本帖最后由 Akkio 于 2025-9-4 16:39 编辑

AI 教父 Hinton 荣膺诺贝尔奖,可谓是实至名归。如今,他发表的「玻尔兹曼机」震撼演讲,已登上 APS 期刊。
这一曾催化深度学习革命的「历史酶」,究竟讲了什么?
2024 年 12 月 8 日,诺贝尔物理学奖得主 Hinton 登台,发表了题为《玻尔兹曼机》的演讲。
当时,斯德哥尔摩大学 Aula Magna 礼堂内座无虚席,全球目光都集聚于此。

他深入浅出地分享了自己与 John Hopfield 利用神经网络,推动机器学习基础性发现的历程。

如今,Hinton 这个演讲的核心内容,于 8 月 25 日正式发表在美国物理学会(APS)期刊上。

论文地址:https://journals.aps.org/rmp/pdf/10.1103/RevModPhys.97.030502
1980 年代,并存两种颇具前景的梯度计算技术——
一种是,反向传播算法,如今成为了深度学习核心引擎,几乎无处不在。
另一种是,玻尔兹曼机器学习算法,现已不再被使用,逐渐淡出人们的视野。
这一次,Hinton 的演讲重点,就是「玻尔兹曼机」。
一开场,他幽默地表示,自己打算做一件「傻」事,决定在不使用公式的情况下,向所有人解释复杂的技术概念。
01 霍普菲尔德网络找到能量最低点
什么是「霍普菲尔德网络」(Hopfield Network)?
