本帖最后由 Jack小新 于 2025-8-27 14:58 编辑
《HyperVAE: Variational Hyper-Encoding Network》发表于 2020 年《4th Workshop on Meta-Learning at NeurIPS》,提出了 HyperVAE 框架,以双层 VAE 架构生成任务 VAE 参数,解决传统模型任务适配难题。在 MNIST、Omniglot 等数据集上,其密度估计 NLL 低至 88.2(MNIST)、105.5(Omniglot),异常检测 AUC 达 95.3(MNIST)、98.7(Omniglot),新类别发现中与目标样本余弦距离仅 0.12,参数规模与普通 VAE 相当(890 千),性能优于 VAE、MetaVAE,为多任务生成提供高效方案。

在人工智能领域,生成模型一直是探索数据规律、创造新内容的核心工具。从能生成逼真图像的 GAN,到擅长建模概率分布的 VAE,这些模型虽各有突破,却始终面临一个局限 —— 它们只能针对单一任务进行训练,面对新任务时往往需要重新调整或训练,难以快速适配不同场景。
而今天要介绍的HyperVAE(Variational Hyper-Encoding Network),则跳出了这一框架。它不是直接生成数据,而是学会 “生成能生成数据的模型”,就像让 AI 掌握了 “设计工具的能力”,为多任务适配、未知模式探索开辟了全新路径。这一创新框架由澳大利亚迪肯大学 A2I2 实验室与日本北陆先端科学技术大学院大学合作提出,发表于2020 年 NeurIPS 元学习研讨会,其核心思路和实验成果,正在重新定义生成模型的应用边界。
一、传统生成模型的 “任务枷锁”:为何适配新场景这么难?
在 HyperVAE 出现之前,主流的生成模型(如 VAE、GAN)和元学习模型(如 MetaVAE),都存在难以克服的 “任务绑定” 问题:
普通 VAE/GAN:训练时只能针对单一数据集(如 MNIST 手写数字)建模,若要处理新任务(如 Fashion MNIST 服装图像),必须重新训练整个模型。不仅耗时,还容易因数据分布差异导致性能骤降。
元学习模型(如 MetaVAE):虽尝试通过 “共享编码器 + 任务专属解码器” 适配多任务,但解码器仍需为每个任务单独训练。面对数据量少的新任务时,解码器容易过拟合,且无法处理完全未见过的任务类型。
超网络(Hyper-networks):虽能生成目标网络的参数,但为了降低计算量,通常只生成权重的缩放因子和偏置,丢失了大量任务关键信息,导致生成的模型泛化能力弱。
这些问题的核心在于:传统模型将 “数据生成” 和 “模型参数” 视为两个独立部分,未能将 “模型本身” 作为一种可学习、可生成的 “数据” 来处理。而 HyperVAE 的突破,正是把 “模型参数” 纳入生成框架,用一个 “超层 VAE” 来生成 “任务层 VAE”,实现了 “模型的模型化”。
