本帖最后由 离子 于 2025-8-5 06:33 编辑
本文介绍一种结合变分自编码器(VAE)与贝叶斯双向长短期记忆网络(BiLSTM)的太阳能发电预测技术。该方法通过贝叶斯 BiLSTM 量化预测不确定性,用 VAE 压缩模型参数解决高维度问题。实验显示,与传统贝叶斯 BiLSTM 相比,其权重参数减少 97.35%(从 76422 个减至 2022 个),计算时间缩短 37.93%,均方根误差(RMSE)降低 9.1%,平均绝对误差(MAE)降低 30%,在提升预测精度的同时大幅提升效率,为电网稳定运行提供有力支持。
你家屋顶的太阳能板每天能发多少电?这个问题看似简单,却关系到整个电网的稳定运行。随着太阳能、风能等可再生能源的普及,越来越多的分布式发电设备(比如千家万户的太阳能板)接入电网。但可再生能源有个大麻烦 —— 间歇性:晴天发电多,阴天发电少,晚上甚至不发电。这种波动性给电网调度带来了巨大挑战:发多了用不完浪费,发少了又得紧急调用备用电源,既不经济也不环保。
传统的太阳能预测方法要么不够准,要么太耗时。比如普通的深度学习模型(如 LSTM)虽然能做预测,但只能给一个 "点预测"(比如明天中午发 1.2 度电),没法告诉我们这个预测有多可靠;而贝叶斯方法虽然能量化不确定性(比如 "明天中午有 90% 概率发电 1.0-1.4 度"),但模型里的参数太多(称为 "高维度问题"),计算起来慢得让人着急。
于是,科学家们一直在思考:能不能结合两种方法的优点,既准确又高效地预测太阳能发电量?最近在《Energy and AI》上发表的一篇文章,就提出了一个巧妙的解决方案 ——VAE - 贝叶斯 BiLSTM 模型。

一、三大突破解决核心难题
这篇论文的核心目标是:在准确预测太阳能发电量的同时,量化预测的不确定性,还要让模型跑得更快。为了实现这个目标,研究团队做出了三个突破:
1. 开发了贝叶斯 BiLSTM 模型,搞定 "不确定性"
普通的 BiLSTM(双向长短期记忆网络)能同时利用过去和未来的信息提升预测 accuracy,但它输出的是确定值,没法告诉我们 "这个预测有多靠谱"。