Hinton 从一个简单的二进制神经元网络入手,介绍了「霍普菲尔德网络」的核心思想。
每个神经元只有 1 或 0 两种状态,最重要的是,神经元之间通过对称加权连接。
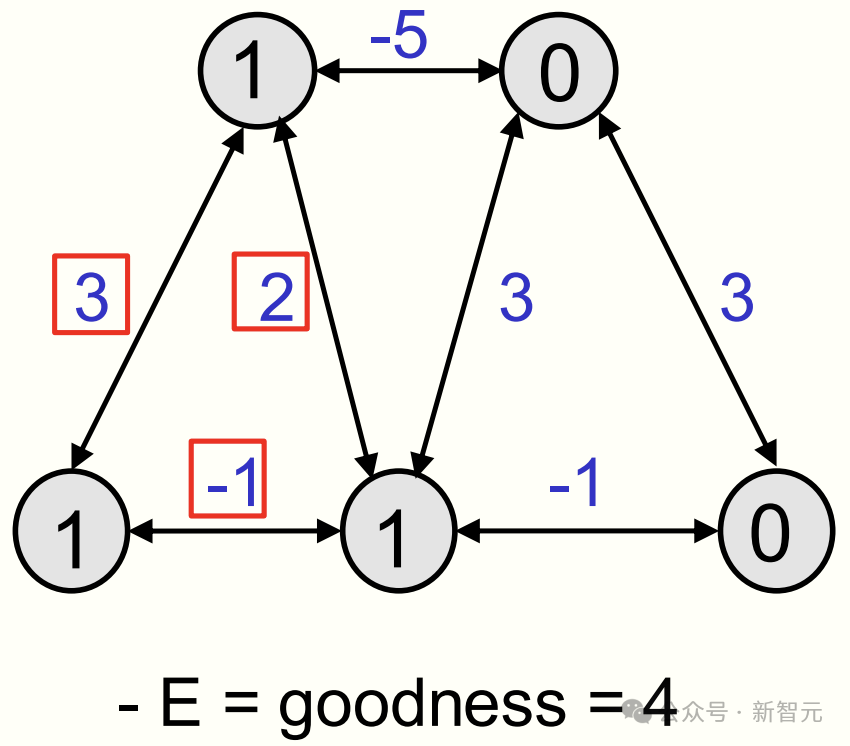
整个神经网络的全局状态,被称为一个「配置」(configuration),并有一个「优度」(goodness)。
其「优度」是由所有活跃神经元之间权重的总和决定,如上图所有红色方框,权重加起来等于 4。
这便是该网络配置的优度,而能量(energy)是优度的负值。
「霍普菲尔德网络」的全部意义在于,每个神经元通过局部计算决定如何降低能量。
在这里,能量就代表「劣度」(badness)。因此,开启还是关闭神经元,全凭总加权输入的「正负」。

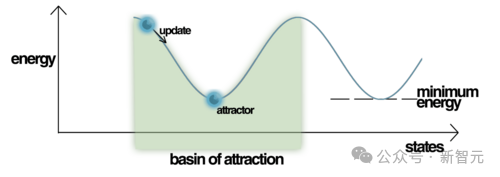
通过不断更新的神经元状态,网络最终会稳定在「能量最低点」。
但它并非是唯一的能量低点,因为「霍普菲尔德网络」可以有很多能量最低点,最终停留在哪一点,取决于起始状态,也取决于更新哪个神经元的随机决策序列。
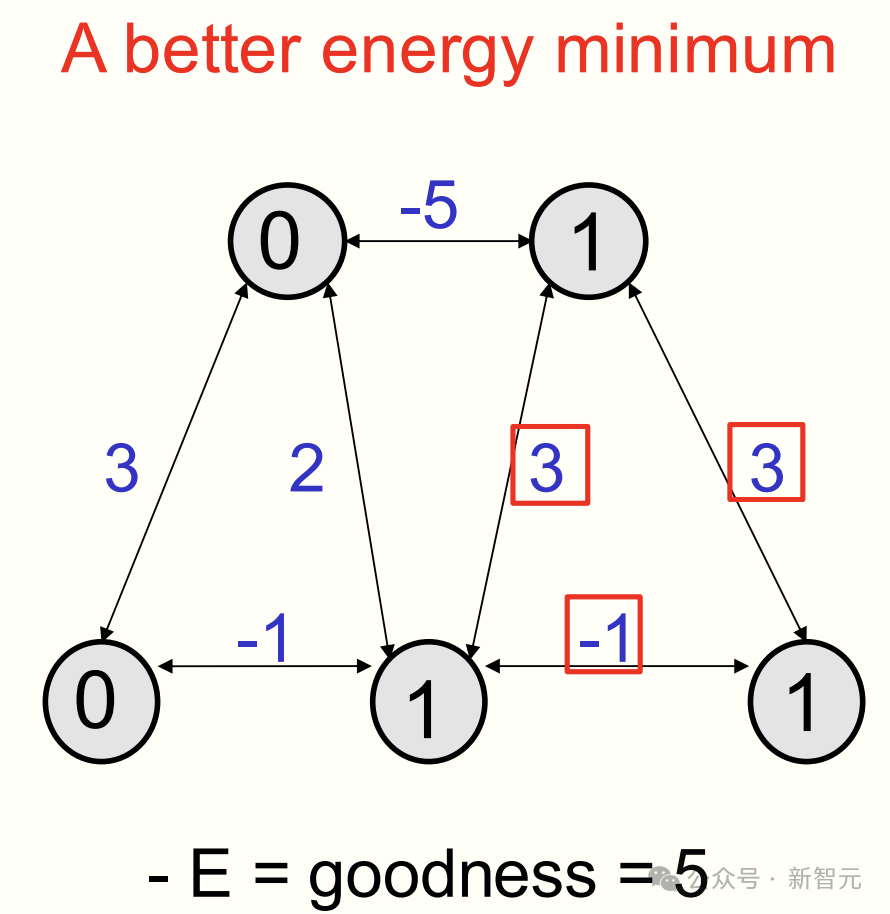
如下,便是一个更优的能量最低点。开启右边神经网络,其优度是 3+3-1,能量为 -5。
「霍普菲尔德网络」的魅力在于,它可以将能量最低点与记忆关联起来。