二、HyperVAE 的核心逻辑:用 VAE 生成 VAE,构建 “模型的生成器”
HyperVAE 的本质是一个 “双层 VAE 架构”—— 底层是用于处理具体任务的 “任务 VAE”(负责生成数据、建模任务分布),顶层是用于生成 “任务 VAE 参数” 的 “超 VAE”(负责学习任务间的元知识,生成适配不同任务的模型参数)。其核心设计可拆解为三个关键部分:
2.1 把 “模型参数” 当作 “数据” 来生成
在 HyperVAE 中,每个任务(如 MNIST 的 “数字 0” 分类、Fashion MNIST 的 “T 恤” 分类)对应的 VAE 模型参数 θ,不再是固定训练的结果,而是由超 VAE 生成的 “变量”。超 VAE 会学习一个低维潜在空间 u,通过解码器将 u 映射为任务 VAE 的完整参数 θ,包括权重矩阵、偏置向量、卷积核等,且生成的是完整参数,而非传统超网络的 “部分参数”,确保任务信息不丢失。
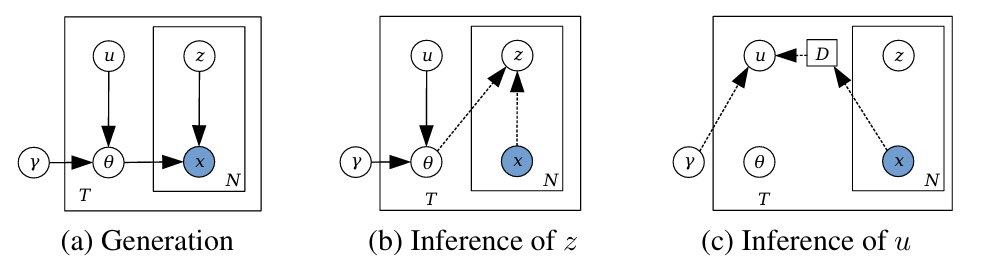
图1 HyperVAE图形化模型架构图的生成、z推理、u推理流程
这一过程的数学表达可通过联合分布体现:超 VAE 通过潜在变量 u,将 “模型参数 θ” 和 “任务数据 D” 的联合分布分解为:
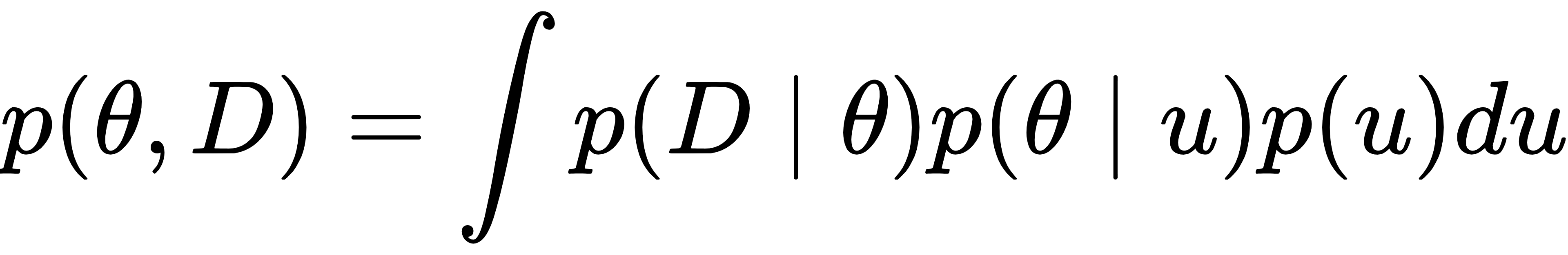
其中,p (u) 是潜在变量 u 的先验分布(标准高斯分布),p (θ|u) 是超 VAE 的解码器,负责从 u 生成任务 VAE 的参数 θ,p (D|θ) 则是任务 VAE 对数据 D 的建模能力。
2.2 训练目标:最小化 “数据 + 模型” 的总描述长度
为了让超 VAE 同时学好 “生成模型” 和 “建模数据”,研究团队采用了最小描述长度(MDL)原则—— 模型的训练目标是让 “传输数据 D” 和 “传输模型参数 θ” 的总代码长度最短。这一目标最终转化为以下损失函数:
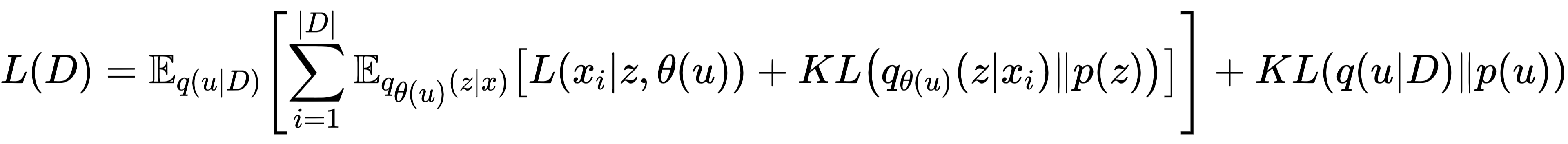
简单来说,这个损失包含两部分:
数据描述长度:任务 VAE 对数据的重建损失(确保生成的模型能精准建模任务数据);
模型描述长度:超 VAE 的 KL 散度损失(确保生成的模型参数 θ 符合任务间的元规律,避免过拟合)。
通过最小化这个总长度,HyperVAE 能同时掌握 “生成高质量任务模型” 和 “适配不同数据分布” 的能力。
2.3 高效参数生成:用矩阵网络降低计算成本
