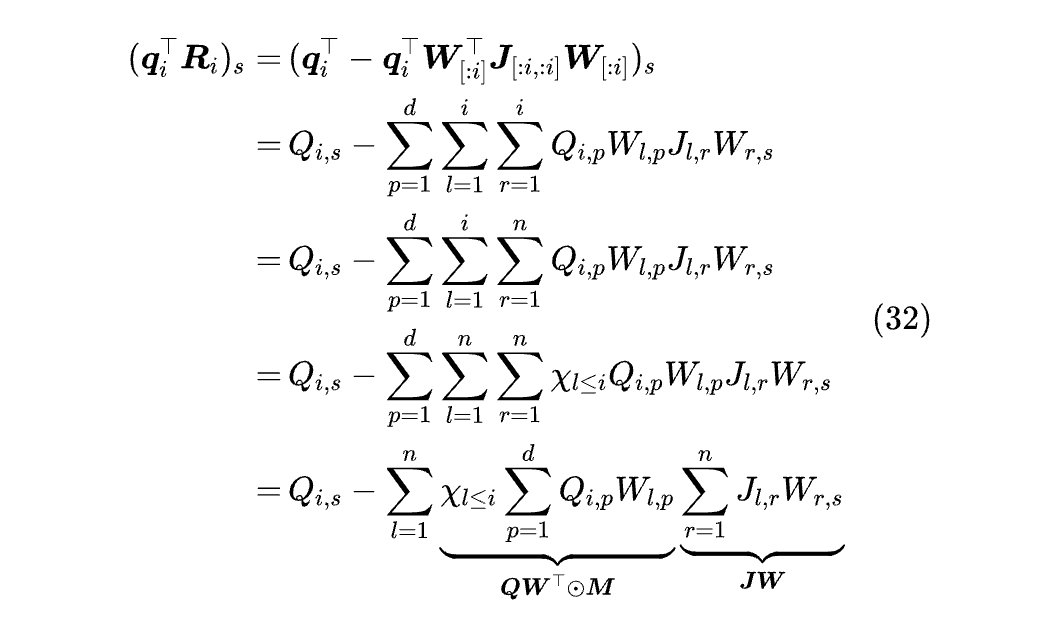
写成矩阵形式就是:
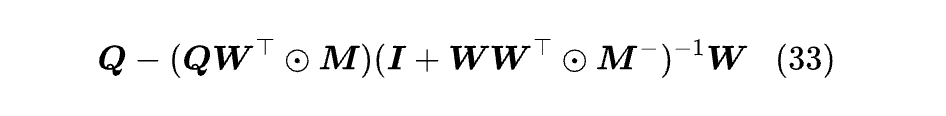
是不是又觉得有点熟悉?其实第二部分就是 DeltaNet (Q,W,W)!所以这种情况下 PaTH 实现的效果等价于是:
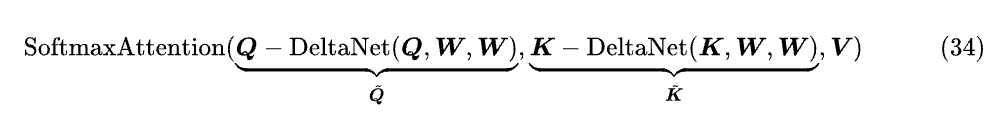
也就是用 DeltaNet 给 Q,K 加位置编码。这样看 PaTH (在 ‖w‖=√2 这个约束下) 就相当于 Softmax Attention 与 DeltaNet 的某种层内混合。
当然我们也可以考虑放弃前面的推导,即便 ‖w‖≠√2 时也按照上式来实现,这就类似于通过 Canon Layers [32] 的方案,用卷积给 Q,K 加位置信息了,只不过这里的卷积不再是短卷积,而是 DeltaNet 这种长卷积。
十、剑走偏锋法
最后,我们再看最近的一个同样值得关注的线性 Attention 模型 ——MesaNet (还有一个大同小异的同期工作 Atlas [33])。
TTT 的 Online Learning 视角告诉我们,DeltaNet 其实就是在用 SGD 优化目标函数 ℓ(S;k,v)=1/2‖Sk - v‖²,而我们仔细观察就会发现,ℓ(S;k,v) 只是 S 的线性函数,所以这实际上只是一个线性回归问题,线性回归是有解析解的!