Hinton 生动地描述道,「当你输入一个不完整的记忆片段,然后不断应用二进制决策规则,网络就能补全完整记忆」。
因此,当「能量最低点」代表记忆时,让网络稳定到能量最低点的过程,就是实现所谓的「内容可寻址存储」。
也就意味着,仅激活项目一部分访问存储器中的某个项目,然后运用此规则后,网络就会将其补全。
02 不仅记忆存储,还能解释「感官输入」
接下来,Hinton 进一步分享了,自己与 Terrence Sejnowski(霍普菲尔德学生)对「霍普菲尔德网络」的创新应用——
用它来构建对感官输入的解释,而不仅仅是存储记忆。

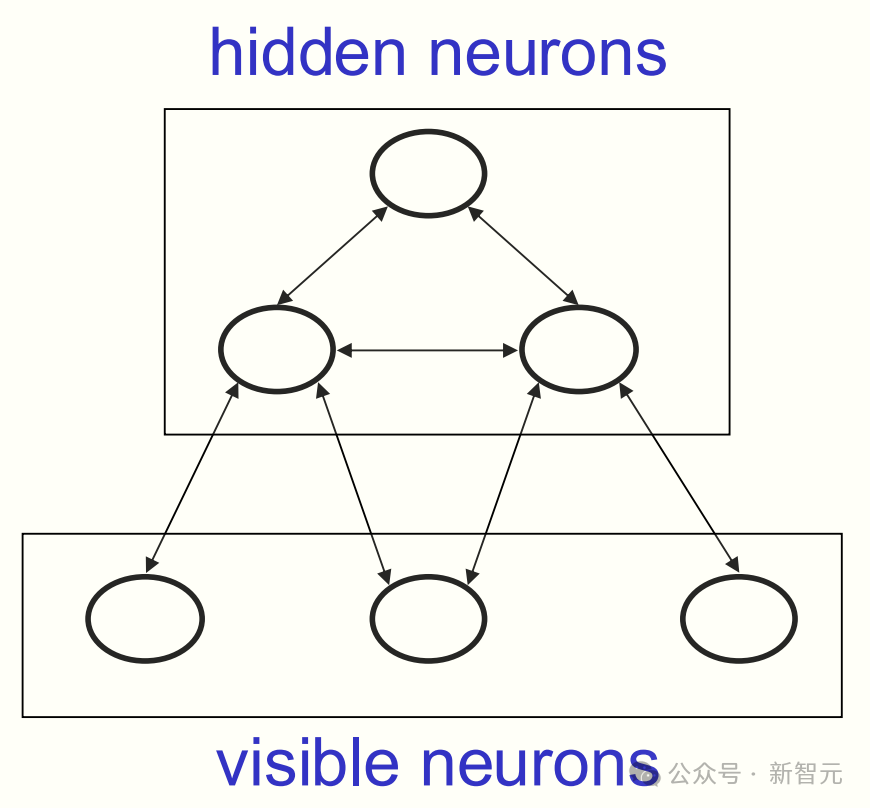
他们将网络分为了「可见神经元」和「隐藏神经元」。
前者接收感官输入,比如一幅二进制图像;后者则用于构建对该感官输入的解释。网络的某个配置的能量,代表了该解释的劣度,他们想要的是一种低能量的解释。
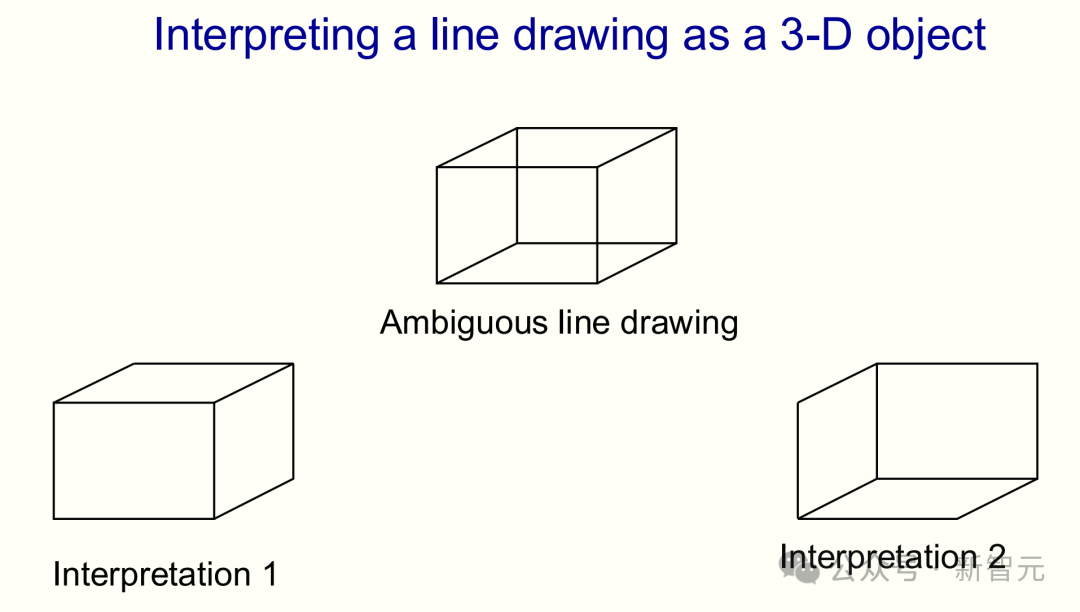
Hinton 以一幅经典的模棱两可的线条画——内克尔立方体(Necker cube)为例,展示了网络如何处理视觉信息的复杂性。
如下这幅画,有的人会将其看作是「凸面体」,有的人会看到的是「凹面体」。
那么,我们如何让神经网络,从这一幅线条画中得出两种不同的解释?在此之前,我们需要思考的是:图像中的一条线,能告诉我们关于三维边缘的什么信息?
