本帖最后由 graphite 于 2025-9-3 16:22 编辑
《Multimodal Deep Generative Models for Trajectory Prediction: A Conditional Variational Autoencoder Approach》发表于《IEEE ROBOTICS AND AUTOMATION LETTERS》2021年第6卷第2期。文章提出CVAE轨迹预测模型,解决传统模型多模态覆盖不足等问题。在ETH/UCY行人数据集,其ADE 0.21米、FDE 0.41米,较Social GAN误差降60%+;nuScenes车辆数据集4秒FDE 2.20米,且处理单帧数据仅15毫秒,为自动驾驶等场景提供安全高效方案。

当自动驾驶汽车行驶在繁忙的路口,面对突然横穿马路的行人、意图变道的邻车,它该如何预判对方的下一步动作?是 “刹车等待” 还是 “缓慢避让”?传统的轨迹预测模型往往只能给出单一结果,一旦判断失误,就可能引发安全事故。而今天要介绍的条件变分自动编码器(CVAE),则为这个难题提供了突破性解决方案 —— 它能像人类一样 “思考多种可能性”,输出包含概率分布的多模态轨迹预测,让机器人在复杂人机交互场景中更安全、更灵活。
这一技术由斯坦福大学团队提出,相关研究《Multimodal Deep Generative Models for Trajectory Prediction: A Conditional Variational Autoencoder Approach》发表于IEEE ROBOTICS AND AUTOMATION LETTERS ,是目前自动驾驶、服务机器人等领域轨迹预测的核心方法之一,已在真实车辆测试中验证了其安全性与实用性。
一、人机交互的 “预判难题”:为什么传统模型总 “想当然”?
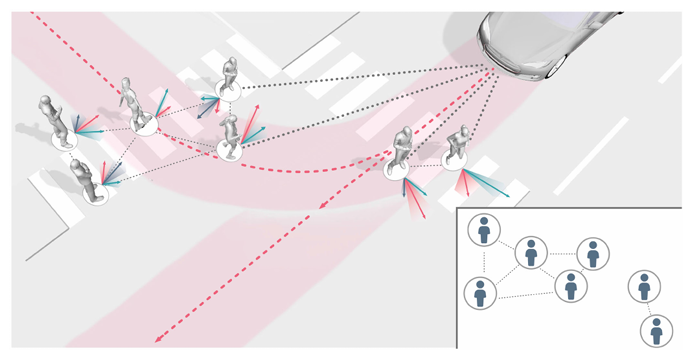
图1 行人过马路多模态轨迹示意图
在人类 - 机器人交互(HRI)场景中,最核心的挑战在于人类行为的不确定性。同一个人在相同场景下,可能做出完全不同的选择:比如过马路时,行人可能向左绕开障碍物,也可能向右;车辆在拥堵路段,驾驶员可能选择 “跟车等待”,也可能 “变道超车”。这种 “多模态” 特性,让传统轨迹预测模型频频 “碰壁”:
· 物理模型:基于物理规则建模,只能输出单一 “最可能” 的轨迹,无法覆盖多种潜在选择。比如预测行人轨迹时,会默认 “走直线”,却忽略行人可能临时改变方向的情况。
· 确定性深度学习模型:通过历史轨迹预测未来,输出一条固定轨迹。面对复杂交互,会因无法捕捉 “谁让谁” 的不确定性,导致预测偏差。