而贝叶斯 BiLSTM 给模型的权重参数加上了概率分布(比如假设权重符合正态分布),这样就能输出 "预测区间"(比如 "有 90% 的可能,发电量在 0.8-1.5 度之间"),完美量化了不确定性。
2. 用 VAE 降维,解决 "计算慢" 的问题
贝叶斯模型虽然好,但参数太多了。比如传统贝叶斯 BiLSTM 的权重参数可能高达 76,422 个,计算起来非常耗时。研究团队引入了 VAE(变分自编码器),它能像 "数据压缩机" 一样,把高维度的权重参数压缩到低维度(比如从 76,422 压缩到 2,022),同时尽量保留关键信息。这样一来,模型的计算效率大大提升。
3. 全面验证,证明方法真的好用
团队用实际数据(来自澳大利亚 300 户家庭的太阳能发电记录)做了大量实验,对比了 8 种主流方法(比如贝叶斯 LSTM、贝叶斯 RNN 等)。结果显示,新方法在预测 accuracy、不确定性量化、计算速度上都显著优于其他方法。
二、具体思路
这个 VAE - 贝叶斯 BiLSTM 模型的工作流程,可以分成 "降维" 和 "预测" 两大步,就像先把复杂的数据 "打包压缩",再用压缩后的信息做精准预测。
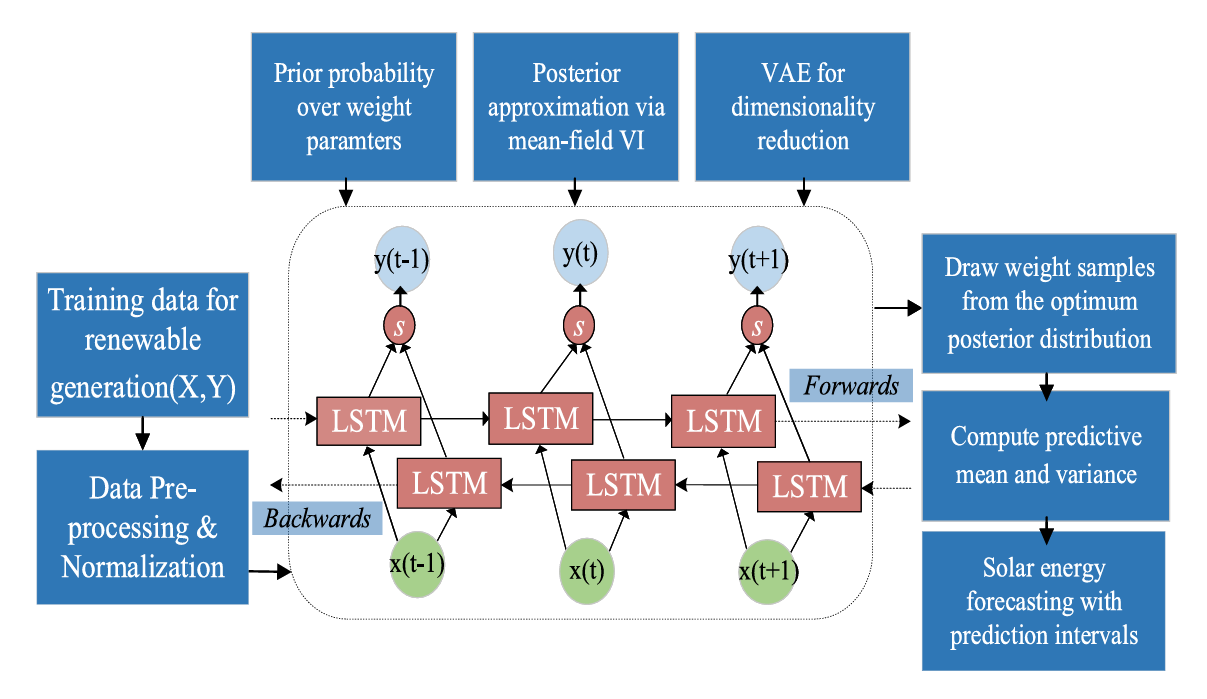 图1 VAE - 贝叶斯 BiLSTM 模型系统架构图 图1 VAE - 贝叶斯 BiLSTM 模型系统架构图
1. 第一步:用贝叶斯 BiLSTM 处理不确定性
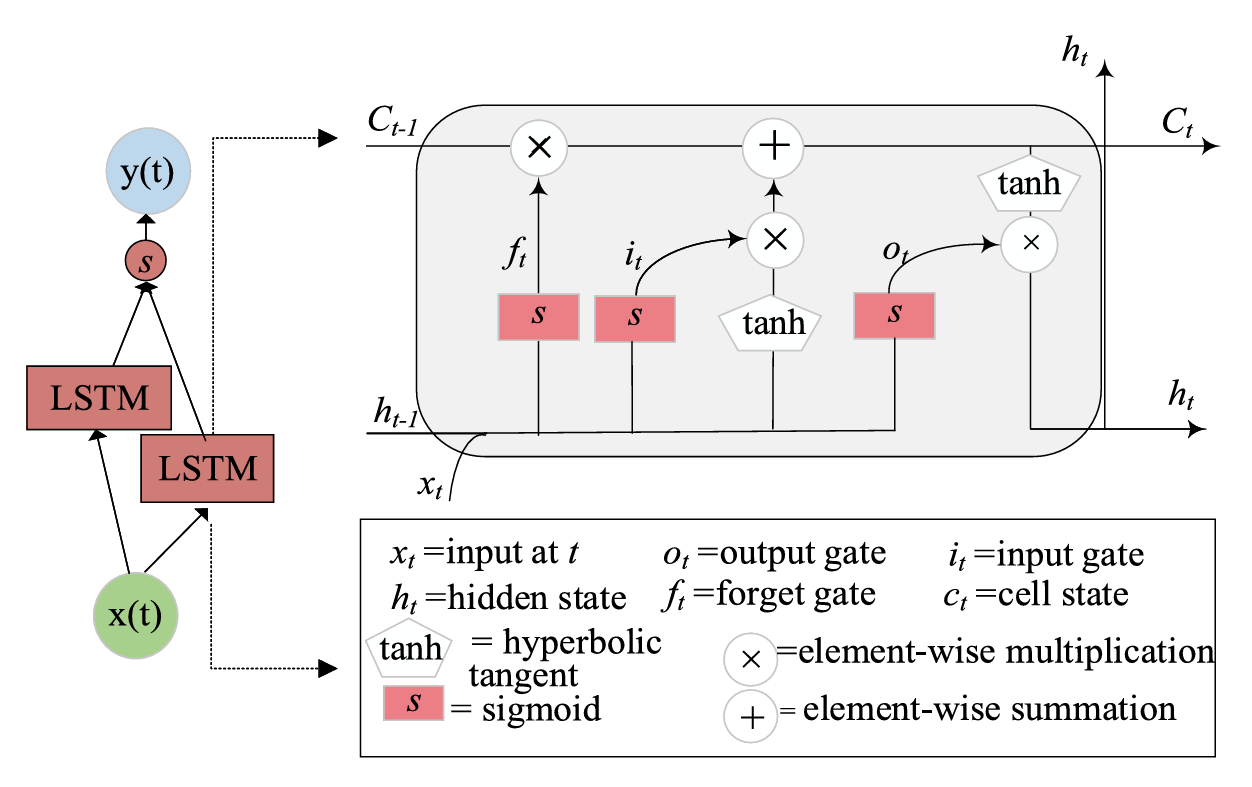 图2 双向长短期记忆网络(BiLSTM)架构示意图 图2 双向长短期记忆网络(BiLSTM)架构示意图
贝叶斯方法的核心是 "用概率描述不确定性"。在模型里,每个权重参数不再是一个固定值,而是一个概率分布。比如,我们假设权重的先验分布是正态分布
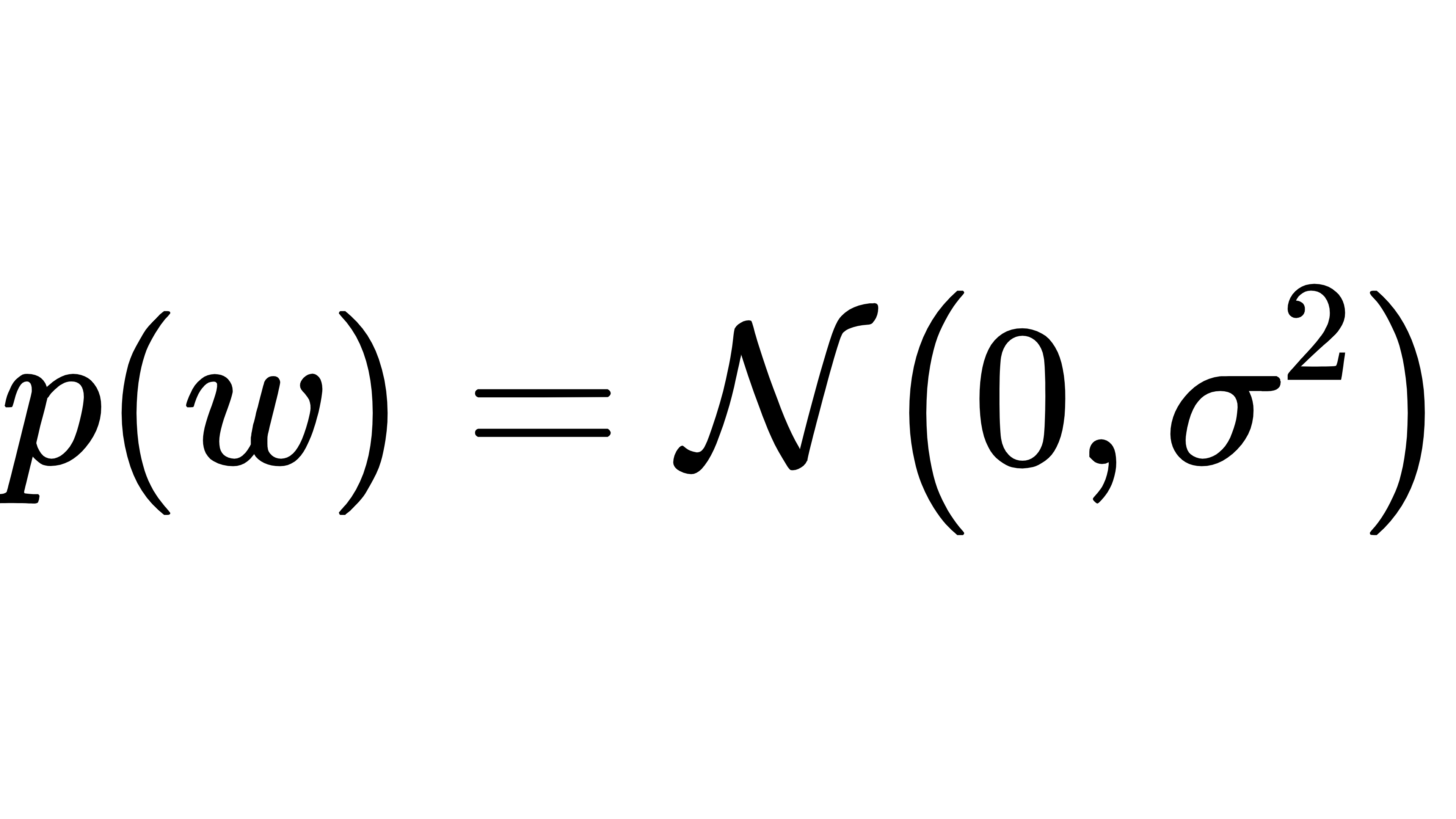
然后根据观测数据更新这个分布,得到 "后验分布"p(w|D)。
后验分布的计算用了贝叶斯公式:
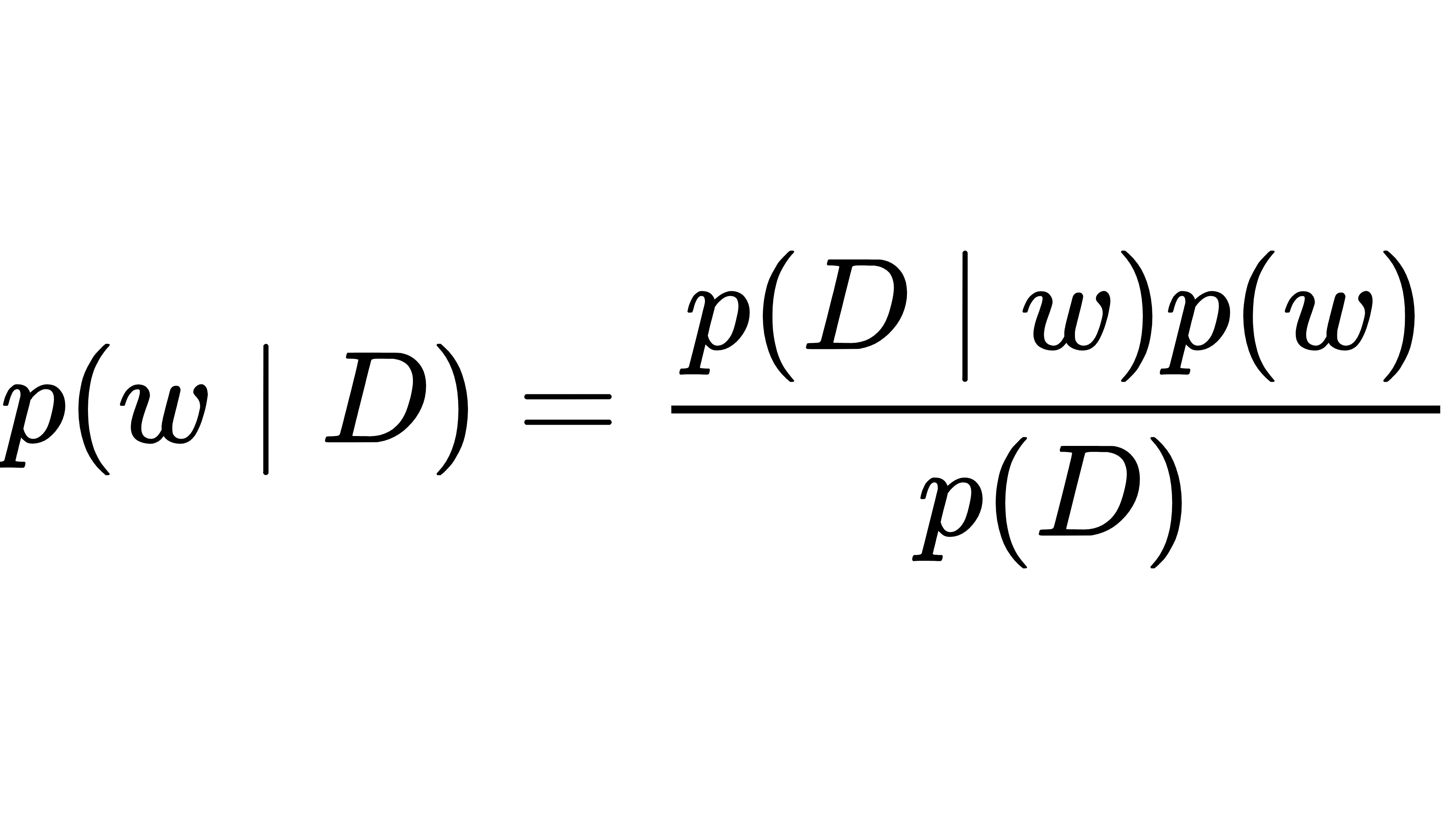
