本帖最后由 graphite 于 2025-10-15 04:33 编辑
今天为大家介绍的是来自香港理工大学数据科学与人工智能学院的Kay Chen Tan教授团队与中山大学、香港城市大学(东莞)、西北工业大学合作发表在基因组学领域顶级期刊 Genome Biology(IF=9.4,中科院一区Top)的论文,博士生何昊淮为第一作者,香港城市大学(东莞)助理教授黄志安与西北工业大学副教授黄裕安为通讯作者。研究人员在单细胞分析领域取得重要突破,该团队开发了一种名为scKAN的可解释深度学习框架,能够利用创新的科尔莫戈罗夫-阿诺德网络(KAN),不仅实现了高精度的细胞类型注释,还能系统性地发现细胞特异性的功能基因与基因集,并成功将其应用于胰腺癌的药物重定位研究,展现了其连接基础研究与临床应用的巨大潜力。

单细胞技术通过提供前所未有的高分辨率视角,彻底改变了我们对生物过程和人类疾病中细胞异质性的理解。细胞类型注释作为这一技术革命的基石,其核心依赖于识别区分不同细胞群体的独特基因表达特征(即标志基因)。然而,除了作为身份标识,这些基因中的一部分对于维持细胞身份和功能至关重要,它们编码了关键的组织特异性调控因子,是极具潜力的治疗靶点,尤其在癌症研究中备受关注。因此,开发能够系统性识别这些功能性基因的计算方法,对于深化疾病理解和加速药物开发具有重大意义。
尽管基于人工智能的技术,特别是大语言模型(LLM),在单细胞分析领域展现出巨大潜力,但现有方法仍面临三大技术挑战。首先,这些模型通常需要海量的计算资源进行预训练,并且在应用于新数据集时仍需大量的微调才能达到理想精度。其次,它们所依赖的注意力机制通过计算所有基因的加权信息来学习一个“全局上下文”,虽然强大,但这种全局性使得模型难以直接、清晰地分离和解释特定于某一细胞类型的基因互作关系,模型可解释性仍存在局限性。最后,目前的单细胞分析方法大多孤立于下游应用,其分析得出的生物学见解与药物发现等实际治疗开发之间存在一条难以逾越的鸿沟。