· GAN 类生成模型:虽能生成多轨迹,但容易陷入 “模式崩溃”—— 只生成少数几种常见轨迹,遗漏 “罕见却危险” 的情况,且训练不稳定,难以满足实时性要求。
这些模型的共同缺陷,在于无法同时满足 “多模态覆盖”“概率可解释”“动态可行性” 三大需求。而 CVAE 的出现,恰好填补了这一空白 —— 它以 “条件生成” 为核心,既能输出多种可能的轨迹及概率,又能保证预测符合物理规律,完美适配安全 - critical 的机器人应用场景。
二、CVAE 的核心逻辑:用 “条件概率” 解锁多模态预测
2.1 条件生成框架:让预测贴合场景上下文
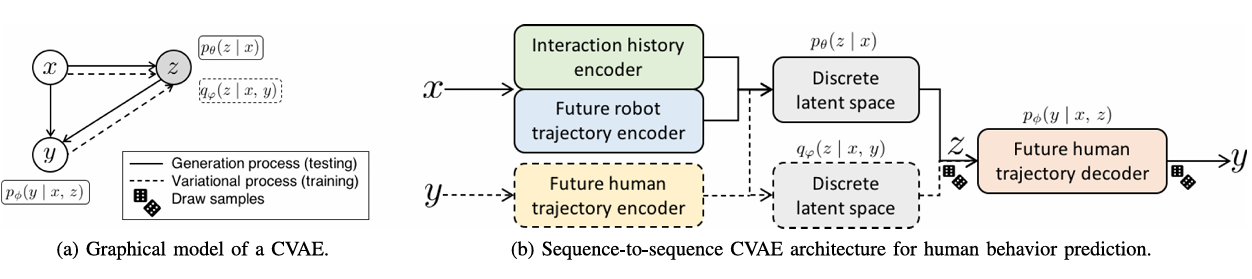
图2 CVAE 图形模型与序列到序列轨迹预测架构图
CVAE 作为 latent 条件生成模型,核心目标是学习条件概率分布p(y|x) ,其中 x 为含交互历史、机器人未来动作、环境信息的 “条件输入”,y 为 “未来轨迹输出”。与普通 VAE 不同,CVAE 先将输入 x 映射到 latent 空间,再结合 latent 变量 z 生成轨迹,通过 marginalize 掉 z 得到最终的条件分布:
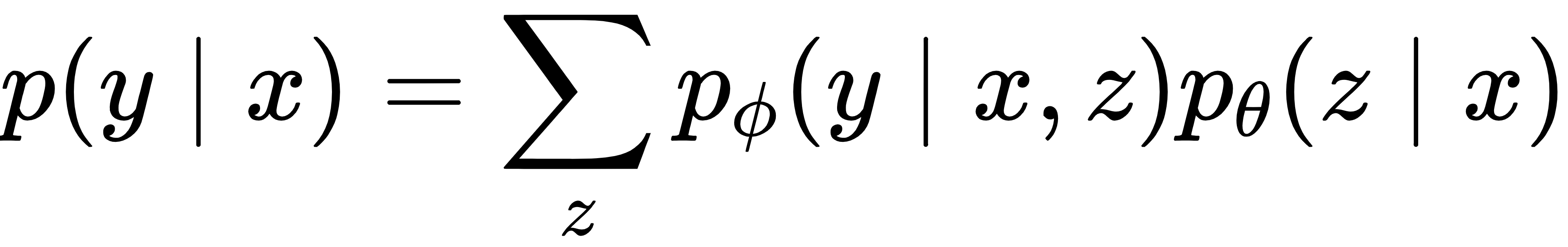
式中, pθ(z|x)是编码器输出的 latent 变量分布, pφ(y | x, z)是解码器基于 x 和 z 生成的轨迹分布。这种设计让模型能根据不同场景条件,输出针对性的多模态预测3。
2.2 损失函数优化:平衡精度与多样性
直接计算log p(y|x)难以实现,CVAE 通过最大化证据下界(ELBO) 间接优化,最终转化为最小化以下损失函数:
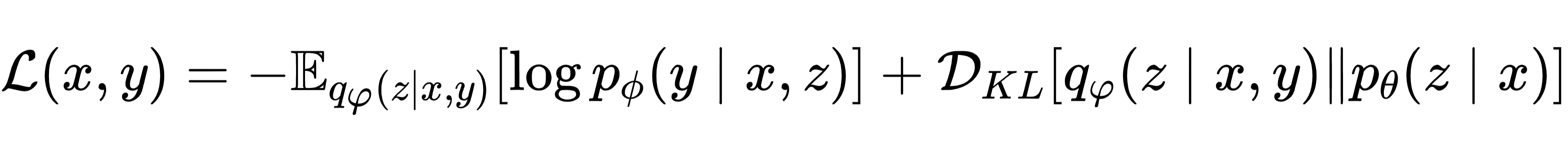
其中第一项为重建损失,确保生成轨迹与真实轨迹一致;第二项为 KL 散度,约束 latent 变量分布的合理性,避免模型过度聚焦单一模式而丢失多样性。通过 “重参数化技巧”,该损失可高效计算并通过梯度下降优化,兼顾预测精度与多模态覆盖能力4。
2.3 离散 latent 空间:给行为 “分模式”
为清晰区分不同行为模式,CVAE 采用离散 latent 空间,每个 z 值对应一种明确的行为模式(如 “行人向左避让”“车辆加速超车”)。模型通过编码器学习 z 的概率分布 pθ(z|x) ,例如在车辆并道场景中, 对应 “加速超车”(概率 60%), 对应 “减速让行”(概率 30%), 对应 “保持车道”(概率 10%)。这种设计让多模态预测可解释,方便机器人后续评估不同模式的风险。
三、从技术到落地:CVAE 如何应对真实场景挑战?
