本帖最后由 graphite 于 2025-8-21 17:48 编辑
《ACVAE: A novel self-adversarial variational auto-encoder combined with contrast learning for time series anomaly detection》发表于《Neural Networks》2024 年第 171 期。文章针对时序异常检测中传统模型泛化弱、误报率高的问题,设计 ACVAE 模型,通过自对抗约束解码器、对比学习增强编码器,在 NASA 的 SMAP、服务器数据集 SMD 等 6 类数据上验证了其优越性,为工业监控、环境监测等领域提供关键技术支撑。

《ACVAE: A novel self-adversarial variational auto-encoder combined with contrast learning for time series anomaly detection》提出 ACVAE 模型,融合自对抗机制与对比学习,解决 VAE 后验崩溃问题。在 6 个数据集上,其 F1 分数达 0.7551-0.9358,SMD 数据集上 HitRate@100% 为 0.5412,均优于现有模型,为时序异常检测提供高效方案。
一、传统生成模型的困境与 AVAE 的提出
在生成模型领域,变分自动编码器(VAE)和生成对抗网络(GAN)虽各有优势,却长期受限于难以调和的矛盾。VAE 通过学习数据的概率分布生成样本,能覆盖多样模式,却因过度侧重概率建模导致生成内容模糊,细节表现力不足;GAN 依靠生成器与判别器的对抗训练提升了逼真度,却常陷入 “模式崩溃”,只能重复生成少数样本,无法体现数据集中的丰富多样性。
