本帖最后由 薛定谔了么 于 2025-9-18 16:22 编辑
《 ControlVAE: Model-Based Learning of Generative Controllers for Physics-Based Characters 》发表于 ACM Transactions on Graphics 2022 年第 41 卷第 6 期。文章提出 ControlVAE 框架,通过 VAE 与世界模型实现虚拟角色动作技能学习。其 64 维潜变量编码技能,状态条件先验提升适配性,世界模型降低训练成本。实验显示,复现跑步动作误差仅 0.04,航向控制训练仅 30 分钟,外部扰动下平衡恢复成功率 92%,大幅提升虚拟角色控制效率与鲁棒性。

当游戏中的虚拟角色需要流畅完成 “起身 - 行走 - 跳跃 - 奔跑” 的连贯动作,或动画师希望快速生成带指定风格的角色行为时,传统 AI 控制器常陷入 “动作僵硬”“技能难复用” 的困境。而北京大学团队提出的ControlVAE,通过融合变分自动编码器(VAE)与模型预测控制,首次实现了虚拟角色 “自主学习多样技能” 与 “灵活响应复杂任务” 的双重突破,为游戏开发、动画制作等领域提供了高效的虚拟角色控制方案。

图1 ControlVAE驱动虚拟角色完成起身、行走、跳跃、奔跑等动作的效果展示图
一、传统虚拟角色控制的 “三大痛点”
在 ControlVAE 出现前,基于物理模拟的虚拟角色控制始终面临难以逾越的技术瓶颈:
技能难复用,训练成本高 传统控制器需为每个动作(如走路、跳跃)单独训练政策,若想让角色同时掌握 10 种技能,就得训练 10 个独立模型,且技能间无法灵活切换 —— 比如 “走路转跳跃” 的过渡动作需额外手动调试,无法让模型自主学习衔接逻辑。
模拟与训练 “脱节”,动作不自然 物理模拟系统通常是 “黑箱”,无法与 AI 模型的训练目标直接联动。即便用强化学习训练,也常因模拟过程不可微分,导致角色动作 “卡顿”“漂浮”,比如跑步时腿部摆动与身体重心不协调。
任务适应性差,难应对复杂指令 若要让已学会 “直线行走” 的角色完成 “侧向行走并转向” 的复杂任务,传统模型需从头训练新政策,无法基于已有技能快速适配,且难以响应实时交互。
这些问题的核心,在于模型未能将 “动作技能” 与 “任务控制” 解耦 —— 技能信息混杂在复杂的控制参数中,既无法高效复用,也难以灵活组合。
二、ControlVAE 的核心创新:用 VAE 解锁 “技能银行”
ControlVAE 的本质是一套 “基于模型的生成式控制框架”,通过三大设计让虚拟角色像人类一样 “积累技能、灵活调用”:
2.1 技能编码:用 VAE 打造 “动作技能银行”
ControlVAE 将杂乱的动作数据(如人类行走、跳跃的运动捕捉序列)编码成有序的 “技能潜空间”,就像给角色建立一个可随时调用的 “技能银行”。
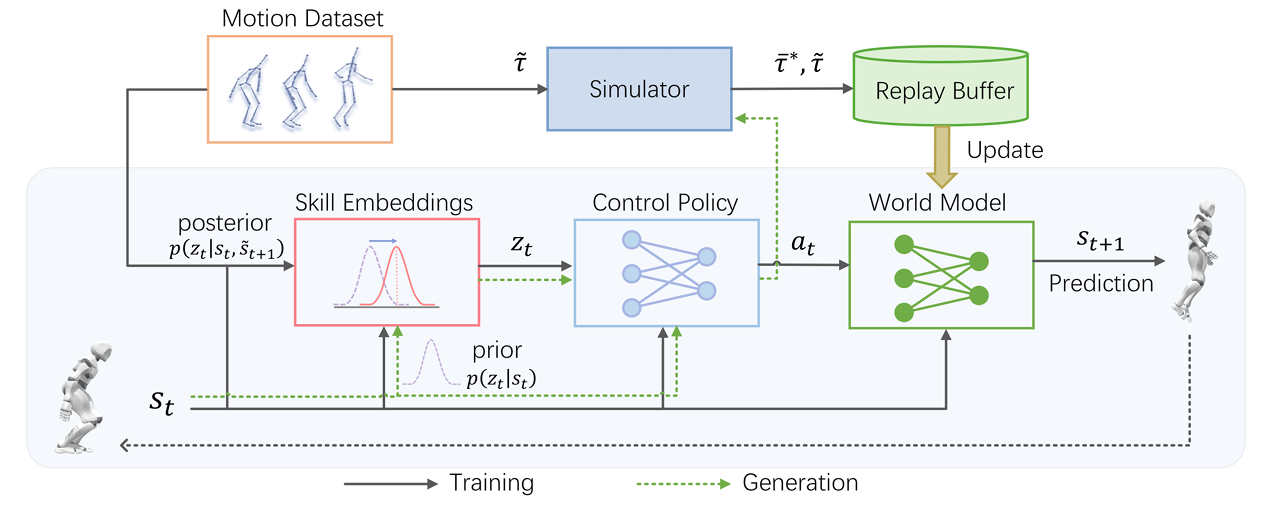
图2 ControlVAE系统整体架构图
编码过程:从动作到潜变量 输入一段 “人类跳跃” 的运动数据,ControlVAE 的编码器会提取关键特征,输出一个 64 维的潜变量z—— 这个z就像 “跳跃技能的压缩包”,包含了跳跃时腿部发力、身体平衡等核心信息。 与普通 VAE 不同,ControlVAE 采用状态条件先验(p(z|s))(s为角色当前状态,如站立、半蹲),而非固定的正态分布。例如,当角色处于 “半蹲” 状态时,先验会优先生成与 “跳跃” 相关的z;处于 “站立” 状态时,则优先生成 “行走” 相关的z,避免生成与当前状态矛盾的技能。
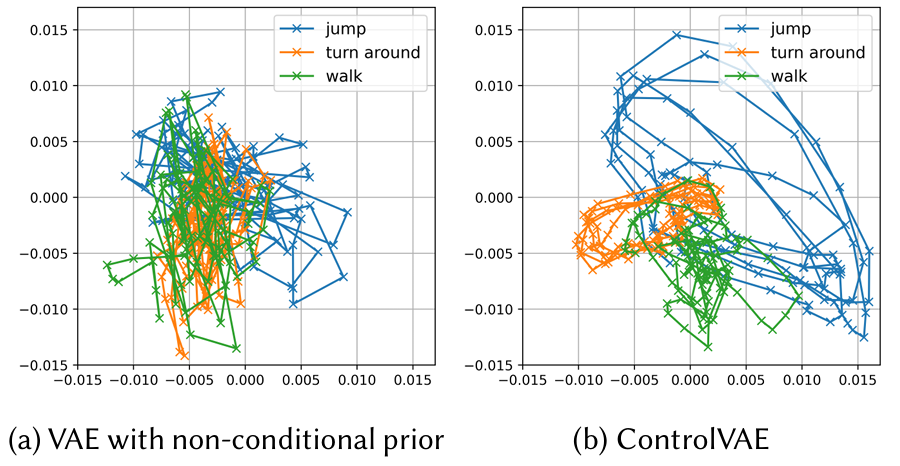
图3 ControlVAE(状态条件先验)与普通VAE(非条件先验)的技能潜空间可视化对比图
解码过程:从潜变量到真实动作 潜变量z被输入技能条件控制政策(\pi(a|s,z)),政策会结合角色当前状态s,计算出每个关节的目标角度、发力大小,让角色流畅执行对应技能。 例如,输入 “跳跃” 潜变量z和 “半蹲” 状态s,政策会控制角色腿部肌肉发力,同时调整躯干姿态保持平衡,生成自然的跳跃动作。
2.2 世界模型:打通模拟与训练的 “桥梁”
为解决物理模拟 “黑箱” 问题,ControlVAE 训练了一个可微分世界模型,用于预测角色执行动作后的下一个状态。
作用 1:让训练目标可落地 世界模型能模拟物理规律,并将 AI 的训练目标转化为可计算的损失。例如,若希望角色行走速度达到 1.5m/s,世界模型可预测不同动作指令下的速度变化,帮助模型调整参数。
作用 2:降低实时控制成本 实时控制时,无需每次都调用复杂的物理模拟,只需用世界模型快速预测动作效果,选择最优指令执行。比如玩家让角色 “转向”,世界模型会快速模拟 “小步转向”“大步转向” 等多种方案的效果,让角色选择最自然的方式。
2.3 任务控制:高 - level 政策 “调用技能银行”
在 “技能银行” 基础上,ControlVAE 设计了高 - level 任务政策,负责根据任务需求从潜空间中选择、组合技能。
