本帖最后由 Jack小新 于 2025-8-6 17:38 编辑
大家都说数据同化中用到的数学公式太多,这是初学者接触数据同化相关内容的最大劝退项。本文尝试用尽可能少的公式来说明数据同化方法的原理和不足。也许介绍的内容没有那么严谨,缺少一些细节,但是可以避免让初学者迷失在数学公式的森林中。
01 同化问题的描述
数值模式预报的效果依赖于初始条件,而初始条件的获取非常依赖于数据同化技术 —— 一种将来自不同来源、不同精度的数据整合到一个统一的初始场中的方法。数据同 化不仅需要观测数据,还需要被称为背景场的模式数据。观测数据虽然提供了对真实系 统状态的最直接信息,但往往存在空间和时间上的不连续和数据缺失的情况;并且由于 观测手段的限制,也存在一定程度的不确定性。背景场来自于数值模式的自由积分结果,为数据同化提供了一个起点,帮助同化算法更好地融合观测数据。如果没有背景 场,数据同化将缺乏对系统状态的先验估计,难以有效整合观测数据,也难以保证同化结果具备足够的物理意义。背景场的作用是补充观测数据的不足,并提供一个合理的物理背景。
所以同化算法本质上就是结合背景场和观测数据的数学方法,其能提供不确定性最小模式状态,作为数值模式的初始条件。同化算法的输出实质上是被观测数据更新过的背景场,在术语中,这被称为分析场。由于背景场和观测数据往往是不匹配的,所以一般情况下需要使用一个函数,将背景场的数值转移到观测位置,或者将观测数据补充成背景场的尺寸,这才能使得两者可以比较 (举个不恰当的例子,A 班有 31 人,B 班有 23 人,直接进行拔河比赛肯定是不合适的,为了公平比赛,需要让 A 班只出场 23 人,或者给 B 班补到 31 人)。读者不妨思考一下上面两种功能哪一个更容易实现?试想一下,如果 观测数据足够多,能找到一个函数将观测数据补充成背景场的尺寸,并且不会导致较大 的误差或者动力不平衡,这三个条件都能满足的话,那么,我们根本就没有必要使用背 景场。所以实际同化问题的描述中都是将背景场投影到观测空间,我们姑且把实现该功能的函数称为观测算子。
02 Nudging 方法
我前面说” 一般情况 “需要使用观测算子,那自然就有不一般的情况。假如观测数据本身和背景场同尺寸,或者我们同化的是别人的网格化 “再分析数据” 的话,就可以不使用观测算子。对应的同化方法被称为 “牛顿松弛逼近法”(nudging), 这种方法通过在模式的控制方程中加入一个强迫项,使得模型的状态逐渐向观测数据靠近来实现。我不知道 为什么 Nudging 方法会被翻译成牛顿松弛逼近法,毕竟它没有” 牛顿 “, 也一点儿都不” 松弛 “(relaxation)。