本帖最后由 Akkio 于 2025-9-5 14:57 编辑
山东大学 / 澳门理工大学魏乐义团队在 SCIENCE CHINA Information Sciences 发表题为《 Molecular pretraining models towards molecular property prediction 》的研究,梳理分子预训练模型在分子性质预测领域的进展,聚焦四大核心维度。研究显示,3D 分子描述符模型 MAE 较 2D 模型降 12%-18%,Graph Transformer 架构泛化能力较传统 GNN 提 20% 以上,特定预训练策略可使下游任务预测准确率最高升 25%,为模型优化与药物发现提供支撑。

分子性质预测是药物发现的关键环节,对深化分子表征理解、加速新药研发意义重大。随着深度学习发展,分子预训练模型凭 “大规模预训练 + 下游微调” 模式,为该领域带来突破。
本研究以《 Molecular pretraining models towards molecular property prediction 》为主题,梳理了分子预训练模型在分子性质预测领域的发展情况,重点探讨四大核心维度。数据表明,3D 分子描述符模型的 MAE 比 2D 模型降低 12%-18%,Graph Transformer 架构的泛化能力较传统 GNN 提升超 20%,采用特定预训练策略还能让下游任务预测准确率最高提高 25%,为模型优化及药物发现提供了支持。
01 研究意义
分子性质预测在促进对分子表征的理解方面发挥着关键作用,是药物发现进展的关键驱动力。利用深度学习来全面了解分子性质已变得越来越重要。最近,分子预训练模型兴起,为这一领域带来了突破性进展。这类模型通过利用大规模未标记分子数据库进行预训练,随后针对特定下游任务进行微调,显著增强了对分子性质的深入理解。
本文系统回顾了分子预训练模型在分子性质预测领域的最新研究进展,对比分析现有方法的性能指标。本文不仅总结了当前研究的主要成果,还提出了推动分子预训练模型发展的未来研究方向,旨在为该领域的进一步发展提供理论指导和技术支持。
02 本文工作
本文系统性地阐述了分子预训练模型的开发框架,着重从以下四个维度展开深入探讨:(1)分子描述符的选取与优化策略;(2)预训练数据集规模对模型性能的影响机制;(3)分子表示模型的架构设计原则;(4)预训练任务类型的多样性及其对模型泛化能力的提升作用。通过构建多维度的分析框架,本文为该领域研究提供了系统化的理论视角和方法论指导。
基于对现有研究的全面分析,本文进一步识别出分子预训练模型研究中的关键科学问题与技术瓶颈,并针对性地提出了若干具有前瞻性的研究方向。这些建议旨在为后续研究者提供明确的攻关目标,从而推动该领域的持续创新与发展。