视觉诠释:从 2D 到 3D
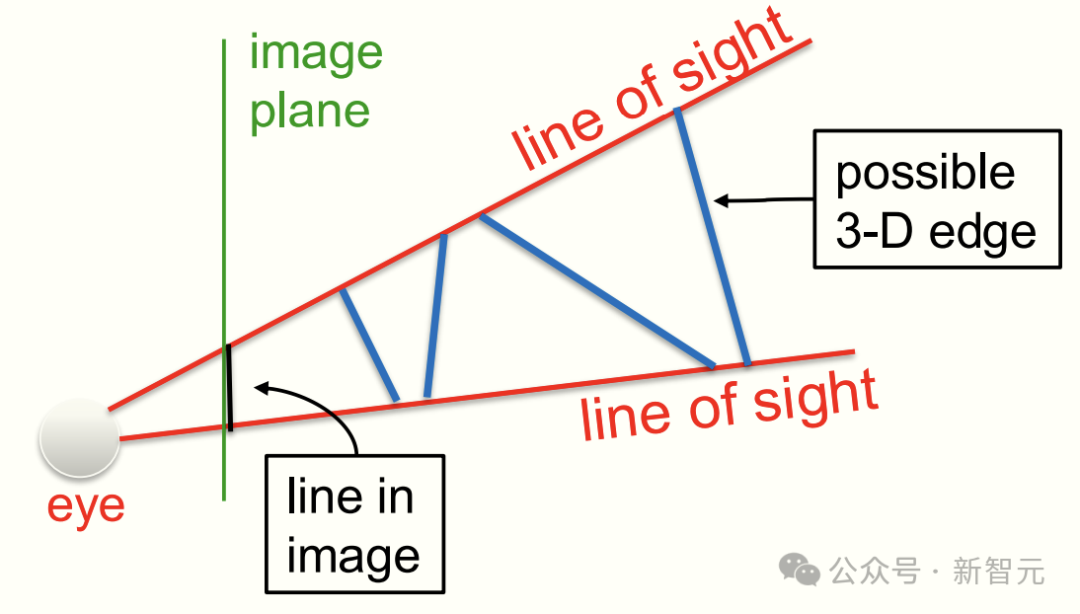
想象一下,你正透过一扇窗户看向外面的世界,然后在玻璃上,把看到的景物轮廓描绘出来。
这时候,窗上的那条黑线,其实就是你画出来的一条边。
而那两条红线呢,就是从你眼睛出发,穿过这条黑线两端的视线。
那么问题来了:现实世界中,到底是什么样的边缘形成了这条黑线?
其实可能性非常多,所有不同的三维边缘,最终都会在图像中产生同样的线条。
所以,视觉系统最头疼的是,怎么从这一条二维的线反推回去,判断现实中,到底哪条边才真正存在?
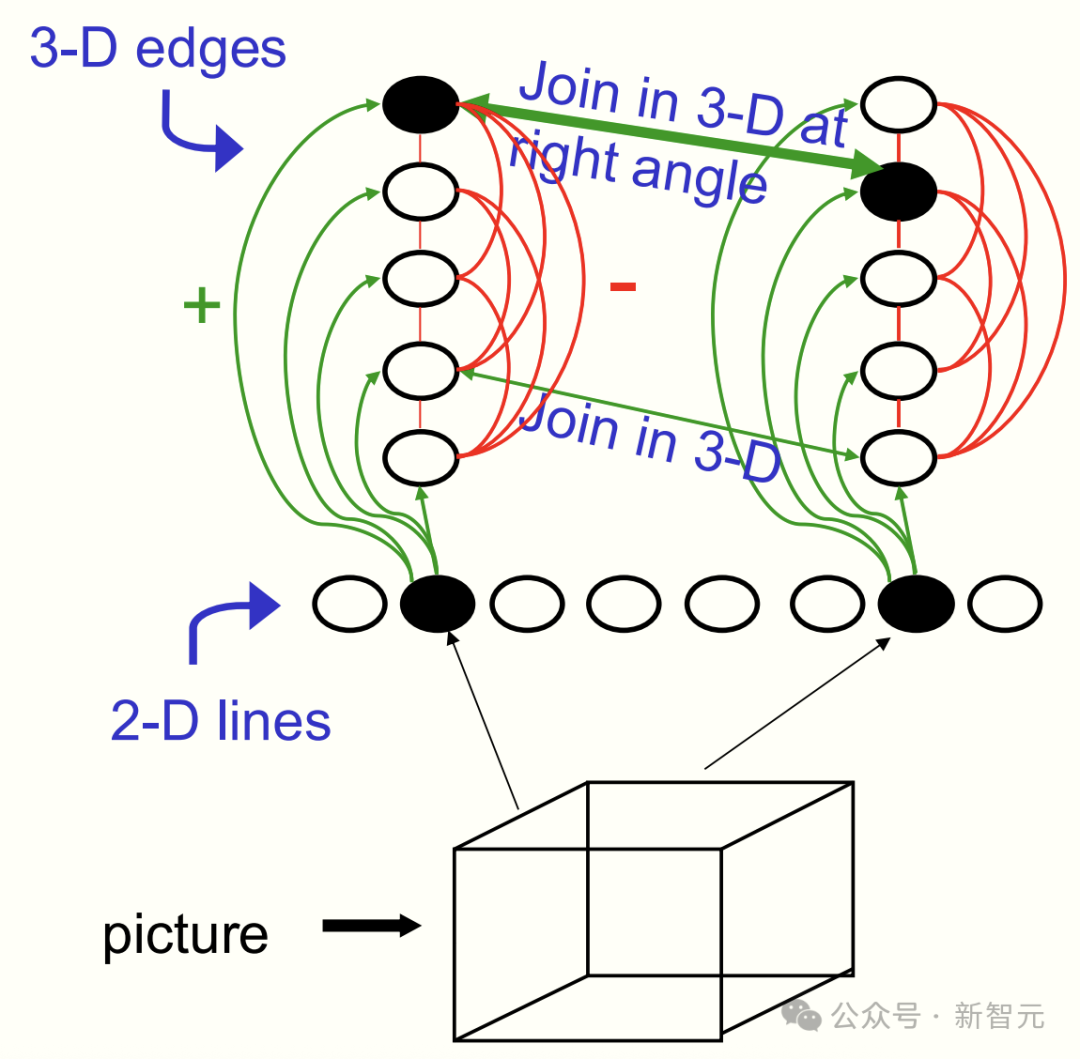
为此,Hinton 和 Sejnowski 设计了一个网络,可以将图像中的线条,转化为「线神经元」的激活状态。
然后,通过兴奋性连接与代表「三维边缘神经元」相连(绿色),并让其相互抑制,确保一次只激活一种解释。
如此一来,就体现了许多感知光学方面的原理。
接下来,Hinton 又将此方法应用于所有的神经元,问题是,应该激活哪些边缘神经元呢?
要回答这个问题,还需要更多信息。
人类在诠释图像时,都会遵循特定的原理。比如,两条线相交,假设它们在三维空间中,也在同一点相交,且深度相同。
此外,大脑往往倾向于将物体视为直角相交。
通过合理设置连接强度,网络可以形成两个稳定的状态,对应「内克尔立方体」的两种三维诠释——凹面体和凸面体。
这种视觉诠释方法,又带来了两个核心问题:
搜索问题:网络可能陷入局部最优,停留在较差的解释上,无法跳到更好的解释
学习问题:如何让网络自动学习连接权重,而不是手动设定

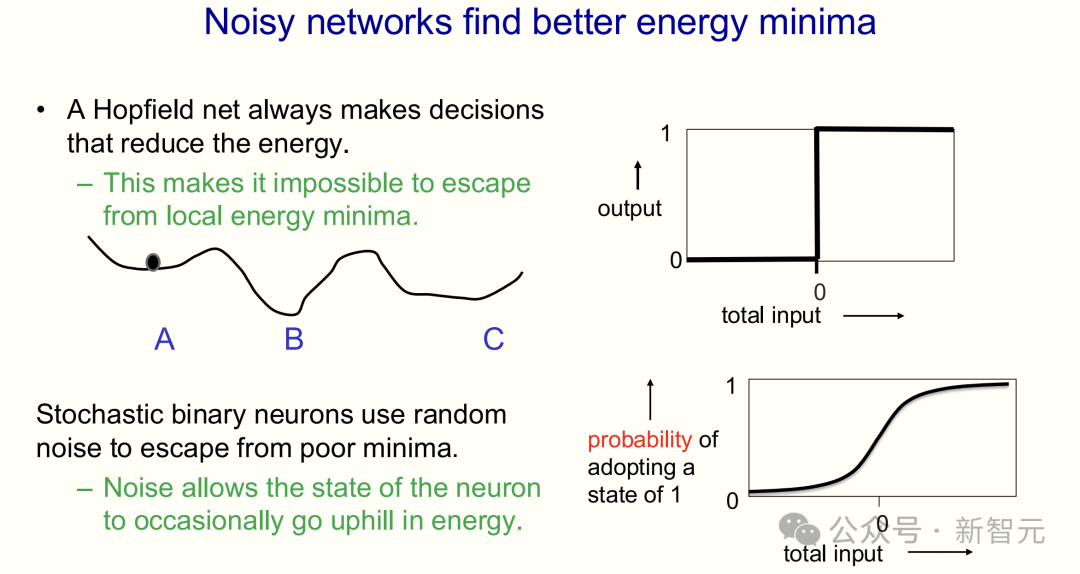
搜索问题:带噪声神经元
对于「搜索问题」,最基本的解决方法——引入带有噪声的神经元,即「随机二进制神经元」。
这些神经元状态为「二进制」(要么是 1,要么是 0),但其决策具有很强的概率性。
强的正输入,就会开启;强的负输入,就会关闭;接近零的输入则引入随机性。