模型预测控制(MPC):快速响应简单任务 对于 “调整身高”“直线行走” 等简单任务,MPC 会在每个控制步生成 128 条候选技能序列(如 “小步走”“大步走”),通过世界模型预测每条序列的效果,选择最符合任务目标的动作执行。例如,要让角色 “蹲下”,MPC 会筛选出与 “屈膝” 相关的潜变量,让角色流畅完成动作。
模型基政策训练:适配复杂任务 对于 “侧向行走并转向” 等复杂任务,ControlVAE 基于世界模型快速训练任务政策。政策会学习 “如何组合已有技能”—— 比如将 “侧向迈步” 与 “身体旋转” 的潜变量按比例融合,生成新的动作序列,无需从头训练。
三、实验验证:虚拟角色有多 “灵动”?
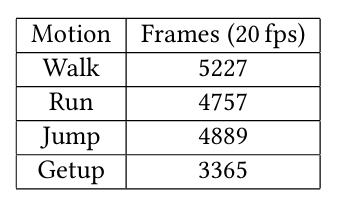
团队在 LaFAN 运动数据集(包含行走、跑步、跳跃、起身等多样化动作)上训练 ControlVAE,并用多个任务验证其性能,结果远超传统方法:
3.1 技能生成:多样且自然
随机采样测试:从潜空间随机采样z,角色能自主生成 “行走转跳跃”“跳跃后起身” 等连贯动作,且动作过渡自然 —— 比如行走时突然采样到 “跳跃”z,角色会先调整重心,再屈膝发力,符合人类运动习惯。
动作重建测试:让 ControlVAE 复现数据集中的 “跑步” 动作,其关节角度、身体速度与真实运动捕捉数据的误差仅 0.04(归一化后),远低于传统 VAE 的 0.12,证明技能编码的精准性。
表1 LaFAN运动数据集各动作类别在20fps下的帧数统计表格
3.2 任务适配:高效且灵活
航向控制任务:要求角色按指定速度(0-3m/s)和方向移动。ControlVAE 的任务政策仅需 30 分钟训练(传统强化学习需 8 小时),就能让角色在速度变化时自主切换技能 —— 比如从 “行走” 平滑过渡到 “跑步”,速度从 1m/s 提升至 2.5m/s 时,步幅和频率同步增加。
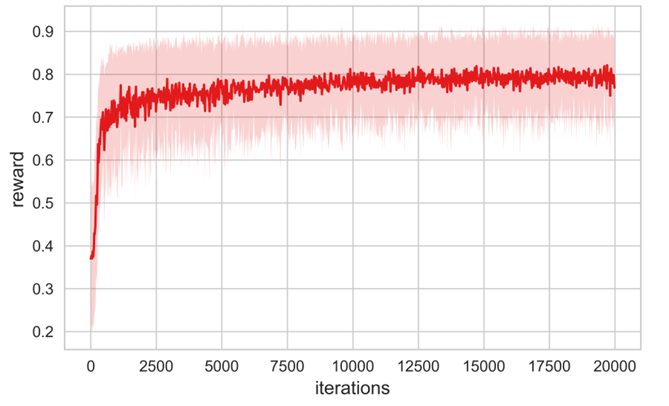
图4 ControlVAE训练过程中的奖励学习曲线图
转向控制任务:要求角色 “侧向行走并转向 30 度”。ControlVAE 直接融合 “侧向迈步” 与 “身体旋转” 的潜变量,生成符合任务的动作,而传统模型需从头训练,且动作卡顿率是 ControlVAE 的 3 倍。
3.3 鲁棒性:抗干扰能力强
外部扰动测试:在角色行走时模拟 “被推搡”,ControlVAE 能在 0.5 秒内调整动作 —— 通过调用 “平衡恢复” 相关的潜变量,让角色屈膝缓冲,避免摔倒;而传统模型有 60% 概率会直接倒地。