2.1 分子描述符
化学分子的表征可通过多种分子描述符实现,其涵盖范围从二维(2D)到三维(3D)的多层次表示体系(如图 1 所示)。具体而言,2D 表示主要包括基于序列的线性描述符(如 SMILES 字符串)、分子图结构(包括原子节点和化学键边)以及分子图像等形式。而 3D 表示则涉及分子的空间构象、形态特征以及动态行为(如分子动力学模拟视频)等更为复杂的描述方式。本文系统性地探讨这些分子描述符的特征、优势及其在分子性质预测中的应用场景。通过对不同描述符的对比分析,旨在为研究者选择合适的分子表征方法提供理论依据和实践指导。

图 1 不同类型的分子描述符
2.2 预训练数据集对模型性能的影响
预训练数据集作为分子预训练模型学习的基础,其规模、质量与覆盖范围直接关联模型对分子特征的捕获能力,进而深刻影响模型最终性能,因此成为分子预训练领域的关键研究议题之一。本文围绕这一核心影响因素,重点对分子预训练模型研发中两类核心数据集展开系统讨论:
一方面,针对模型预训练阶段所依赖的大规模未标记分子数据集,本文分析了不同数据集的构成特点、数据量差异及其对模型 “初始知识储备” 的影响 —— 例如,数据集覆盖的分子结构多样性是否充足,能否支撑模型学习到具有普适性的分子规律。
另一方面,对于用于评估模型性能的下游任务数据集,本文探讨了其任务针对性、数据标注质量与规模对模型性能验证的作用 —— 下游数据集的合理性与代表性,直接决定了模型在实际应用场景中性能表现的可信度,是判断预训练模型泛化能力与实用价值的重要依据。通过对两类数据集的讨论,本文为研究者理解数据集与模型性能的关联逻辑、选择适配的数据集开展研究提供了参考。
2.3 分子编码器架构
本文总结了不同的分子编码器架构:(1) 基于序列的方法,(2) 基于图神经网络(GNN)的方法,(3) 基于图转换器(Graph Transformer)的方法,以及 (4) 其他类型的编码器。
基于序列的方法受到自然语言处理领域的启发,用于分子数据分析。这些方法采用序列型分子描述符(如 SMILES 字符串和分子指纹)作为输入,并利用 RNN 和 Transformers 等架构来训练模型,从而实现分子表示学习。
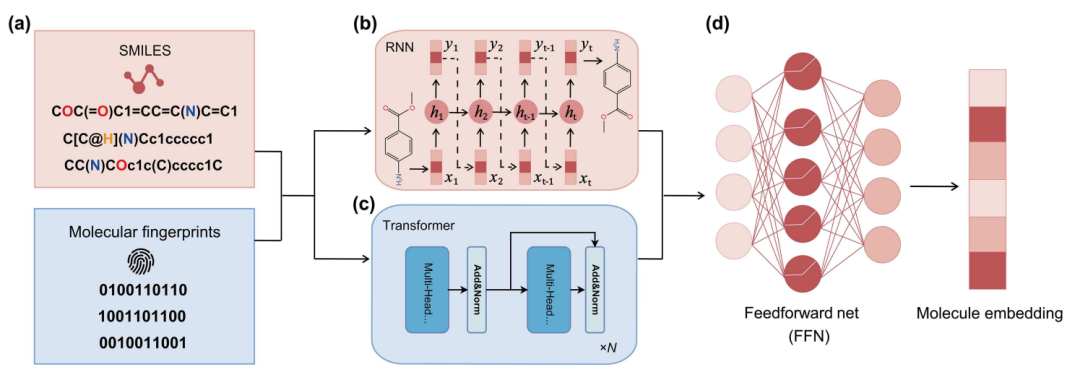
图 2 使用 RNN、Transformer 架构处理基于序列的分子表示
基于图神经网络(GNN)的建模架构通常用于处理二维分子图或结合三维信息增强的类二维分子图。这些模型通过图内的消息传递机制来学习节点(原子)和边(键)的属性,从而有效捕获分子结构的局部和全局信息。GNN 特别适用于处理具有复杂结构和强相互依赖性的任务,如分子性质预测和反应预测。