其中,p(D|w) 是 "似然性"(给定权重时数据出现的概率),p(w)是先验分布,p(D)是边际概率(归一化常数)。
但直接计算后验分布太复杂了,研究团队用了均值场变分推断(MFVI) 来近似它。简单说,就是假设后验分布可以拆成多个独立的分布(因子化):
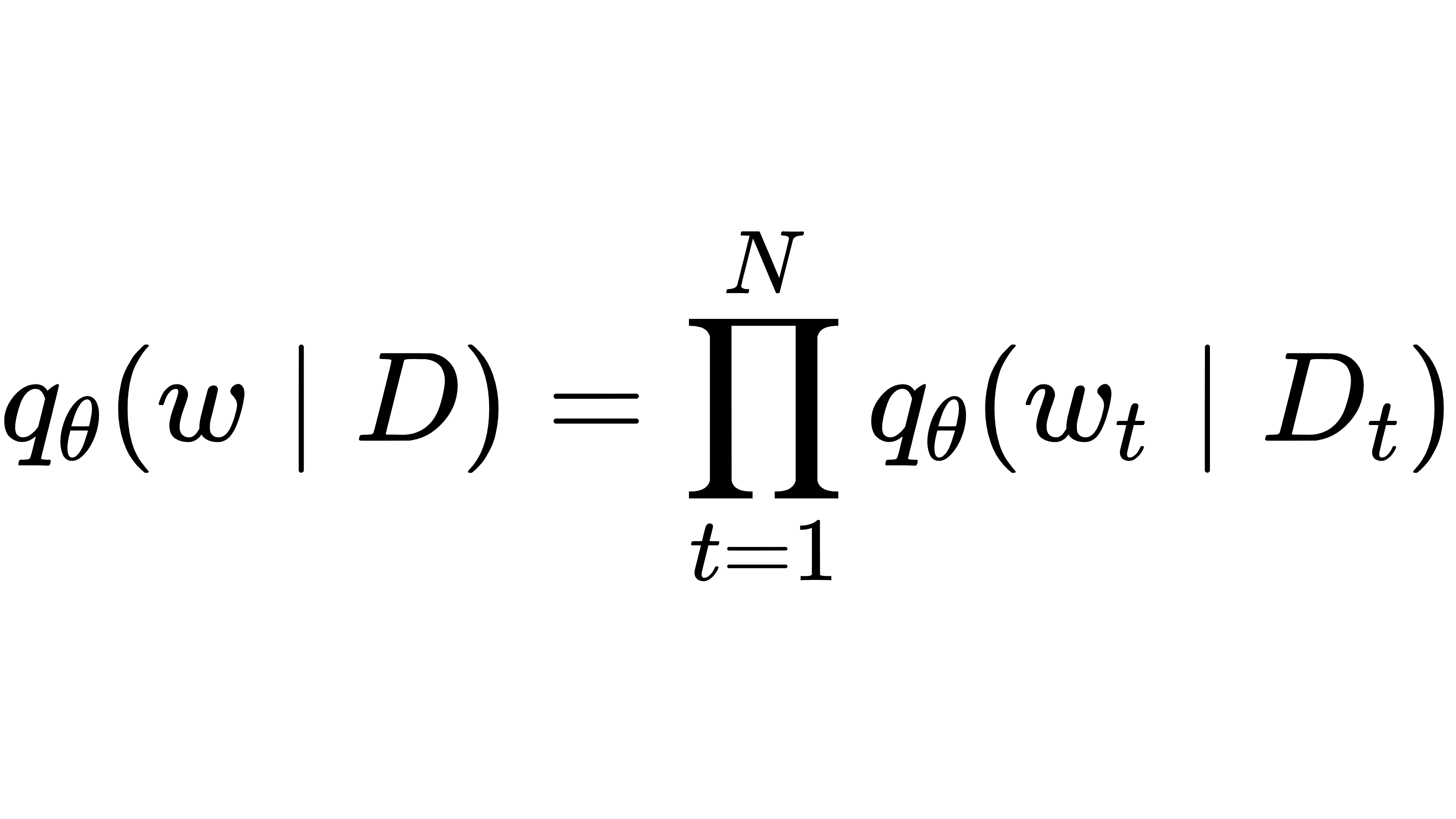
然后通过最小化 "KL 散度"(衡量两个分布的差异)来优化近似:
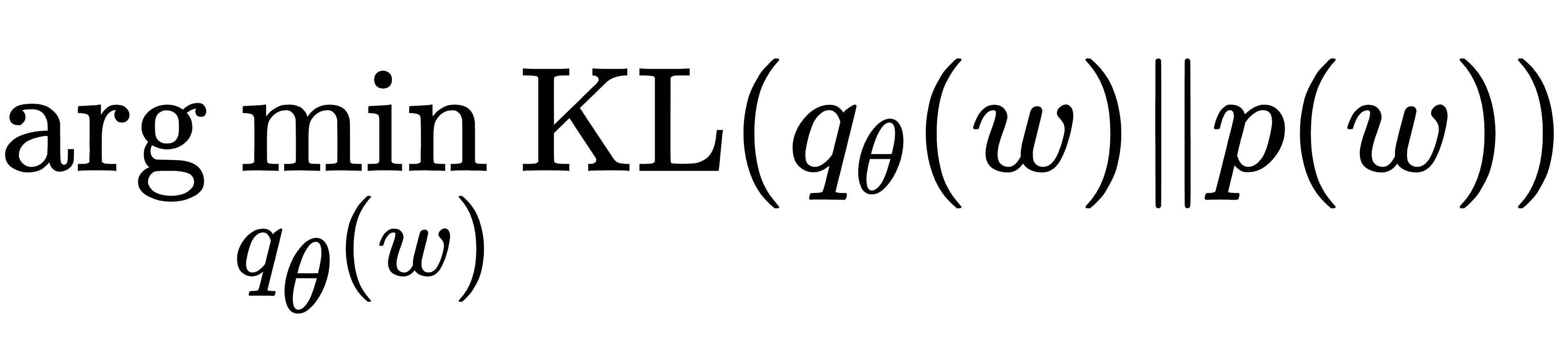
为了方便计算,团队还引入了 "证据下界(ELBO)",把最小化 KL 散度转化为最大化 ELBO:
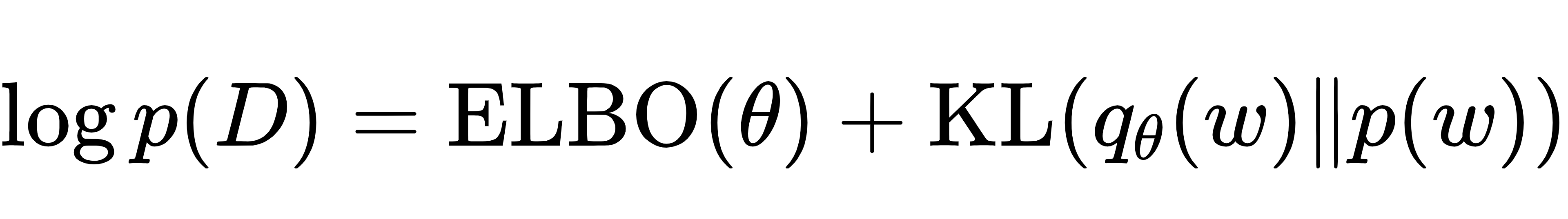
这一步保证了模型在量化不确定性的同时,不会牺牲预测 accuracy。
2. 第二步:用 VAE 压缩权重参数
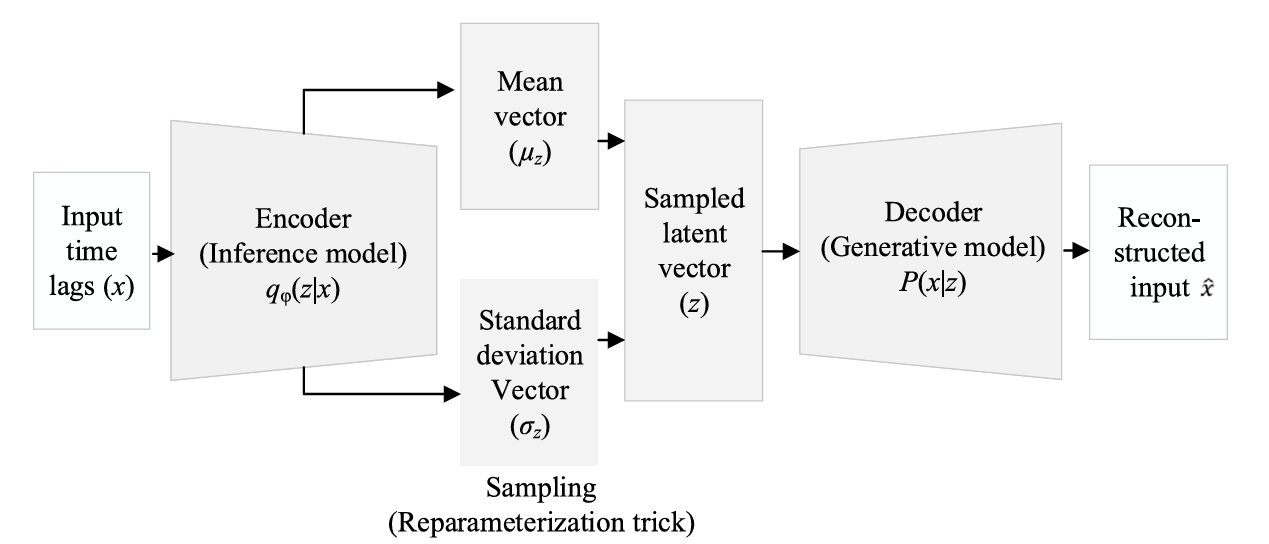 图3 变分自编码器(VAE)架构原理示意图 图3 变分自编码器(VAE)架构原理示意图