噪声可以让神经网络「爬坡」,从较差的解释跳到更好的解释,就像在山谷间寻找最低点。
03 玻尔兹曼分布+机器学习
通过随机更新隐藏神经元,神经网络最终会趋近于所谓的「热平衡」(thermal equilibrium)。
一旦达到热平衡,隐藏神经元的状态就构成了对输入的一种诠释。
在热平衡下,低能量状态(对应更好解释)出现概率更高。
以内克尔立方体为例,网络最终会倾向于选择更合理的三维诠释。
当然,热平衡并非系统停留在单一状态,而是所有可能配置的概率分布稳定,遵循着玻尔兹曼分布(Boltzmann distribution)。
在玻尔兹曼分布中,一旦系统达到热平衡,其处于某个特定配置的概率,完全由该配置的能量决定。
并且,系统处于低能量配置的概率会更高。
要理解热平衡,物理学家们有一个诀窍——你只需想象一个由海量相同网络组成的巨大「系综」(ensemble)。
Hinton 表示,「想象无数相同的霍普菲尔德网络,各自从随机状态开始,通过随机更新,配置比例逐渐稳定」。
同样,低能量配置,在「系综」中占比更高。
总结来说,玻尔兹曼分布的原理在于:低能量的配置远比高能量的配置更有可能出现。
而在「玻尔兹曼机」中,学习的目标,就是要确保当网络生成图像时,本质上可以称为「做梦、随机想象」,这些与它在「清醒」时感知真实图像所形成的印象相吻合。
若是可以实现这种吻合,隐藏神经元的状态,便可以有效捕捉到图像背后的深层原因。

换句话说,学习网络中的权重,就等同于弄清楚如何运用这些隐藏神经元,才能让网络生成出看起来像真实世界的图像。
「玻尔兹曼机」学习算法
针对如上「学习问题」,Hinton 与 Sejnowski 在 1983 年,提出了「玻尔兹曼机学习算法」进而解决了权重调整问题。

论文地址:https://www.cs.toronto.edu/~fritz/absps/cogscibm.pdf
该算法主要包含了两个阶段:
清醒阶段:向网络呈现真实图像。将一幅真实图像「钳位」到可见单元上,然后让隐藏单元演化至热平衡。对同时开启的神经元对,增加连接权重。