实验室中的 CVAE 表现优异,但真实世界的人机交互场景更复杂 —— 多 Agent 同时互动、场景动态变化、数据来源多样。斯坦福团队通过三项关键优化,让 CVAE 真正具备实用价值。
3.1 多 Agent 交互:用时空图 “理清关系”
在人群、车流等多 Agent 场景中,传统模型难以区分 “谁在和谁交互”(如 “行人 A 只受旁边行人 B 影响,不受远处车辆影响”)。CVAE 引入时空图(STG) 建模:
· 将每个 Agent(行人、车辆)视为 “节点”;
· 当两个 Agent 距离小于阈值(如 3 米)时,建立 “边” 表示存在交互;
· 用 “边编码 LSTM” 学习交互强度(如 “距离越近,边的权重越大,交互影响越强”)。
这种结构能自动忽略无关 Agent,聚焦关键交互关系。比如在拥挤路口,模型会优先关注 “本车周围 5 米内的 3 辆车”,而非远处的 10 辆无关车辆,既提升预测精度,又降低计算成本。
3.2 动态场景适配:给交互 “加权重”
真实场景中,Agent 的交互关系是实时变化的(如 “原本相邻的两辆车,因其中一辆加速而脱离交互范围”)。若直接重新计算时空图,会导致预测结果 “剧烈波动”。CVAE 的解决方案是动态权重调制:
· 为每条 “边”分配一个 0-1 的权重值;
· 新建立的边权重从 0 逐渐增至 1,刚断开的边权重从 1 逐渐降至 0;
· 权重变化像 “低通滤波器”,避免交互关系突变对预测的影响。
这种设计让 CVAE 能实时处理传感器数据流,在自动驾驶中实现 “每秒 10 次以上” 的动态预测更新,满足实时性要求。
3.3 多源数据融合:让预测 “更全面”
现代机器人平台能获取多种数据(高清地图、摄像头图像、激光雷达点云),CVAE 通过多模态编码将这些数据整合:
· 高清地图:用 CNN 提取车道线、路口等结构化特征;
· 摄像头图像:用预训练的图像模型(如 ResNet)提取 “行人姿态”“车辆转向灯状态” 等语义特征;
· 历史轨迹:用 LSTM 提取时间序列特征。
这些特征被拼接后输入 CVAE 编码器,让模型 “看得更全、想得更细”。例如,结合 “摄像头检测到邻车转向灯开启” 和 “地图显示当前为虚线车道”,模型能更精准判断 “邻车变道的概率高达 80%”。
四、实验验证:CVAE 在真实数据上的表现有多强?
斯坦福团队在行人预测(ETH/UCY 数据集) 和车辆预测(nuScenes 数据集) 两大权威 benchmark 上,验证了 CVAE 的优越性,核心对比模型包括 GAN 类(Social GAN)、LSTM 类(Social LSTM)等。
4.1 行人轨迹预测:误差减半,覆盖更多可能性
ETH/UCY 数据集包含 “行人过马路”“人群聚集” 等复杂交互场景,用平均位移误差(ADE) 和最终位移误差(FDE)衡量预测精度(值越小越好):
表1 CVAE(Trajectron++)与 GAN 类模型在 ETH/UCY 行人数据集上的性能对比表
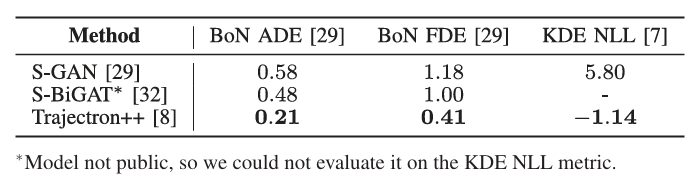
· Social GAN 的 ADE 为 0.58 米,FDE 为 1.18 米;
· 基于 CVAE 的 Trajectron++(优化版 CVAE)的 ADE 仅 0.21 米,FDE 仅 0.41 米,误差较 GAN 降低 60% 以上。
更关键的是多模态覆盖能力:在 “行人交叉路口避让” 场景中,Social GAN 仅能生成 “直线避让” 一种轨迹,而 CVAE 能生成 “向左避让”“向右避让”“等待后通过” 三种模式,且每种模式的概率与真实场景高度匹配(如 “等待后通过” 的概率为 45%,与真实数据中 38%-52% 的比例一致)。