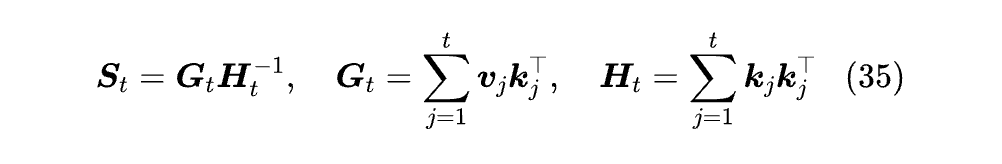
MesaNet 就是利用这个解析解来构建序列模型的,其想法起源于《Uncovering mesa-optimization algorithms in Transformers》[34],高效训练则是由《MesaNet: Sequence Modeling by Locally Optimal Test-Time Training》[35] 实现。
MesaNet 在上述公式基础上给 Gₜ,Hₜ 加入遗忘门,然后求时加上对角阵 Λₜ 避免不可逆,总的模型是:
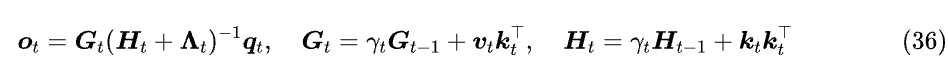
很明显,Gₜ,Hₜ 关于序列长度的复杂度是线性的,所以 MesaNet 的计算复杂度也是线性的,因此 MesaNet 仍然属于线性 Attention 的范畴,并且由于解析解的缘故,基本上可以保证大多数情况下它优于 DeltaNet 甚至 Gated DeltaNet。
从信号处理的角度看,MesaNet 与 DeltaNet 是 Recursive Least Square [36] 和 Least Mean Square [37] 的区别。
看上去都是优点,为啥笔者会将它归入 “剑走偏锋” 呢?在笔者看来,MesaNet“成也解析解,败也解析解”,解析解使得它通常优于 DeltaNet,但也给人一种 “到此为止” 的感觉,因为只要稍变一下就几乎没有机会求得解析解了。
纵观整个数学史,所有依赖于解析解的分支在今天几乎已经都没落了,因为解析解实在太稀罕、太没有代表性了。
从实现上来看,MesaNet 需要求逆的矩阵 Hₜ + Λₜ 并不是三角阵,尽管它仍然可以转化为解方程而不需要显式逆,但非三角阵仍使得它求解复杂度会增加不少。
如何尽可能低成本地并行计算全体 (Hₜ + Λₜ)⁻¹qₜ 将会是 MesaNet 长期的难点,目前论文用到的是 “共轭梯度法” 求近似解,能用但并不完美。
再就是从理论能力上看,MesaNet 也并非严格优于 DeltaNet。这是因为 MesaNet 的 Gₜ,Hₜ 更新规则还是简单的滑动平均形式,它的求逆也不涉及到 Token 之间的交互,所以它的能力极限大概不如拥有 Delta Rule 的 DeltaNet。
直观理解就是,MesaNet 会尽力记住全体 k,v,这在多数情况下是好事,但某些情况下会导致比较模糊的记忆,而 DeltaNet 的原则是 “除旧迎新”,因为 “除旧” 的缘故,它可以实现长期、精准地记忆某些内容。
总的来说,MesaNet 是一个让人赏心悦目的模型,但解析解也增加了它的复杂性和限制了它的灵活性,留下了不少亟待探索的空间。如果读者想要了解更多基于线性回归来构建序列模型的内容,还可以阅读 TTR [38],它对各种线性回归目标下的序列模型做了详细讨论。
十一、方兴未艾路
本文简要梳理了线性 Attention 的发展脉络,并介绍了部分模型的数学原理。线性 Attention 从模仿 Softmax Attention 起步,逐渐发展出自身特色,如今已成为极具竞争力的序列建模方案,甚至反过来为 Softmax Attention 的发展提供了新思路,这一过程本身充满了趣味性和启发性。
参考文献
[1] https://papers.cool/arxiv/2205.14135
[2] https://papers.cool/arxiv/2103.02143
[3] https://papers.cool/arxiv/2210.10340
[4] https://papers.cool/arxiv/2307.08621
[5] https://papers.cool/arxiv/2501.08313
[6] https://papers.cool/arxiv/2506.09507
[7] https://papers.cool/arxiv/2210.04243
[8] https://papers.cool/arxiv/2312.00752
[9] https://papers.cool/arxiv/2405.21060
[10] https://en.wikipedia.org/wiki/Prefix_sum
[11] https://papers.cool/arxiv/2312.06635
[12] https://papers.cool/arxiv/2407.04620
[13] https://openreview.net/forum?id=rJY0-Kcll
[14] https://papers.cool/arxiv/2501.00663
[15] https://papers.cool/arxiv/2505.23884
[16] https://papers.cool/arxiv/2212.10559
[17] https://papers.cool/arxiv/2406.06484
[18] https://papers.cool/arxiv/2102.11174
[19] https://en.wikipedia.org/wiki/Delta_rule
[20] https://en.wikipedia.org/wiki/Least_mean_squares_filter
[21] https://papers.cool/arxiv/2412.06464
[22] https://papers.cool/arxiv/2506.02475
[23] https://papers.cool/arxiv/2502.10297
[24] https://kexue.fm/archives/8601
[25] https://papers.cool/arxiv/2108.12409
[26] https://papers.cool/arxiv/2503.02130
[27] https://papers.cool/arxiv/2505.19488
[28] https://papers.cool/arxiv/2505.16381
[29] https://en.wikipedia.org/wiki/Householder_transformation
[30] https://kexue.fm/archives/8453
[31] https://papers.cool/arxiv/2405.18719
[32] https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5240330
[33] https://papers.cool/arxiv/2505.23735
[34] https://papers.cool/arxiv/2309.05858
[35] https://papers.cool/arxiv/2506.05233
[36] https://en.wikipedia.org/wiki/Recursive_least_squares_filter
[37] https://en.wikipedia.org/wiki/Least_mean_squares_filter
[38] https://papers.cool/arxiv/2501.12352
文章改编转载自微信公众号:PaperWeekly
原文链接:https://mp.weixin.qq.com/s/LqHLYKJ1upeseNJy-TEF_g | 





