针对这些痛点,作者团队开发了scKAN,一个为解决上述挑战而设计的可解释深度学习框架。该框架的核心目标是实现精准的细胞类型注释,并同步识别具有生物学意义的细胞特异性标志基因与基因集。为了实现这一目标,scKAN创新性地整合了知识蒸馏策略与科尔莫戈罗夫-阿诺德网络(KAN)。知识蒸馏组件通过从一个大型预训练模型中高效迁移知识,解决了模型对大量微调的依赖,保证了计算效率。而KAN组件则利用其独特的可学习激活曲线直接对基因与细胞的关系进行建模,摆脱了Transformer模型“全局上下文”的限制,提供了细胞类别层级的特异性解释。最终,这些可解释的输出为下游应用(如药物重定位)提供了信息丰富的基因特征,构筑了从单细胞分析到治疗策略开发的桥梁。
模型框架
如图1所示,scKAN的模型架构采用知识蒸馏策略,由一个“教师模型”(预训练的单细胞LLM)和一个“学生模型”(基于KAN的轻量级网络)构成。整个框架的开发分为两步:首先,在一个特定数据集上微调一个已在海量无标签细胞数据上预训练过的大模型;其次,通过知识蒸馏训练学生模型,使其能够融合教师模型的先验知识和真实细胞类型的标签信息。
教师模型采用了领域内最先进的单细胞基础模型scGPT。该模型基于Transformer架构,已在超过3300万个细胞上进行了广泛的预训练,捕获了包括胰腺和血液细胞在内的多种人类细胞类型的表达模式。具体而言,scGPT将基因ID编码为基因词元(gene tokens),将表达值通过分箱(binning)处理获得表达嵌入,并融合批次效应等条件嵌入。这些多维度的信息通过多层Transformer网络进行处理,使得教师模型对人类细胞类型具备了深刻的理解。