任务 VAE 的参数(如权重矩阵)通常维度极高(例如一个 400×400 的权重矩阵含 16 万个参数),若直接用全连接层生成,计算量会呈指数级增长。HyperVAE 创新地采用矩阵网络解码器,通过 “U・H・V + B” 的形式生成权重矩阵(U、V 是固定参数,H 是超 VAE 的潜在输出,B 是偏置)。
以生成 400×400 的权重矩阵为例:传统全连接层需要 6400 万个参数,而矩阵网络仅需 17.6 万个参数,计算量降低 3 个数量级,既保证了参数完整性,又解决了超网络的效率问题。
三、实验验证:三大任务证明 HyperVAE 的优越性
研究团队在 MNIST(手写数字)、Omniglot(手写字符)、Fashion MNIST(时尚单品)三大数据集上,从密度估计、异常检测、新类别发现三个核心场景验证了 HyperVAE 的性能,结果全面优于传统 VAE 和 MetaVAE。
3.1 密度估计:更精准地建模数据分布
密度估计的核心是衡量模型对数据 “真实分布” 的拟合程度,通常用负对数似然(NLL) 衡量(值越小越好)。
表1 HyperVAE与VAE、MetaVAE在三大数据集上的密度估计性能对比表
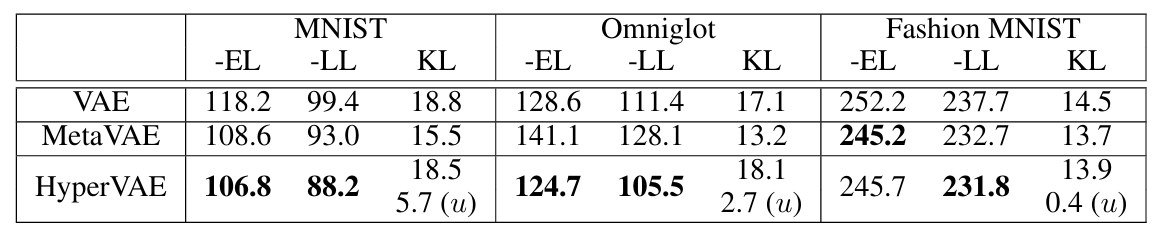
表2 HyperVAE与VAE、MetaVAE的模型参数规模对比表

实验结果显示:
在 MNIST 数据集上,HyperVAE 的 NLL 为 88.2,优于 VAE 的 99.4 和 MetaVAE 的 93.0;
在 Omniglot 数据集上,HyperVAE 的 NLL 为 105.5,显著优于 VAE 的 111.4 和 MetaVAE 的 128.1;
即使在数据分布更复杂的 Fashion MNIST 上,HyperVAE 的表现也与最优模型持平,且参数规模仅与普通 VAE 相当(如表 2 所示,总参数均为 890 千,远低于 MetaVAE 随任务增长的参数量)。
这说明 HyperVAE 生成的任务 VAE,能更精准地捕捉数据分布,且不会因任务增加导致模型臃肿。
3.2 异常检测:更低的漏检率,更鲁棒的识别
异常检测的关键是区分 “正常数据” 和 “异常数据”,实验中用AUC(ROC 曲线下面积)、误报率(FPR)、漏报率(FNR) 衡量性能。结果显示:
表3 HyperVAE与VAE、MetaVAE在三大数据集上的异常检测性能对比表
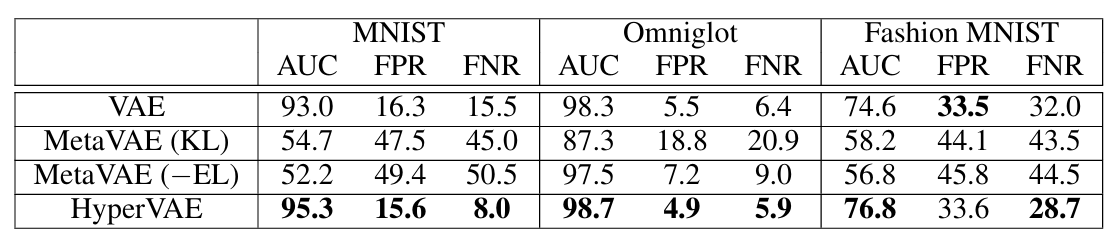
在 MNIST 上,HyperVAE 的 AUC 达 95.3,漏报率仅 8.0%,远低于 VAE 的 15.5%;
在 Omniglot 上,HyperVAE 的 AUC 达 98.7,误报率 4.9%、漏报率 5.9%,均优于 VAE 和 MetaVAE;