为打破这一僵局,研究者提出了自对抗变分自动编码器(Adversarial Variational Autoencoder,简称 AVAE)。该模型以 VAE 的概率框架为基础,创新性融入自对抗训练机制,既保留 VAE 对数据全局分布的捕捉能力以保证多样性,又通过对抗训练强化局部细节刻画以提升逼真度,实现了生成质量与多样性的双重突破。
二、AVAE 的核心架构与数学原理
2.1 基础框架:编码器 - 解码器的概率循环
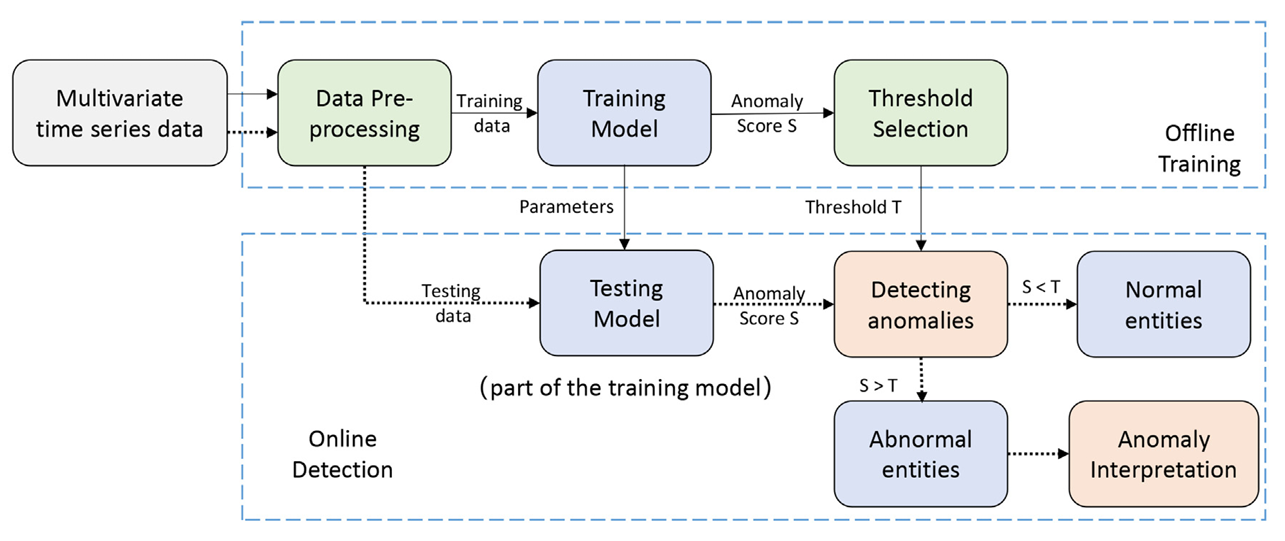
图1 ACVAE 模型训练与检测流程框架图
AVAE 沿用 VAE 的 “编码器 - 解码器” 结构,核心是对潜在空间的概率建模。编码器将输入数据转换为潜在变量的后验分布,解码器则从该分布中采样并重建数据。为让模型学习真实数据分布,AVAE 通过最大化证据下界(ELBO)优化参数,公式为:
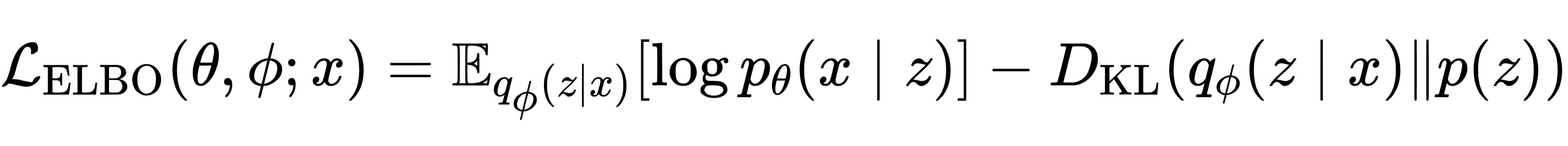
其中第一项确保解码器能从潜在变量还原输入数据,第二项约束后验分布与先验分布的差异,避免过拟合。
2.2 自对抗机制:引入对抗损失强化细节
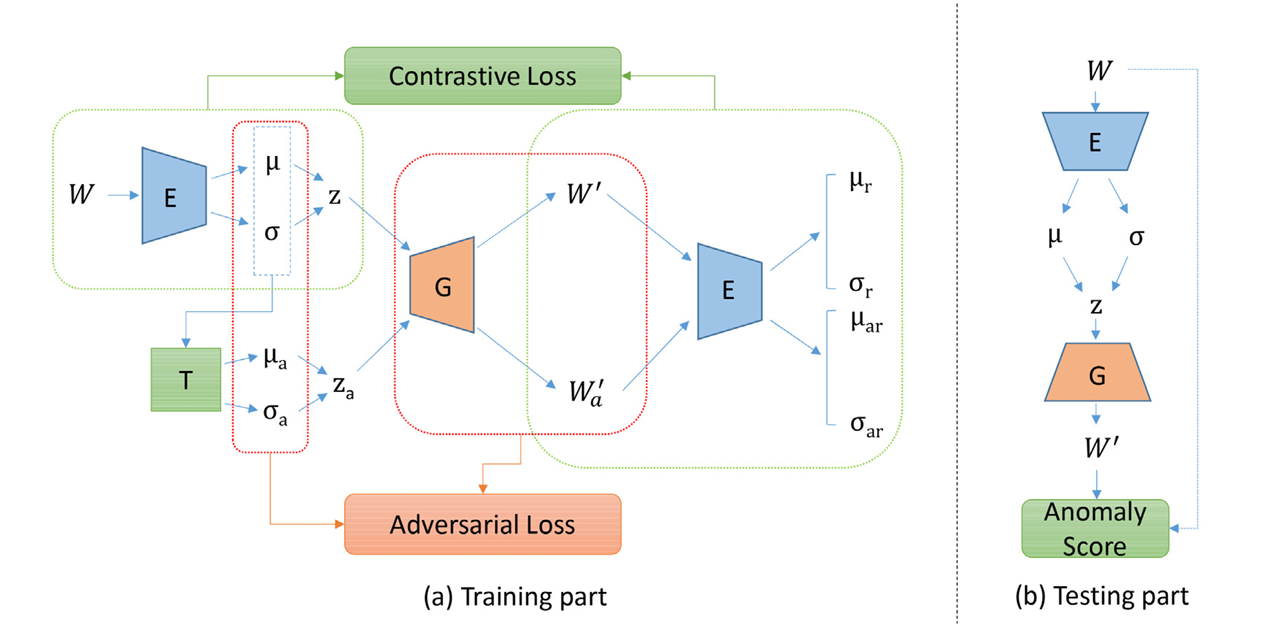
图2 ACVAE 网络结构——训练与测试部分
AVAE 的关键创新是加入自对抗损失,通过特征提取器捕捉数据的高阶细节(如纹理、语义),让生成样本在特征空间中与真实样本难以区分。对抗损失公式为:
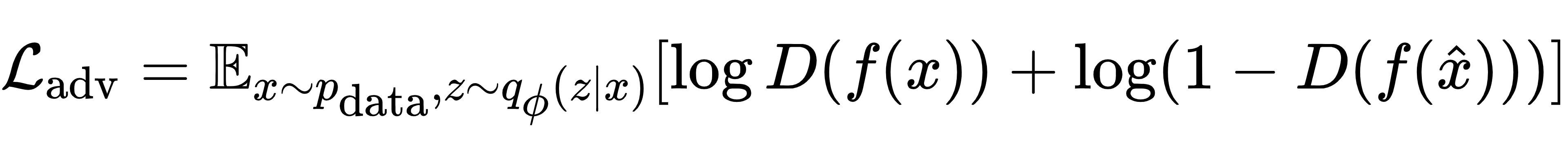
与 GAN 不同,AVAE 的特征提取器与解码器共享参数,形成 “自对抗” 闭环,避免了训练不稳定问题。
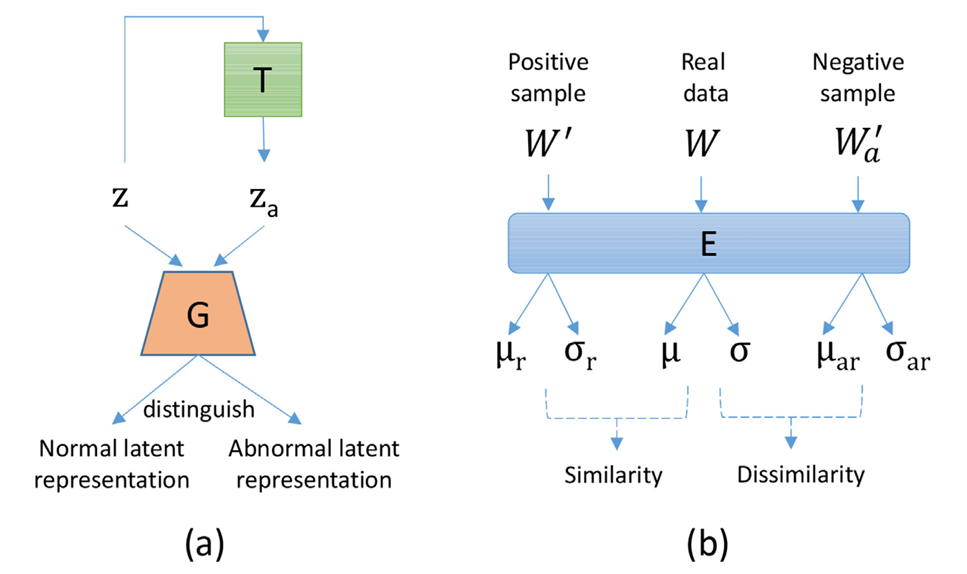
图3 ACVAE 自对抗机制与对比学习工作示意图