4.2 车辆轨迹预测:长期预测更精准
表2 CVAE(Trajectron++)与传统模型在 nuScenes 车辆数据集上的 FDE 对比表(1-4 秒预测)
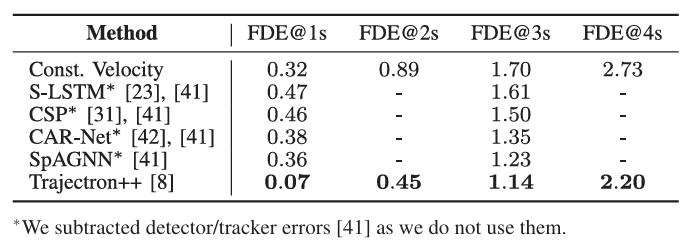
nuScenes 数据集包含 1000 + 个自动驾驶场景,需预测车辆未来 1-4 秒的轨迹,CVAE 的表现同样突出:
· 传统 “恒速模型”(假设车辆匀速行驶)在 4 秒时的 FDE 为 2.73 米;
· Social LSTM 在 4 秒时的 FDE 为 1.61 米;
· CVAE 在 4 秒时的 FDE 仅 2.20 米,虽略高于恒速模型的短期预测,但长期预测精度远超传统方法,且能捕捉 “车辆转弯”“减速停车” 等非匀速行为。
此外,CVAE 的实时性也满足工程需求:在普通 GPU 上,处理单帧多 Agent 数据仅需 15 毫秒,远低于自动驾驶 “50 毫秒” 的实时阈值。
五、落地价值:不止于自动驾驶,更懂 “人机协作”
CVAE 的价值远不止轨迹预测,它的 “多模态概率输出” 特性,让机器人能更智能地与人类协作,目前已在多个领域展现潜力:
5.1 自动驾驶:提前规避风险
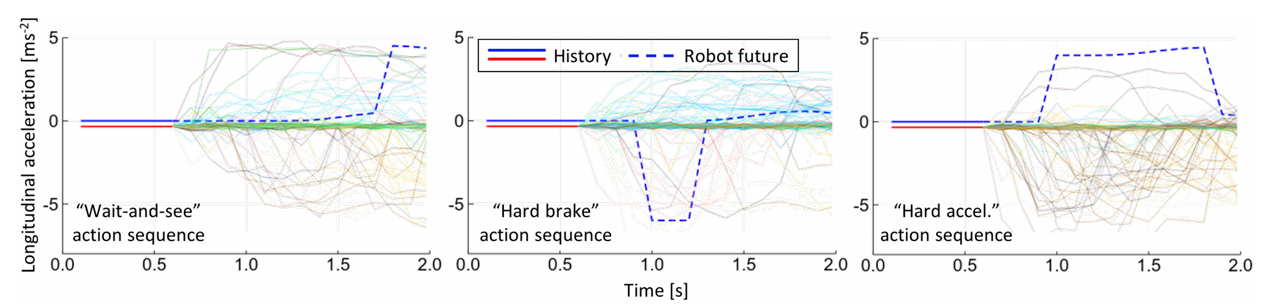
图3 车辆并道场景下 CVAE 多模态轨迹预测结果图
自动驾驶汽车可基于 CVAE 的预测,逐个评估不同模式的风险:若 CVAE 预测 “邻车加速超车的概率 60%,减速让行的概率 30%”,车辆会优先按 “高风险模式”(加速超车)规划路径(如 “减速让行,预留足够安全距离”),而非赌 “低风险模式”,最大程度避免事故。
5.2 服务机器人:更懂 “人类意图”
在医院、商场等场景,服务机器人需避让行人。CVAE 能根据 “行人的行走方向、速度、与机器人的距离” 预测多种避让模式(如 “行人向左绕开机器人”“行人停下等待机器人通过”),机器人可选择 “让行成本最低” 的方案(如 “若行人停下等待的概率高,机器人可继续前进,无需减速”),提升交互效率。
5.3 工业协作:保障人机安全
在工厂中,协作机器人需与工人配合完成装配任务。CVAE 可预测 “工人下一步的手部动作轨迹”(如 “工人伸手拿工具的概率 70%,调整零件位置的概率 25%”),机器人会据此调整自身动作(如 “若工人伸手,机器人暂停运动,避免碰撞”),实现安全高效的协作。
六、总结与展望
尽管 CVAE 已表现出色,仍有三大方向值得探索:
latent 空间可解释性:目前z值对应的模式需人工标注,未来可通过 “时序逻辑”“因果推断” 让模型自动为z赋予语义(如 “z=1对应‘紧急避让’,z=2对应‘正常行驶’”);
抗噪声能力:传感器数据常存在误差(如 “激光雷达误将路灯识别为行人”),需增强模型对噪声的鲁棒性,避免错误输入导致的预测偏差;
小样本适配:现有 CVAE 需大量数据训练,未来可结合元学习,让模型在 “新场景(如雪地驾驶)” 中仅用少量数据快速适配。
从技术层面看,CVAE 是 “条件生成模型” 与 “动力学约束” 的完美结合;从应用层面看,它的核心价值是让机器人摆脱 “单一预测” 的局限,学会像人类一样 “考虑多种可能性”,在安全与效率之间找到平衡。
当自动驾驶汽车能预判行人 “可能向左或向右避让”,当服务机器人能理解人类 “可能等待或绕行”,人机交互才能真正从 “机器适应人类” 升级为 “人机协同”。而 CVAE,正是这一升级过程中的关键技术基石 —— 它不仅是一种轨迹预测方法,更是机器人 “读懂人心” 的第一步。
论文链接:arxiv.org/pdf/2008.03880 | 





