贝叶斯 BiLSTM 虽然解决了不确定性,但权重参数的维度太高(比如上万个),计算起来很慢。VAE 的作用就是给这些参数 "瘦身"。
VAE 由 "编码器" 和 "解码器" 两部分组成:
编码器:把高维度的权重参数 w 压缩成低维度的 "潜在变量" z,并输出 z 的概率分布(比如均值 μz 和标准差 σ z);
解码器:从 z 还原出原始权重参数,通过 "重建误差" 确保压缩过程没有丢失关键信息。VAE 的损失函数包含两部分:
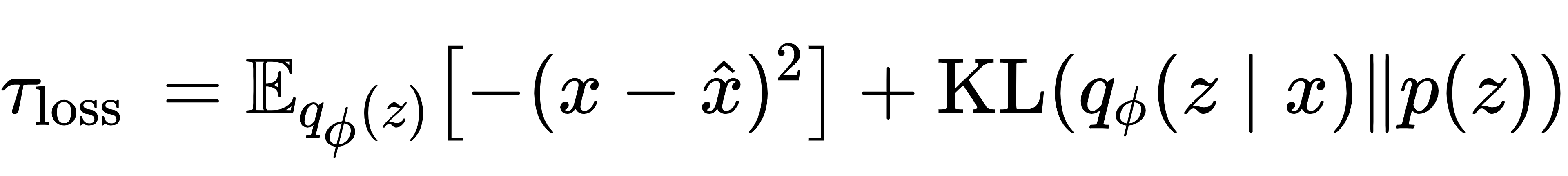
其中,第一项是 "重建损失"(衡量还原的准确性),第二项是 KL 散度(确保压缩后的分布更接近标准正态分布,方便计算)。
通过这个过程,原本 76,422 个权重参数被压缩到 2,022 个,既减轻了计算负担,又没丢关键信息。
3. 整体流程
数据预处理:把太阳能发电数据(每 30 分钟记录一次)归一化,分成训练集和测试集;