直白地说,该方法就是字面上的意思,就是一种把模式结果” 推 “(nudging) 向观测的方法,所以做同化的人不到万不得已都不会用中文称呼该方法。 Nudging 方法是一种比较简陋的同化方法:第一,所谓的” 再分析 “就是别人的同化产品,同化别人已经做好的产品虽是提供模式初值的无奈之举,但总会让人觉得是在偷懒;另一方面,nudging 方法默认了观测 (或” 再分析 “) 是完全精确的,在同化中忽略了观测的不确定性,不够客观。
03 最优插值 / 三维变分
那么,以下就开始介绍一般情况下需要使用观测算子的客观同化方法。从最简单的线性观测算子开始介绍是一种较符合常理的路线:我们写第一个式子来表示观测算子,即
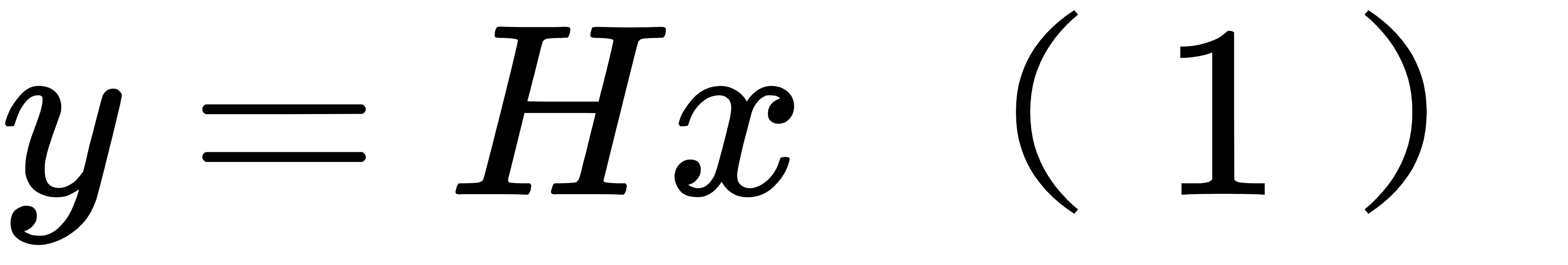
其中x是和背景场尺寸一致的状态变量,y是和观测尺寸一致的变量,观测算子使用线性 观测矩阵H来进行数据的转移。一个很关键的点是,客观的同化方法需要同时考虑背景 场和观测数据的不确定性,以便平衡二者提供一个不确定性更小的分析场。所以背景场 和观测不能被视为确定性变量,而都应假设为随机变量,分别记为 xb 和 yo , 这里的上标 b代表 background,o代表 observation。在统计学中,随机变量的不确定性一般由方差表示。但是在实际的同化问题中,背景场通常是矢量,以表示模式不同网格点上的不同物 理量值;观测也是矢量,代表众多观测位置的物理量值。因此,背景场和观测的不确定性分别由两个误差协方差矩阵 Pb和R表示,它们都是对称正定阵,分别被称为背景误差协方差矩阵和观测误差协方差矩阵。我们不妨就简称它们为 B 矩阵和 R 矩阵。
同化问题中,提供给我们的素材是背景场 xb 和观测值 yo , 两者的不确定性分别由 B 矩 阵和 R 矩阵表示,而我们想要组合背景场和观测得到分析场记为 xa (a 代表 analysis)。 yo - Hxb 的引入使得背景场和观测值可比,即 yo - Hxb 是一个合法的矢量运算,得到的值我们也 用一个专有名词来称呼它,称”innovation“(有的书将它翻译成” 新息 “)。我们可以把客观 的同化算法理解为一个用新息来调整背景场的公式,即:
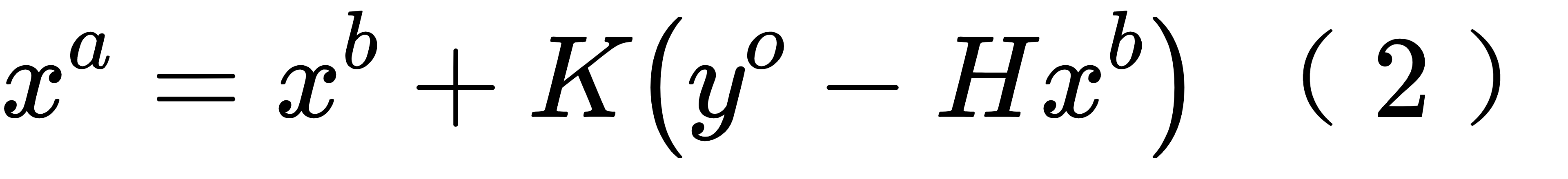
其中的” 调整系数 “ K 应该是一个矩阵,行数为背景场的维数,列数为观测的维数。计算随 机变量 xa 的误差协方差矩阵 Pa , 可得到一个包含 Pb 和R的表达式。须知 K 是待定的,我们可 以要求分析误差协方差矩阵 Pa 的秩最小,解出对应的K, 结果如下:
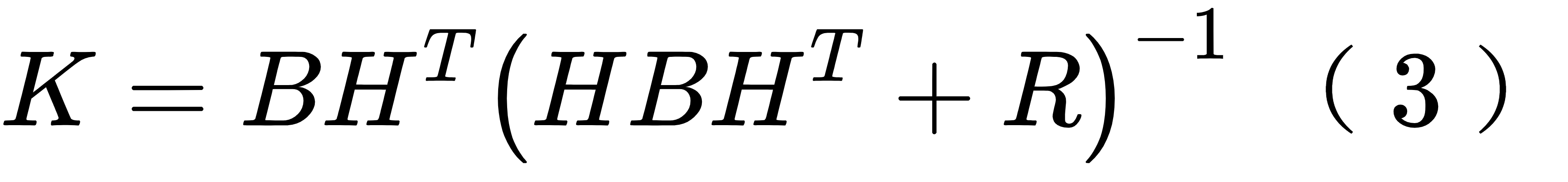
上标T代表矩阵转置。 K 是新息的权重,它由我们预先提供的 B 矩阵、R 矩阵和观测矩阵 H 决定 (注意我没称呼 H 为观测算子,因为严谨地说,左乘矩阵 H 的这个操作才应该被称为 观测算子,H 只是观测矩阵)。这个同化公式被称为最优插值 (OI) 公式,它和三维变分 (3D-Var) 是等价的。三维变分方法是通过最小化代价函数得到相同的更新公式,这里 不过多赘述。
OI 或 3D-Var 里面的关键问题就是 B 矩阵和 R 矩阵该如何提供。R 矩阵相对容易确定,毕竟是观测误差,可以根据观测设备的实际情况确定,也可以假设所有的观测都是独立同分布的 —— 即忽略观测数据之间的相关,将 R 矩阵假设为对角阵。而 B 矩阵的确定方式是最优插值或三维变分的重点和难点。这是因为 B 矩阵除了需要描述各点误差的方差大小 以外,还需要提供误差的空间分布,需要考虑变量之间的相关性。所以使用对角的 B 矩 阵是一种非常差的选择,因为这完全忽视了同一变量在不同位置的连续性和不同变量之间的物理相关。基于经验或统计的方法是设定 B 矩阵的常用方式。例如,如果有多组历史数据或模式模拟结果,可以利用这些数据计算样本协方差矩阵作为 B 矩阵的估计,这样可以直接从数据中估计变量之间的相关性。此外,如果已知变量之间的相关性,可以利用相关系数矩阵来构造 B 矩阵。这些方法中,样本数据的质量和数量对 B 矩阵的估计精度至关重要。
上面的方法虽然可用,但是还存在很大的问题,因为它假设 B 矩阵是固定的,一旦确 定,它在整个同化流程中就是不变的。固定的 B 矩阵无法捕捉背景误差随时间、季节或 地理位置的动态变化,可能导致分析结果的偏差。固定的 B 矩阵的上述特性被称为 “非流依赖性”(flow independent)。对应地,如果 B 矩阵的结构和参数会随时间和空间动态变 化,以反映背景场的物理特性,我们就称呼此时的背景误差协方差是流依赖 (flow dependent) 的。这个词很有意思,不妨想想为什么这么命名,这里的 “流” 到底是指何 意?个人观点:这里的流应该是” 相空间 “中的流 —— 在相空间中,系统的运动可以被看 作是一条轨迹,这条轨迹被称为相流 (Phase Flow), 相流描述了系统状态随时间的演 变过程。流依赖意味着 B 矩阵的值是依赖于动力状态在相空间中的位置的。
04 卡尔曼滤波