睡眠阶段:让网络自由「做梦」。所有神经元随机更新至热平衡。对同时开启的神经元对,减少连接权重。
这一简单的算法,通过调整权重,提高了神经网络在「做梦」时生成的图像与「清醒」时感知图像之间的相似度。

学习过程的本质,就是在降低网络在清醒阶段,从真实数据中推导出的配置所对应的能量。
与此同时,提高它在睡眠阶段自由生成的配置所对应的能量。
正如 Hinton 所言,「你本质上是在教导这个网络:要相信清醒时所见,而不信睡梦中所梦」。
04 核心创新:相关性差异
如上所见,「玻尔兹曼机」的最大亮点在于,权重调整所需的信息都蕴含在两种相关性差异中——
网络在「清醒」(观察真实数据)时两个神经元共同激活的频率,与当网络自由「做梦」时,它们共同激活的频率,这两者之间的差异。
令人惊叹的是,这两种相关性差异,足以告诉某个权重关于所有其他权重的一切信息。
与反向传播(backpropagation)算法不同,「**玻尔兹曼机」无需复杂的反向通路传递「敏感度」——一种完全不同的物理量信息**。

「反向传播」算法依赖的是,前向通路传递神经元活动,反向通路传递敏感度;「玻尔兹曼机」仅通过对称连接性和相关性差异完成学习。
然而,「玻尔兹曼机」的最大瓶颈是——速度。
当权重较大时,达到热平衡极其缓慢,若是权重很小,这个过程才得以加速完成。
整整 17 年后,Hinton 突然意识到,通过消除隐藏单元之间的连接来对「玻尔兹曼机」进行限制,就可以得到一个快得多的学习算法。
由此,受限玻尔兹曼机(RBM)诞生了。

这一方法将输入「钳位」在可见单元上,大幅简化了「清醒」阶段的计算,仅需一步即可达到热平衡。
不过,「睡眠」阶段仍需要多次迭代,才能达到热平衡。
为此,Hinton 引入了「对比散度」(contrastive divergence)的方法,通过以下步骤实现了加速学习:
1. 将数据输入可见单元。
2. 并行更新所有隐藏神经元,使其与数据达到平衡。
3. 更新所有可见单元以得到一个「重构」版本。