学生模型scKAN是整个框架的创新核心,它由多层科尔莫戈罗夫-阿诺德网络(KAN)构成。遵循科尔莫戈罗夫-阿诺德表示定理,KAN模型的核心思想是学习网络“边”上的激活函数曲线,而非传统多层感知机(MLP)中的固定权重。如图1d所示,这些激活函数由可学习的B样条曲线(B-splines)拟合而成,能够灵活地捕捉基因表达与细胞类型之间潜在的、高度非线性的复杂关系。
为了确保学生模型能够有效学习并优化其表征能力,作者设计了一个复合损失函数。该函数包含三个关键部分:知识蒸馏损失,它结合了传统的交叉熵损失和来自教师模型的“软标签”分布,引导学生模型模仿教师模型的预测行为;自熵损失(self-entropy loss),它通过惩罚模型对优势细胞类型预测的过度集中,确保模型对稀有细胞群体保持敏感性;以及一个改进的深度散度聚类(DDC)损失,它利用柯西-施瓦茨散度来优化隐藏层特征与理想细胞类型分布之间的一致性。这个精巧的损失函数设计,引导模型学习到跨不同细胞类型都具有泛化能力的强大特征表示。
训练完成后,KAN的架构赋予了其强大的可解释性。首先,最初用于网络剪枝的边分数被改进用于量化每个基因对特定细胞类型分类的贡献度,从而直接识别标志基因。其次,通过对学习到的相似激活函数曲线进行聚类,可以揭示功能相关的基因集和细胞特异性通路。
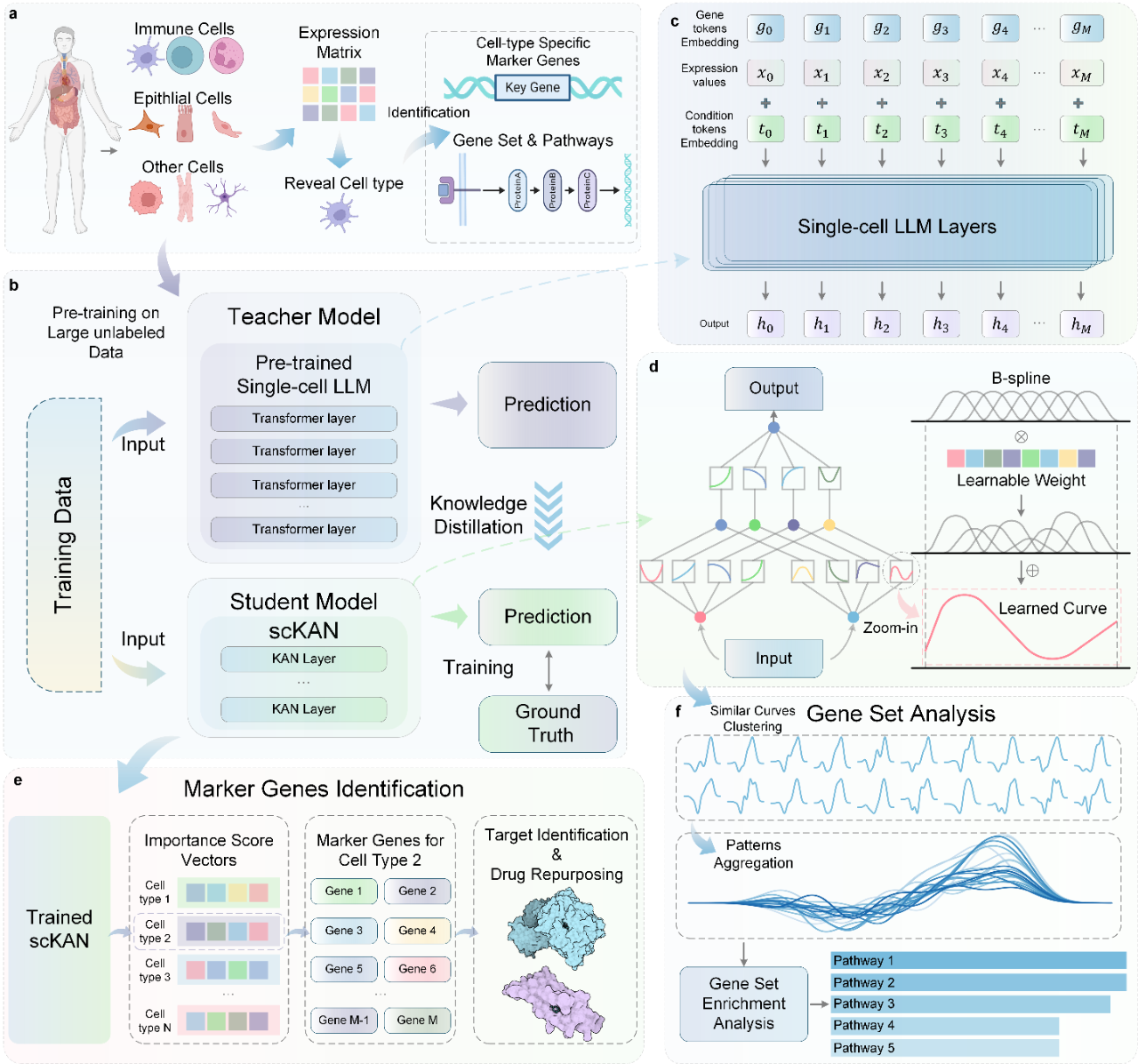
图1:模型架构和工作流程
scKAN在跨研究和跨疾病场景下表现稳健
为了全面评估scKAN在真实世界复杂场景下的泛化能力和稳定性,研究团队设计了极具挑战性的跨研究(cross-study)和跨疾病(cross-disease)实验。这些实验模拟了当模型应用于来自不同实验室、不同批次甚至不同疾病背景的数据时的性能表现。
如图2所示,在对包含多个独立研究来源的胰腺数据集进行的跨研究测试中,scKAN表现出卓越的性能。具体而言,模型在预测来自全新研究的细胞时,取得了高达97.42%的准确率和0.734的宏F1分数。相比之下,包括Tosica和scGPT在内的次优模型,其性能分别领先1.01%和2.03%。UMAP可视化结果也直观地证实,scKAN预测的细胞类型分布与真实的细胞类型注释高度一致,显示出强大的跨批次泛化能力。