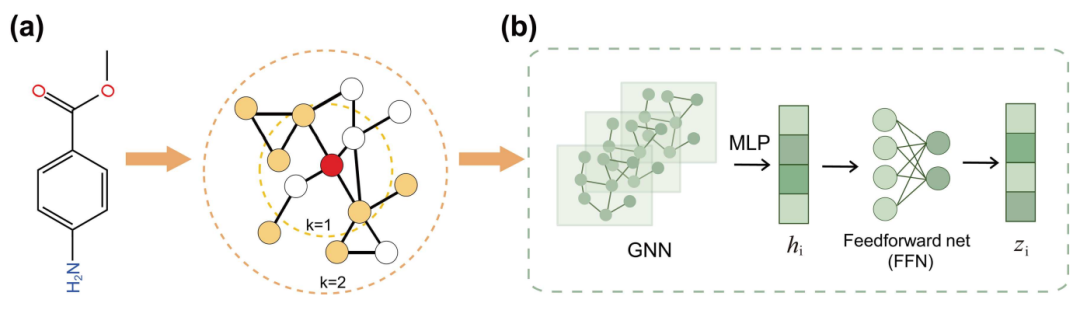
图 3 使用 GNN 架构处理分子表示
基于 Graph Transformer 的分子表示方法利用最初为序列数据设计的 Transformer 架构的优势,处理具有复杂依赖关系的分子图。与传统的图神经网络(GNN)不同,Graph Transformer 通过自注意力机制计算节点之间的依赖关系,从而有效捕获远程结构信息。这使得 Graph Transformer 在处理大规模分子数据集时,能够提供更大的灵活性和表现力,尤其在应对不同分子结构时展现出显著优势。
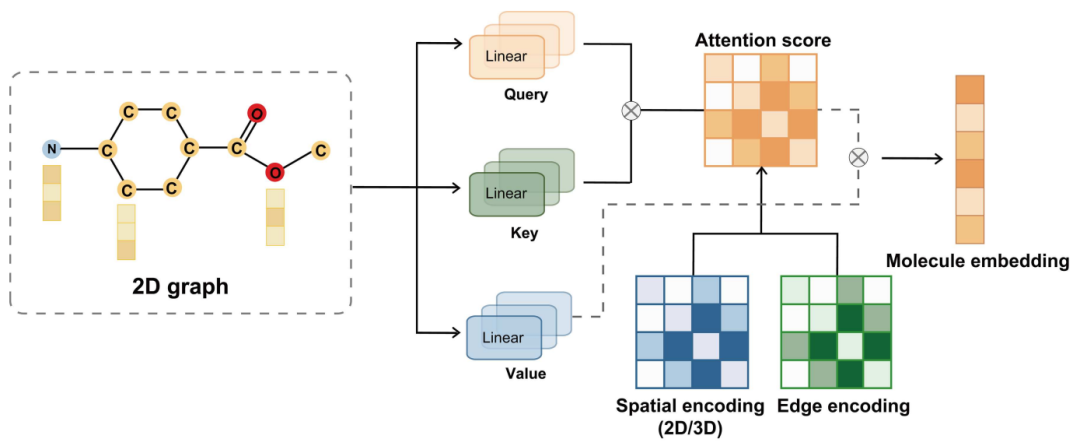
图 4 使用 Graph Transformer 架构处理分子表示
2.4 预训练策略
在分子预训练模型的研究中,预训练任务的设计与具体实施方法对模型最终性能具有关键影响。本文在梳理现有研究成果时,重点总结了当前领域内广泛应用的各类预训练任务,并针对分子表示学习过程中所采用的具体技术方法展开了详细讨论。
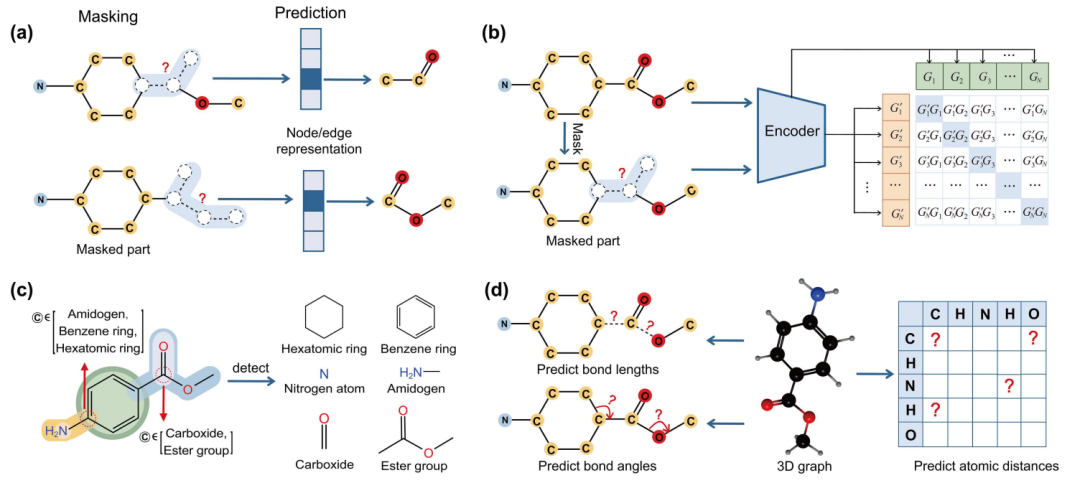
图 5 四种预训练策略
根据预训练任务的设计逻辑与核心目标差异,本文将现有分子预训练模型划分为四大典型类别,分别为:基于 mask 的预训练、基于对比学习的预训练、基于官能团的预训练以及基于空间结构的预训练。这四类预训练模型对应着提取分子有意义表示的不同技术路径,其核心思路均为充分利用分子自身独特的结构特征与化学性质,通过针对性的预训练过程,让模型提前学习到分子的关键信息,进而在后续的各类下游任务(如分子性质预测、反应预测等)中,显著增强模型对分子特征的理解与应用能力,最终实现模型性能的有效提升。
04 总结与展望
本文概述了基于序列、二维(2D)和三维(3D)分子表示方法,特别强调了分子预训练模型。本文讨论了不同的模型架构和预训练策略,并以分子性质预测任务为案例研究,结合成熟的数据集和评估标准,比较了最先进方法的性能。此外,本文还探讨了现有分子预训练模型的局限性,并提出了潜在的改进方向。展望未来,研究的目标是推动高性能模型在分子鉴定中的开发和应用,从而增强分子性质预测的能力并促进药物发现的进程。
参考资料:https://doi.org/10.1007/s11432-024-4457-2
文章改编转载自微信公众号:中国科学信息科学
原文链接:https://mp.weixin.qq.com/s/GJRZMeN1JyEwb-JNzdUxNQ | 





