4. 再次更新所有隐藏神经元。
5. 停止。
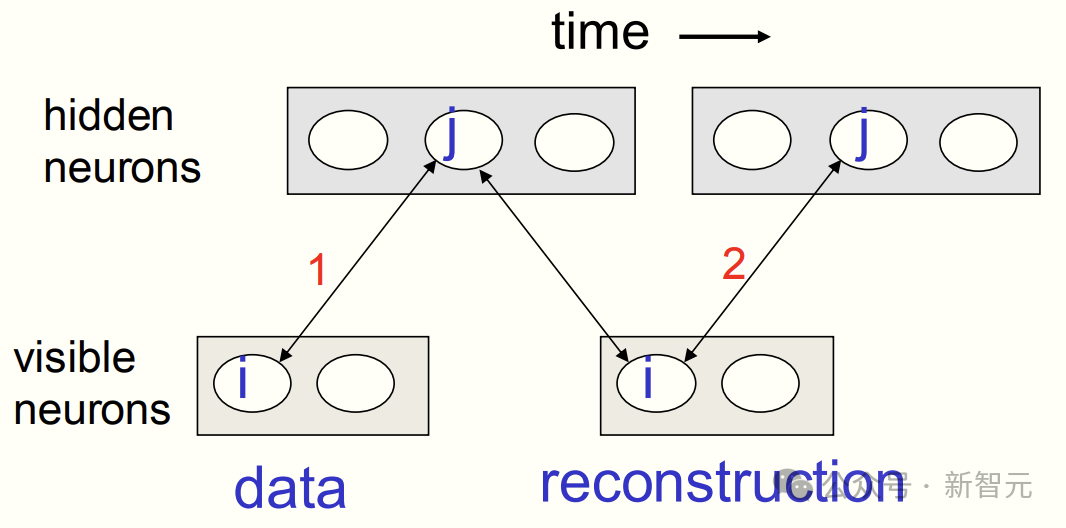
「受限玻尔兹曼机」也在实践中取得了显著成果。
比如,Netflix 公司曾使用 RBM,根据用户偏好推荐电影,并赢得了用户偏好预测大赛。
然而,仅靠彼此不相连的隐藏神经元,是无法构建出识别图像中的物体/语音中,单词所必需的多层特征检测器。
为此,2006 年,Hinton 进一步提出了「堆叠 RBM」的方法。
堆叠 RBM
通过以下三步,就可以实现堆叠 RBM:
1. 用数据训练一个 RBM。
2. 将该 RBM 的隐藏层激活模式作为数据,用于训练下一个 RBM。
3. 持续这个过程,以捕捉日益复杂的关联。
在堆叠了这些玻尔兹曼机之后,可以将它们视为一个前馈网络,忽略其对称连接,只使用单向的连接。
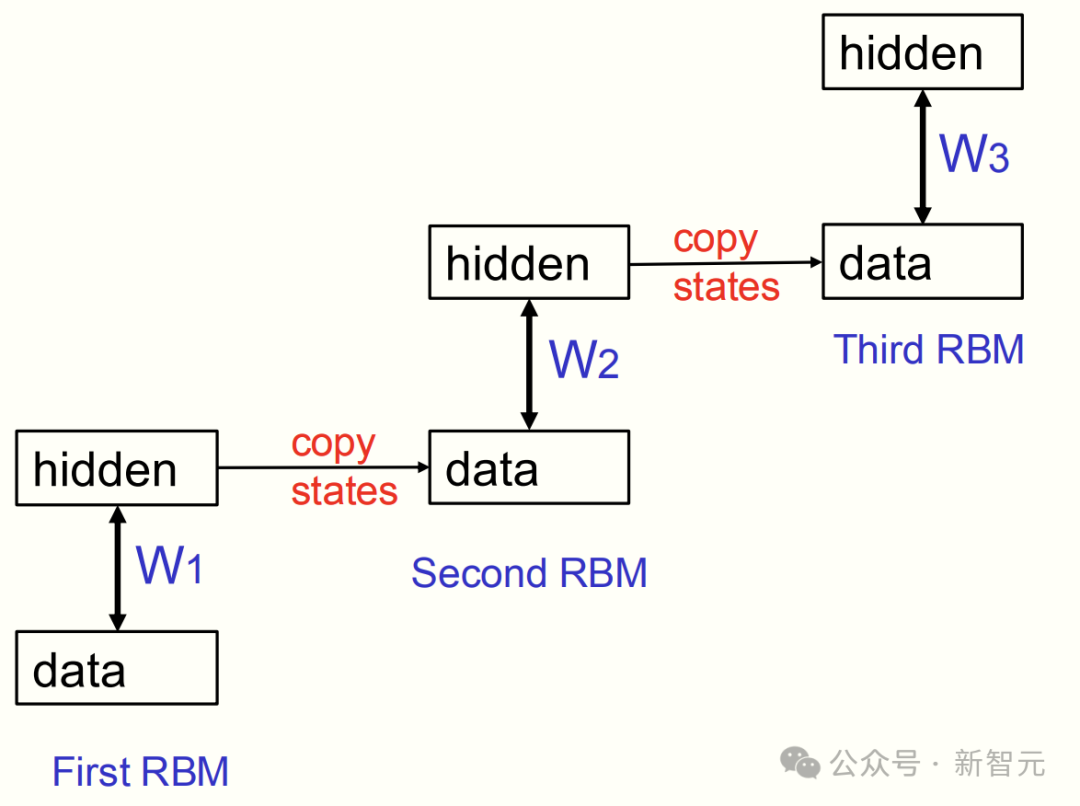
由此,这创建了一个特征的层级结构:
第一隐藏层:捕捉原始数据中相关性的特征。
第二隐藏层:捕捉第一层特征之间相关性的特征。
以此类推,创建出越来越抽象的表示。
等所有堆叠完成后,可以再添加一个「最终层」进行监督学习,比如分类猫和狗的图像。
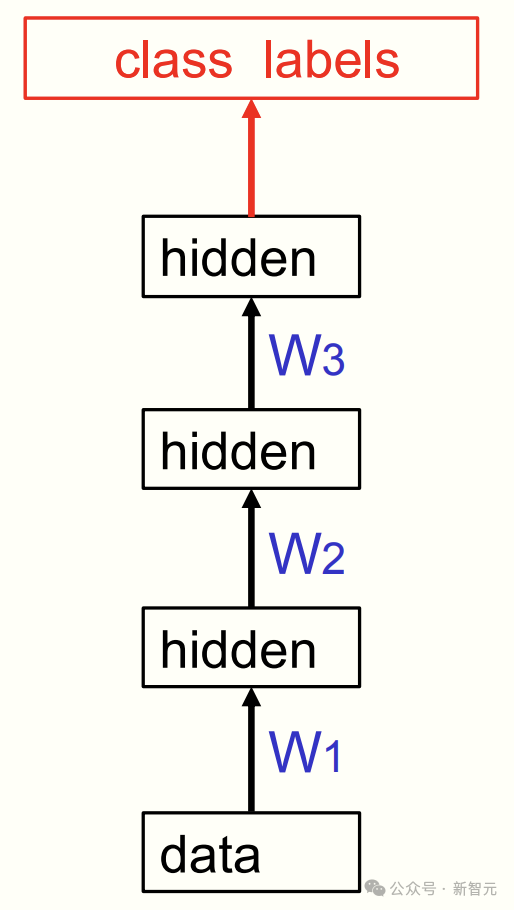
这时,神经网络展现出两大优势——
学习速度远超随机初始化:因其在预训练中,已学习到了用于建模数据结构的合理特征。
网络的泛化能力也更好:大部分学习在无监督情况下进行,信息从数据相关性中提取。
05 历史的「酶」
2006-2011 期间,Hinton、Bengio、LeCun 等实验室研究人员,都在使用「堆叠 RBM」预训练前馈神经网络,然后再进行反向传播微调。
直到 2009 年,Hinton 的学生 George Dahl 和 Abdel-rahman Mohamed 证明:
「堆叠 RBM」在识别语音中的音素片段方面,效果显著优于当时所有的方法。
这一发现,彻底改变了整个语音识别领域。