在难度更高的跨疾病(即跨癌种)测试中,scKAN的优势依然显著。该实验要求模型利用从六种癌症中学习到的知识,去注释来自另外三种全新癌症类型的细胞。尽管任务极具挑战性,scKAN仍然取得了63.84%的准确率和0.373的宏F1分数,分别比次优的scGPT模型高出4.48%和7.44%。混淆矩阵和UMAP可视化均表明,即使在不同疾病背景下,scKAN依然能够准确地区分相关的细胞亚群,并保持细胞类型分布的整体结构。这些结果充分证明了scKAN能够学习到细胞内在的、可跨越实验和疾病差异的生物学模式。
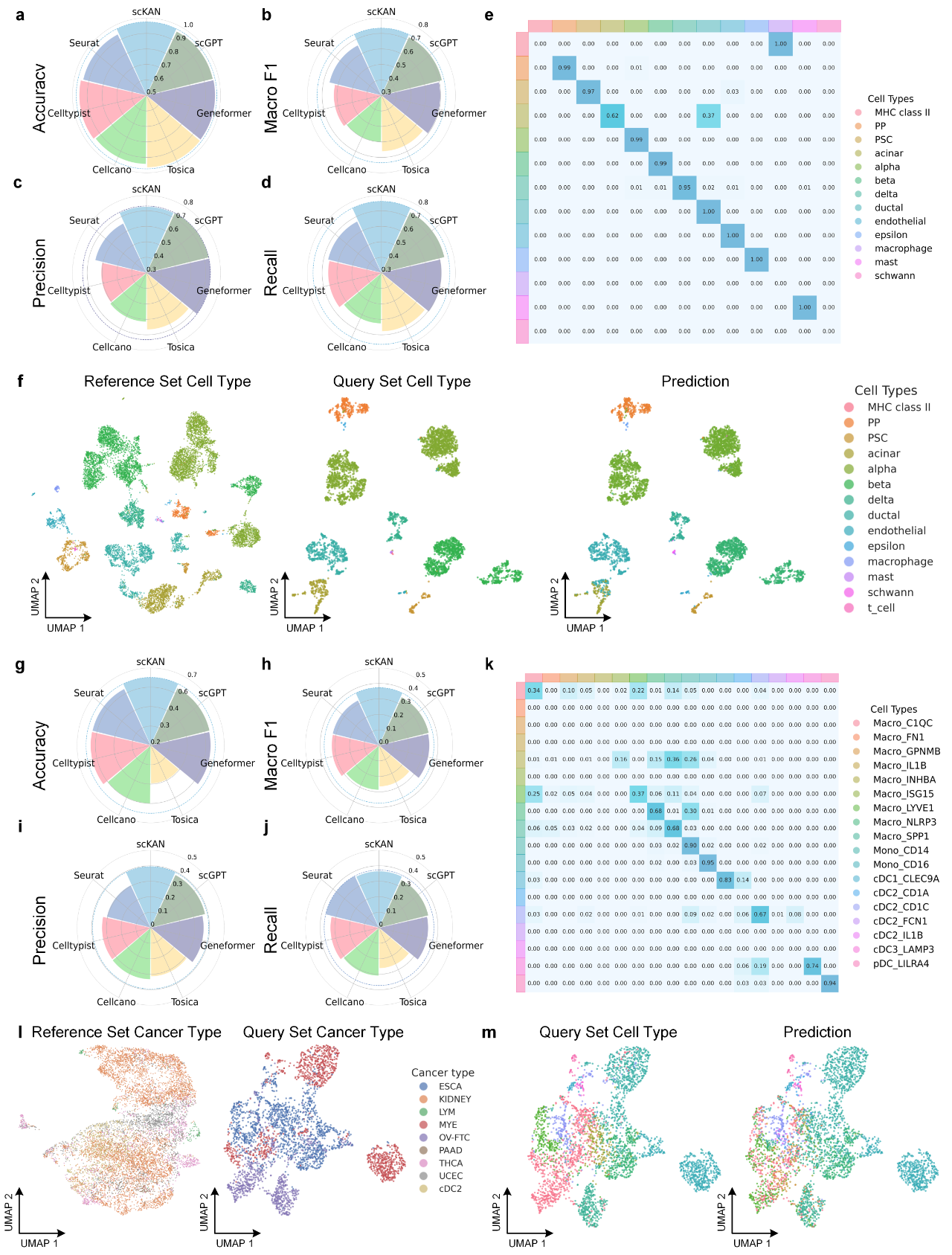
图2: scKAN在跨研究和跨疾病场景下的性能评估结果
scKAN增强细胞特异性基因集和通路发现能力
scKAN最引人注目的优势之一是其基于可解释激活曲线来发现生物学功能基因集的能力。模型为每个基因学习到的“激活曲线”描绘了其在不同细胞类型中的表达模式,相似的曲线模式往往意味着这些基因在功能上协同作用。
如图3所示,研究团队在PBMC免疫细胞数据集中,通过对scKAN学习到的激活曲线进行层次聚类,成功识别出多个功能高度一致的基因程序(gene programs)。例如,模型准确地将编码CD8受体复合物的CD8A和CD8B基因,与T细胞关键效应分子GZMA以及激活受体KLRK1等聚类在一起,形成了一个高度相关的T细胞功能基因集。同样,模型也识别出了一个由病原识别受体TLR2和炎症核心调控因子TNFAIP3等基因组成的炎症相关基因集,这些基因的激活曲线相似度得分均超过0.88,证明了聚类的可靠性。