要让 B 矩阵具备流依赖性,就得让 B 矩阵随着模式积分动态更新。这里就不得不再用一 个公式描述模式积分,仍然先假设线性模式,即
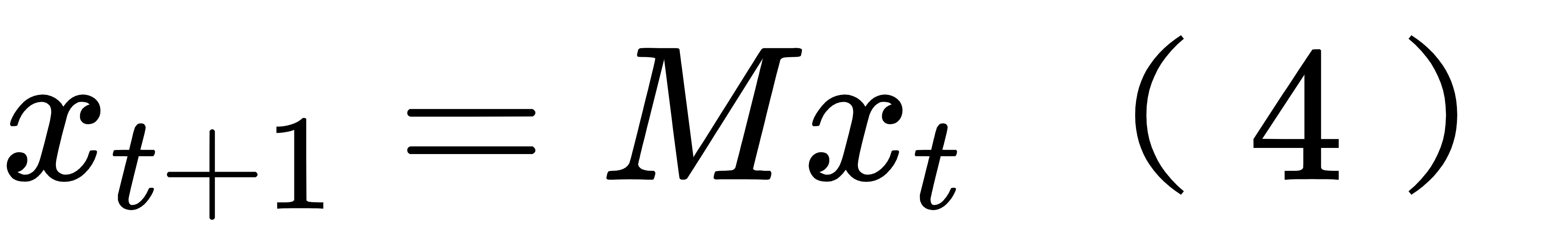
这里将对 t 时刻的模式初值 xt 的积分过程表示为左乘转移矩阵 M。转移矩阵 M 实质上是常 微分方程的求解器。比如用欧拉法求解常微分方程的初值问题 dx/dt=f(x,t),x(t0)=x0 就可以写成上述形式,其中 M = I + \Delta t f'(xt) 。用龙格库塔法积分则对应一个稍复杂一些 的 M, 但也是可以写出来的。我们实际用模式的时候不会显式表达 M, 但是知道它的概念就行了。基于模式积分,可以获取 B 矩阵的更新公式,
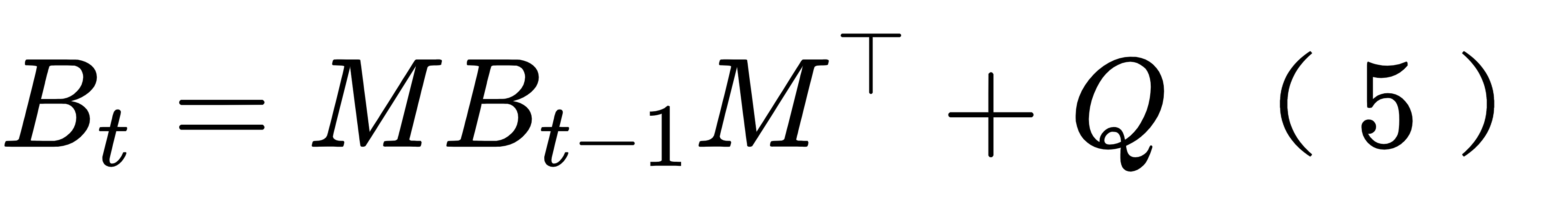
其中 Q 是模式误差协方差,是模式误差的一种刻画。如果假设模式完美,可以让 Q 为零矩阵。(5) 式是模式积分过程中的 B 矩阵演化。而在同化的那一步,我们利用背景场和观测获取了一个不确定性更低的分析场,所以分析场的背景误差协方差是小于背景场的 B 矩阵的,此时的更新式为
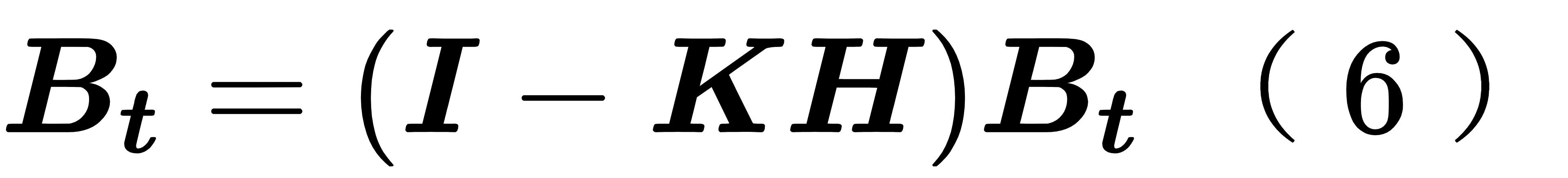
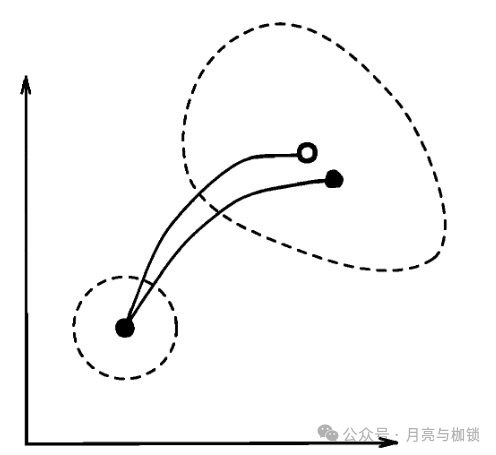
公式 (5) 和 (6) 构成了 B 矩阵的更新公式,配套 (4) 的模式积分,(3)(2) 的状态更新,构成了” 预报 - 分析 “的循环过程。在状态空间,是用 (4) 积分到观测时刻,然后用 (2) 更新状态,然后再继续积分;在背景误差协方差空间,交替使用 (5) 和 (6) 让 B 矩阵流依赖,这种方法叫做卡尔曼滤波 (Kalman Filter,KF)。
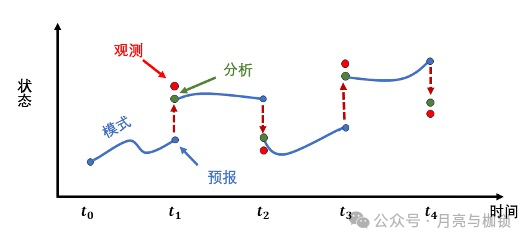
补充说明一下三维变分的” 三维 “体现在哪里。可以看到公式 (2)(3) 中不需要使用时间的 下标,它只是在进行分析的一个瞬间起作用,对应图中的话,就是 ta 那个瞬间的一个箭头,3D-Var 并不需要关系模式积分是怎么样的。术语里的 “三维” 指的是物理空间上的三 个维度 (x,y,z)。而卡尔曼滤波的示意图中,每个点都是相空间中的一个点,已经代表了 三维物理空间中的一个状态,横轴的时间就是第四个维度。也就是说,卡尔曼滤波是四维同化方法,需要关注三维物理空间中的状态和不确定性的时间演变,和四维变分 (4DVar) 是对应的。
05 扩展卡尔曼滤波