到了 2012 年,基于「堆叠 RBM」的系统,在谷歌安卓设备上大幅改善了语音识别性能。

论文地址:https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/38131.pdf
然而,不幸的是,一旦证明了「堆叠 RBM」预训练的深度神经网络的潜力,研究人员很快开发了其他初始化权重的方法。
于是,「玻尔兹曼机」逐渐退出历史主流。
最后,Hinton 做了一个非常生动形象的比喻:
但如果你是化学家,你就会知道「酶」是非常有用的东西。
「玻尔兹曼机」就像化学中「酶」,催化了深度学习的突破,一旦完成这个转变,酶就不再被需要。
所以,不妨把它们看作是「历史的酶」。
不过,Hinton 认为,利用「睡眠」阶段的「反学习」(unlearning),从而得到一个更具生物学合理性、避免反向传播的非对称通路的算法。
到目前为止,他依旧坚信:有一天搞明白大脑如何学习的时候,一定会发现,睡眠中「反学习」绝对是关键一环。

Reference:
1、https://singjupost.com/transcript-of-nobel-prize-lecture-geoffrey-hinton-nobel-prize-in-physics-2024/
2、https://journals.aps.org/rmp/abstract/10.1103/RevModPhys.97.030502
3、https://www.nobelprize.org/uploads/2024/12/hinton-lecture-1.pdf
4、https://www.ccn.com/education/crypto/geoffrey-hinton-ai-godfather-machine-learning/
文章转载自微信公众号:量子前哨
原文链接:https://mp.weixin.qq.com/s/8gGszBuqc9HTwtXENcSC1A?scene=1&click_id=1 | 





