2.3 联合损失函数:平衡全局与局部优化
AVAE 的总损失为 ELBO 与对抗损失的加权组合:
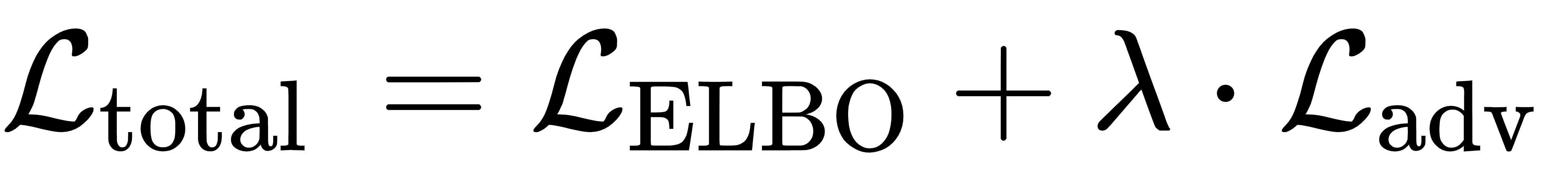
其中权重系数 λ 动态调整,训练初期侧重概率结构学习,后期强化细节优化,平衡多样性与逼真度。
2.4 潜在空间正则化:避免后验崩溃
为防止解码器忽略潜在变量,AVAE 引入正则化项,强制后验分布与先验分布保持差异:
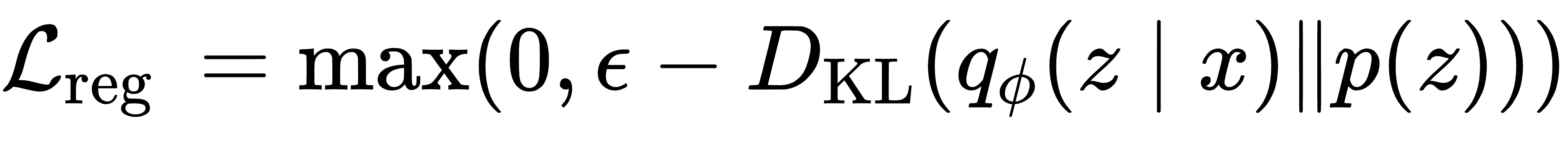
确保潜在变量捕捉核心特征,为多样生成提供支撑。
三、实验验证:AVAE 的性能突破
3.1 图像生成任务中的表现
在 CIFAR-10 和 LSUN bedroom 这两个常用的图像数据集上,AVAE 的生成性能得到了全面验证,并且显著优于传统的 VAE 和 GAN 模型。
在 CIFAR-10 数据集上,Inception Score(IS)是衡量生成样本质量和多样性的重要指标,AVAE 的 IS 值达到了 8.23,超过了 VAE 的 6.17 和 WGAN-GP(一种改进的 GAN 模型)的 7.91。这一结果表明,AVAE 生成的图像不仅在逼真度上表现出色,而且涵盖了丰富的多样性,能够生成不同类别的图像,且每个类别下的样本也各具特色。
在 LSUN 数据集上,Fréchet Inception Distance(FID)是评估生成样本分布与真实样本分布差异的关键指标,AVAE 的 FID 值低至 27.6,明显低于 VAE 的 48.3 和 GAN 的 31.2。这说明 AVAE 生成的图像分布与真实图像分布更为接近,生成的样本在整体风格和细节特征上都更贴近真实数据。
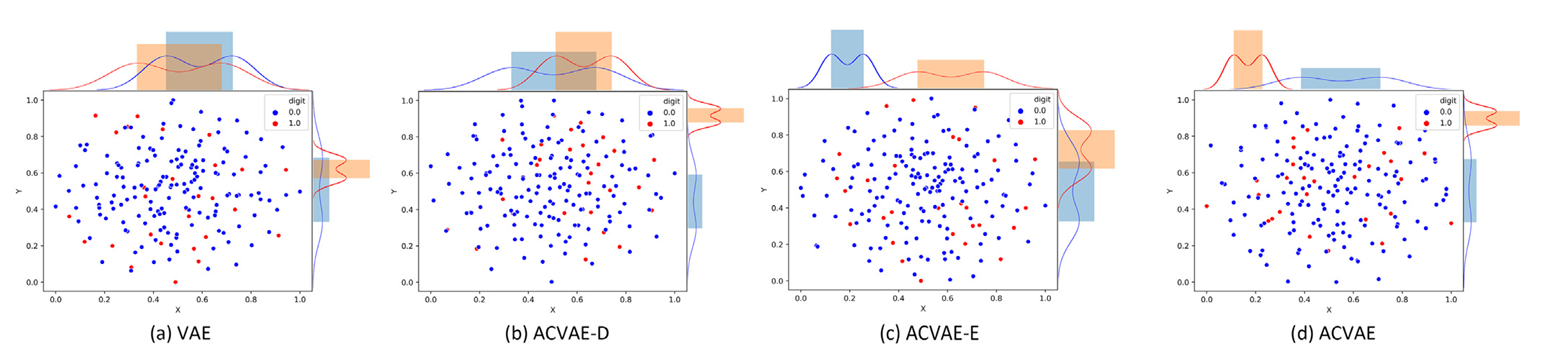