接下来我们可以放宽一个假设,假设数值模式是非线性的,即公式 (4) 被替换为
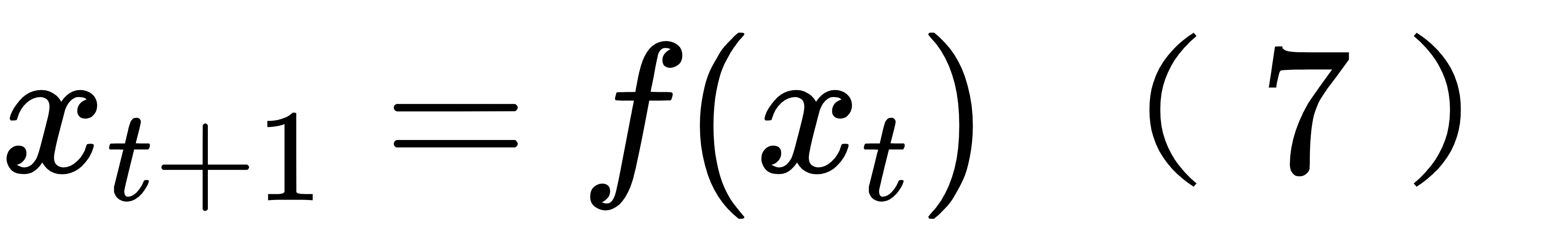
这种非线性模式在现实中更加常见,如 Lorenz1963 模式。在这种情况下,公式 (5) 失效,但是我们仍然可以使用卡尔曼滤波算法,只需要对 (7) 中的 f 进行线性化近似,计算 f 的雅克比矩阵 M 或者使用切线性模式代替 f (不妨仍然用式 4 表示这个切线性模式以少写一个式子), 这种情况下前面这一套卡尔曼滤波算法仍然可用,只不过我们换个名词,称之为扩展卡尔曼滤波 (EKF,Extended KF), 所以 EKF 是应用于非线性数值模式的 KF。
EKF 拓宽了 KF 的应用范围,使得我们不需要拘泥于线性动力系统。但是 EKF 也只能用 于非线性较弱的系统,因为线性化导致的截断误差会随着时间积累,造成整体误差越来 越大而失效。还有一个更严重的问题,就是 B 矩阵的循环。现实中,状态空间的维数是 非常高的,这是因为它代表了数值网格上的所有变量值,而数值模式的网格数往往能达 到数百万 ( 106 ) 的量级。在此情况下,进行公式 (2)(3) 的同化已经很勉强了。观察 (5) (6), 可以发现 B 矩阵的数据量是 x 的维数的平方倍,即 ( 1012 ), 这样的计算量在现实中根 本做不到。所以我们需要一种不直接演化 B 矩阵,但又能让 B 矩阵有流依赖的办法。
06 集合卡尔曼滤波
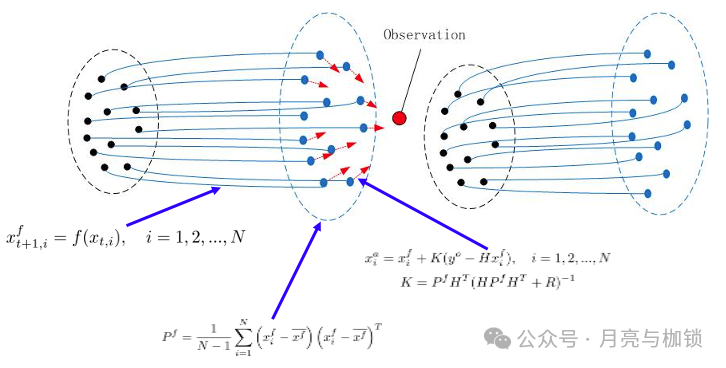
由于集合预报的概念逐渐为人所接受,用集合来表示状态变量的不确定性逐渐成为了 一种趋势。集合预报通过多次运行模型并引入不同的初始条件或参数扰动,来评估未来天气的不确定性。那么,使用集合成员计算背景误差协方差,然后放入公式 (3) 计算 K —— 该矩阵的术语是卡尔曼增益矩阵 —— 并进行背景状态的更新,成为一种避免 (5)(6) 的 有效策略。在这种思想下诞生的方法,就是集合卡尔曼滤波 (EnKF,Ensemble Kalman filter)。
EnKF 算法需要积分多份模式,得到多个背景场 —— 称背景集合, 然后利用背景集合估 计背景误差协方差,进行状态更新,更新每一个集合成员,最后再放回到模式中,进行 下一步的集合积分。EnKF 的同化公式和 EKF 的差别不大,只需要在 (7) 和 (2) 额外加上表 示集合成员的下标即可
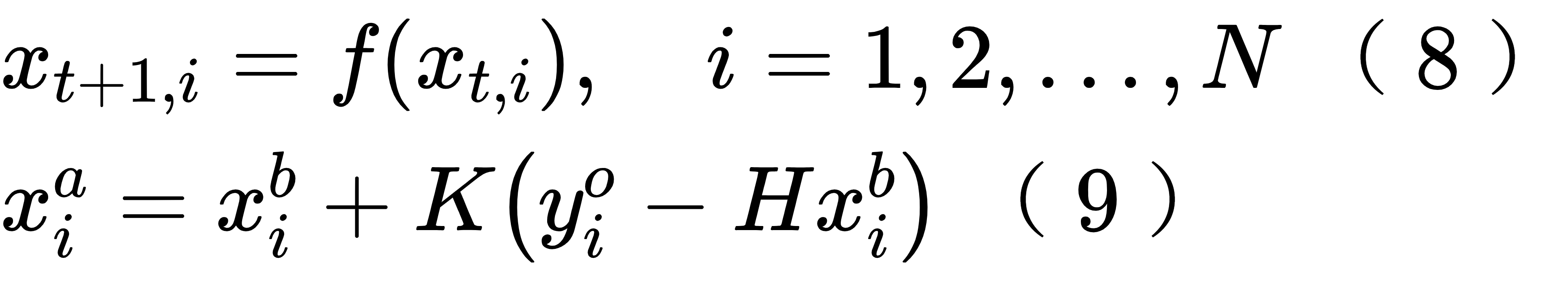