VAE 压缩:用编码器把贝叶斯 BiLSTM 的高维权重压缩成低维潜在变量;
贝叶斯预测:用压缩后的权重训练贝叶斯 BiLSTM,输出预测均值和预测区间;
评估优化:通过最小化损失函数(结合重建误差和 KL 散度),让模型更准、更快。
三、实验验证
研究团队用澳大利亚 300 户家庭的太阳能数据(2011-2012 年,每天 48 个记录)做了实验,对比了 8 种方法,结果相当亮眼。
1、预测更准
表1 VAE - 贝叶斯 BiLSTM 与其他方法性能对比表
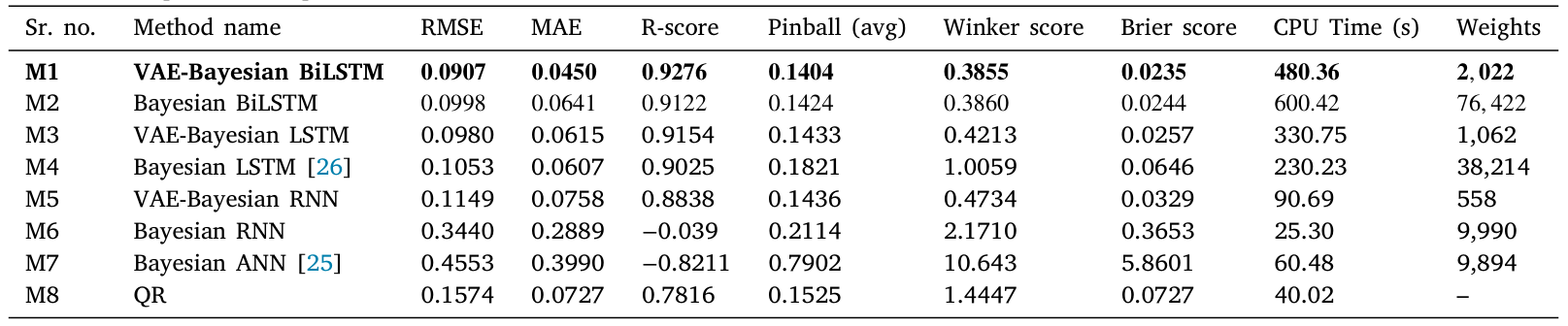
注:RMSE 和 MAE 越小,预测越准;Pinball 损失越小,预测区间越可靠。
2. 计算更快
权重参数:从 76,422 个压缩到 2,022 个,减少了97.35%;
计算时间:处理 6 个月数据时,从 232.81 秒缩短到 144.49 秒,快了37.93%。
3. 适用范围广
无论是 1 年的长期数据、6 个月的中期数据,还是 1 天内的短期数据,新方法都表现稳定。比如在日内预测(9 小时峰值时段)中,RMSE 从 0.1143 降到 0.0948,提升了 17.06%。
四、总结
这篇论文提出的 VAE - 贝叶斯 BiLSTM 模型,完美结合了贝叶斯方法(量化不确定性)和 VAE(降维提速)的优点,解决了太阳能预测中的两大核心难题:
· 既能给出 "明天发电量有 90% 概率在 1.0-1.4 度" 这样的可靠区间,又能保证预测值足够精准;
· 权重参数压缩近 97%,计算速度提升超 37%,让模型在实际电网调度中更实用。
未来,随着可再生能源占比越来越高,这样的预测技术将成为电网稳定运行的 "定海神针"—— 既让清洁能源用得更高效,也能帮助各行各业省下不少电费。
论文链接:A VAE-Bayesian deep learning scheme for solar power generation forecasting based on dimensionality reduction - ScienceDirect | 





