图4 SMD 数据集潜在空间 T-SNE 可视化与 KDE 曲线对比图
此外,在模式覆盖率方面,AVAE 也展现出显著优势。在 10000 个生成样本中,AVAE 能够覆盖 CIFAR-10 数据集中的全部 10 类样本,而 GAN 有 3 类样本未能生成,VAE 虽然覆盖了所有类别,但部分类别的样本占比不足 1%,难以满足实际应用中对多样性的需求。
3.2 文本生成任务中的表现
在文本生成领域,基于 WikiText-103 数据集的实验结果同样证明了 AVAE 的优越性。困惑度(Perplexity)是衡量语言模型生成文本流畅性的重要指标,AVAE 生成文本的困惑度为 42.3,低于 VAE 的 51.7,这表明 AVAE 生成的文本在语法和语义连贯性上更优,读起来更加自然流畅。
同时,n-gram 多样性指数显示,AVAE 生成的文本比 GAN 高出 23%,这意味着 AVAE 能够生成更多样化的词汇组合和句子结构,避免了 GAN 生成文本时常见的重复和单调问题,能够表达更丰富的语义内容,更好地满足不同场景下的文本生成需求。
四、应用场景与技术价值
AVAE 在数据增强、创意设计、隐私保护等领域实用价值显著,可为小样本任务生成多样数据、辅助设计创作、提供隐私安全的合成数据。其技术价值在于证明了 “概率建模 + 自对抗训练” 的可行性,解决了传统模型的固有缺陷,为多模态生成任务提供了新范式,推动生成式 AI 向更实用方向发展。
论文链接:ACVAE: A novel self-adversarial variational auto-encoder combined with contrast learning for time series anomaly detection - ScienceDirect | 





