还是用 (3) 计算K, 只不过其中的 B 是集合成员的样本误差协方差矩阵。至于这里观测需要添加随机扰动这些,以及使用扩展方法 (集合平方根滤波器,集合调整卡尔曼滤波器等) 避免扰动观测等,这些都是 EnKF 思想实施过程中的技术细节,可以参考具体教材。
EnKF 看上去需要积分一个集合,计算量会提高不少。但是集合成员数是可控的,现实中一般使用数十到数百的集合成员就可以,这相比于 106 量级的 EKF 还是可行不少的。此外,EnKF 直接提供集合以进行集合预报,不需要使用奇异向量等扰动方案,也是 它的一种便利。
此外,EnKF 中使用集合计算背景误差协方差矩阵 B 避免了公式 (5) 的使用。但是公式 (5) 的模式误差 Q 被忽略了,在模式积分过程中,模式误差的作用没有办法体现,这导致了分析时刻的 B 矩阵的不确定性被低估。在这种情况下,一个补救办法就是人工增大 B 的数值,提高其不确定性,这个人为补救技术叫协方差膨胀 (inflation)。
另外,虽然可以只使用数十到数百个集合成员,但是如果状态空间的维数巨大的话,样本协方差还是难以完全逼近真正的背景误差协方差,往往会造成一些远距离的虚假相关,也需要一种人工技术抹除这些虚假相关,这种方法叫做协方差局地化 (localization)。这两样都是有人为因素的附加技巧,降低了 EnKF 方法的客观性,但却又是实际应用中必不可少的。
07 “线性 - 高斯分布假设” 的阴影
篇幅缘故,我先不介绍四维变分和粒子滤波器。这里介绍了最优插值到卡尔曼滤波到 集合卡尔曼滤波的这一套传统同化方法。总结来说,到此为止的数据同化实际上并没有 用到特别先进的数学工具。可以发现这里面真正重要的公式是 (3), 同化的关键问题就是以何种权重把从观测中得到的新息加到背景场中去。用更简单的话,就是如何用观测数 据调整背景场以使得分析场的不确定性最小。
公式 (3) 的实质是矢量形式的最小二乘法,因为如果 B 和 R 的尺寸相同 (即 H 为单位矩阵 I), 它其实就是 K=B /(B+R) , 对应的公式 (2) 退化为一个使用两个误差协方差矩阵的加权 组合公式。所以背景场和观测的不确定性量化 (Uncertainty Quantification) 在数据同 化中非常重要。为了给 B 矩阵提供流依赖性,后面又引入了卡尔曼滤波,将三维方法扩 展成四维方法。为了避免扩展卡尔曼滤波中的线性化问题以及 B 矩阵更新的巨大计算难 题,发展了集合卡尔曼滤波。这整个发展路线,都是为了给出更好的 B 矩阵,而公式 (3) 一直没有变过。