即使在 Fashion MNIST 这种类别差异小的数据集上,HyperVAE 的 AUC 仍达 76.8,漏报率 28.7%,优于 VAE 的 32.0%。
HyperVAE 的优势在于:它通过超层学习了任务间的 “正常模式边界”,面对异常数据时,生成的任务 VAE 能更清晰地识别 “不符合元规律” 的样本,从而降低漏检率。
3.3 新类别发现:用贝叶斯优化探索未知模式
新类别发现是 HyperVAE 最具创新性的应用 —— 它能结合贝叶斯优化(BO),在未见过的任务类别中,搜索出符合目标的 “新数据”。实验中,研究团队在 MNIST 上 “隐藏一个数字类别”(如数字 “0”),仅用其他 9 类训练 HyperVAE,然后通过 BO 在潜在空间 u 和 z 中搜索 “最接近隐藏数字” 的样本。

图2 HyperVAE+BO在MNIST隐藏数字类别发现中的迭代效果对比图
如图 2 ,结果显示:
这意味着 HyperVAE 不仅能适配已知任务,还能通过潜在空间探索,解锁完全未知的 “新模型 - 新数据” 组合,为创新设计(如新材料、新分子结构)提供了可能。
四、应用前景:从工业检测到科学发现的潜力
HyperVAE 的 “生成模型的能力”,使其在多个领域具有不可替代的价值:
工业异常检测:在设备传感器数据监测中,HyperVAE 可生成适配电机、风机等不同设备的异常检测模型,无需为每个设备单独训练,降低运维成本;
医疗数据建模:针对不同疾病的医学影像(如肺癌 CT、糖尿病眼底图像),HyperVAE 能快速生成专用 VAE 模型,在小样本场景下仍保持高诊断精度;
科学发现:在材料设计、药物分子生成中,HyperVAE+BO 可探索现有数据库外的 “新分子结构”,通过优化潜在空间,找到符合 “高稳定性”“低毒性” 等目标的创新设计。
五、总结:HyperVAE 的意义与未来
HyperVAE 的核心突破,在于将 “模型参数” 纳入生成框架,用 “元学习 + 生成模型” 的思路,解决了传统模型 “任务绑定” 的痛点。它不仅在密度估计、异常检测等经典任务中表现优异,更重要的是提供了一种 “探索未知模式” 的新范式 —— 通过生成 “适配新任务的模型”,让 AI 具备了 “自主扩展能力”。
未来,随着潜在空间设计的优化、多模态数据的适配,HyperVAE 有望在更多场景落地,真正实现 “让 AI 学会创造工具,再用工具创造价值” 的目标。对于开发者和研究者而言,HyperVAE 的思路也提供了新的启发:当数据和任务变得复杂时,或许可以跳出 “直接建模数据” 的惯性,转而思考 “如何建模建模的过程”—— 这可能是突破 AI 泛化能力瓶颈的关键方向之一。
论文链接:https://meta-learn.github.io/2020/papers/71_paper.pdf | 





