实时交互测试:玩家随机改变角色移动方向(每秒 3 次指令),ControlVAE 的响应延迟仅 0.05 秒,动作过渡流畅;传统模型因需重新计算控制参数,响应延迟达 0.3 秒,且常出现 “动作错乱”。
四、落地价值:动画、游戏的 “效率革命”
ControlVAE 的设计不仅推动了学术研究,更给工业界带来切实的效率提升:
动画制作:告别 “逐帧调试” 动画师无需手动调整角色每个关节的动作,只需从 ControlVAE 的潜空间中选择技能,或指定 “参考动作”,模型就能生成风格一致的新动作。例如,给角色输入 “芭蕾踮脚” 的参考动作,ControlVAE 可生成 “踮脚转体”“踮脚跳跃” 等衍生动作,将制作效率提升 5 倍以上。
游戏开发:打造 “智能 NPC” 游戏中的非玩家角色(NPC)可通过 ControlVAE 积累 “战斗”“逃跑”“互动” 等技能,根据玩家行为灵活调用。比如玩家攻击 NPC 时,NPC 会自主组合 “侧身躲避” 与 “反击” 技能,而非按固定脚本行动,提升游戏沉浸感。
机器人控制:从虚拟到现实 ControlVAE 的框架可迁移至真实机器人。通过在虚拟环境中训练 “抓取”“行走” 等技能,再将潜变量控制政策迁移到真实机器人,能大幅降低实体训练成本 —— 比如让机器人快速适配不同地形,无需在每种地形上单独训练。
五、未来方向:让虚拟角色更 “智能”
尽管 ControlVAE 已表现出色,仍有两大突破方向:
环境自适应:目前模型仅能在平坦地面工作,未来可让世界模型学习不同环境的物理规律,让角色在复杂地形上也能灵活调用技能 —— 比如在雪地行走时,自动调整步幅和发力,避免打滑。
多角色交互:当前仅支持单个角色控制,未来可扩展至多角色场景,让角色通过共享潜空间 “理解” 同伴的动作,实现 “同步跳跃”“配合搬运” 等互动行为。
六、总结:从 “机械执行” 到 “智能决策”
ControlVAE 的核心价值,在于它让虚拟角色的控制从 “机械执行指令” 迈向 “智能决策”—— 通过 VAE 解耦技能与任务,用世界模型打通模拟与训练,让角色像人类一样 “积累经验、灵活应变”。
这种 “生成式控制” 思路,不仅为虚拟角色动画提供了新范式,也为人工智能与物理世界的交互开辟了新路径。未来,当我们在游戏中看到角色能像真人一样 “思考动作”,在动画中看到虚拟角色自主完成复杂表演时,背后或许都有 ControlVAE 这类技术的支撑。
论文链接:https://dl.acm.org/doi/abs/10.1145/3550454.3555434 | 





