但是公式 (3) 隐含了一个非常大的问题,导致了目前传统同化的根本性缺陷。但凡提到 传统同化方法的不足,我们言必及 “线性 - 高斯分布假设”, 然而我们在 EKF 中就已经适用 非线性模式了,这个” 线性 - 高斯分布假设 “到底说的是什么呢?
一个根本性的问题,不确定性是否等价于误差协方差矩阵的大小?在自然界中,高斯分布 (正态分布) 是一个完美的分布,因为它仅使用均值和方差这两个关键参数就可以完全确定其形状和位置。许多自然现象和社会现象的数据分布接近高斯分布,如人的身高、体重、智商;工业产品的尺寸、重量;收入分布、股票价格等。然后概率论中最著名的中心极限定理也表示 —— 大量独立同分布的随机变量之和的分布趋近于高斯分布。 这就导致它在许多领域都成为首选的分布假设。
事实上,只有高斯分布才能只用协方差矩阵就完全确定其概率分布。所以在同化算法中默认用协方差矩阵表示不确定性其实已经默认了对象的分布是高斯分布。在此情况下公式 (3) 显然是包含高斯分布假设的,所以一切卡尔曼滤波方法都含有高斯分布假设。至 于线性假设更容易说明:高斯分布的随机变量经过非线性变换后,通常不会保持高斯分 布,非线性模式积分会改变状态变量的分布特征,使其偏离原始的高斯分布。所以如果假设数据一直符合高斯分布的话,那必然还默认了模式是线性的。
线性 - 高斯分布假设是卡尔曼滤波算法的先天不足,且四维变分方法也无法幸免。因为 只要是只用协方差矩阵来代表状态不确定性的算法,毫无疑问都可以说它受限于” 线性高斯分布假设 “。
在此背景下,非线性同化的研发仍然是目前相关学科的前沿。
关于同化方法的细节可以参考相关教材,如:
唐佑民研究员团队:集合滤波数据同化方法及其应用
内有学术观点,可引用:
Tang, Y., Shen, Z., & Gao, Y. (2016). An Introduction to Ensemble-Based Data Assimilation Method in the Earth Sciences. In D. Lee, T. Burg, & C. Volos (Eds.), Nonlinear Systems—Design, Analysis, Estimation and Control (pp. 153–193). IntechOpen. https://doi.org/10.5772/64718
文章改编转载自微信公众号:月亮与枷锁
原文链接:https://mp.weixin.qq.com/s/5Fit6keOODKo176QkL1YSA | 





