为了量化这一能力,研究团队将scKAN与SOTA模型scGPT进行了正面比较。结果显示,在所有测试条件下,scKAN识别出的功能富集通路数量均显著多于scGPT。这一优势源于scKAN的架构能够捕捉到更加精细和上下文相关的基因共表达模式,而这些微妙的信号在scGPT的全局嵌入中可能会被平均化或掩盖。这种更高分辨率的通路发现能力,对于深入剖析特定细胞状态下的精细调控网络、并产生更精确的、可供验证的生物学假设至关重要。
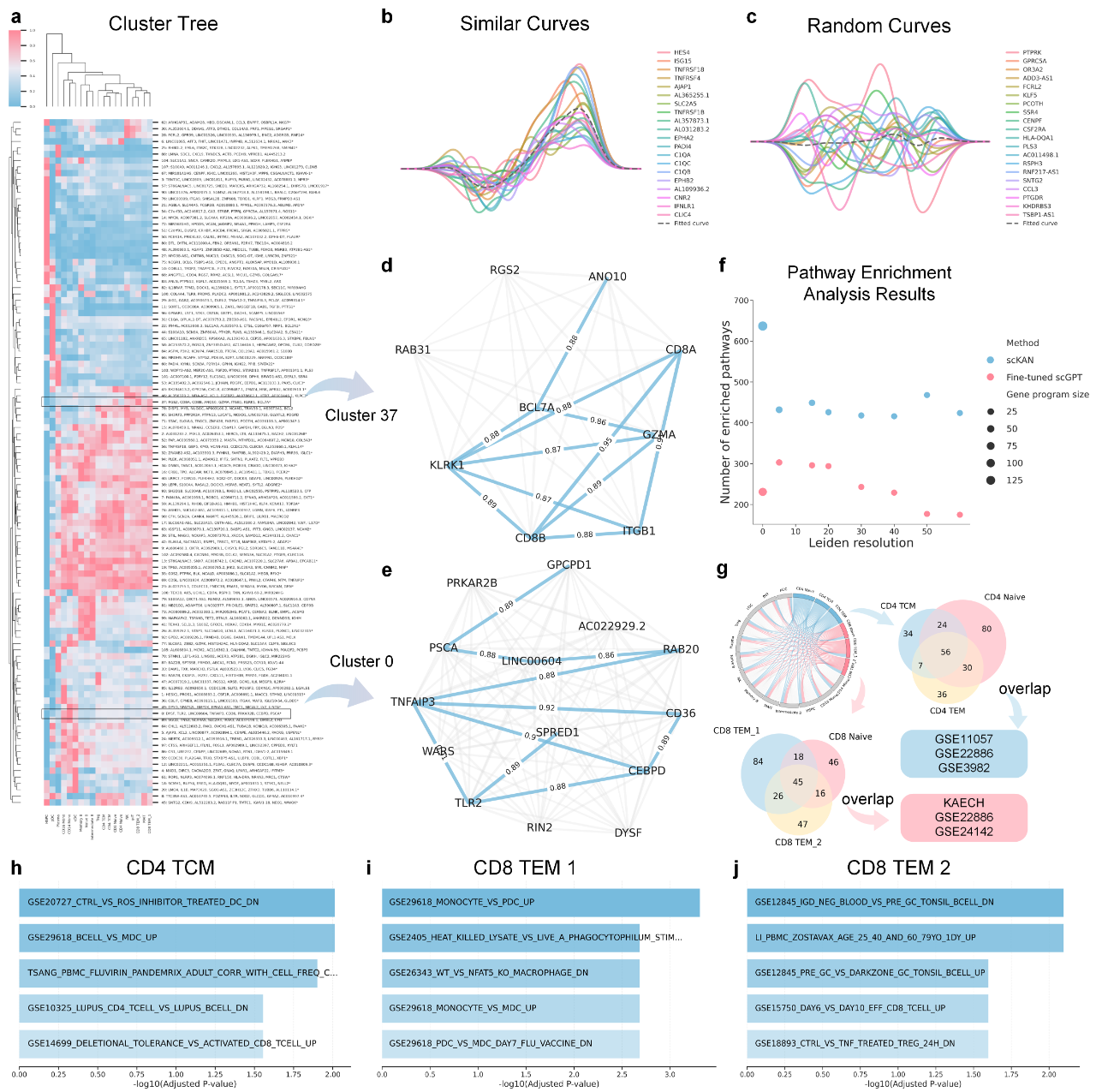
图3: scKAN的基因集识别和通路分析能力
scKAN发现可靠的细胞特异性标志基因
准确识别细胞类型的标志基因是单细胞分析的核心任务,也是理解细胞身份和功能的基础。scKAN利用其独特的“重要性分数”归因机制,为这一任务提供了全新的、更具深度的解决方案。
如图4所示,在PBMC数据集中,scKAN为19种免疫细胞识别出的前20个高分基因展现出清晰的细胞特异性表达模式。火山图分析证实,这些基因大多是统计上显著的差异表达基因。更重要的是,在与SOTA模型scGPT的基准比较中,无论是在20-shot、10-shot还是5-shot的少样本设定下,scKAN识别出的标志基因集合中,包含的真实差异表达基因的比例在绝大多数细胞类型上都显著更高。
通过生物学文献验证,大量由scKAN发现的高分基因被证实是已知的细胞标志物,例如B细胞发育的关键调控因子SEL1L3、NK细胞细胞毒性功能相关的CST7以及CD8+初T细胞稳态所必需的BACH2,这有力地证明了模型预测的生物学相关性。一个尤为关键的发现是,scKAN的重要性分数与基因的表达倍数变化(log2-fold change)虽然存在正相关,但模型同样能为许多表达变化不明显、但功能上至关重要的基因赋予高分。这一能力突破了传统差异表达分析仅关注“高表达”基因的局限,为发现新的细胞身份决定因子和药物靶点开辟了新的道路。
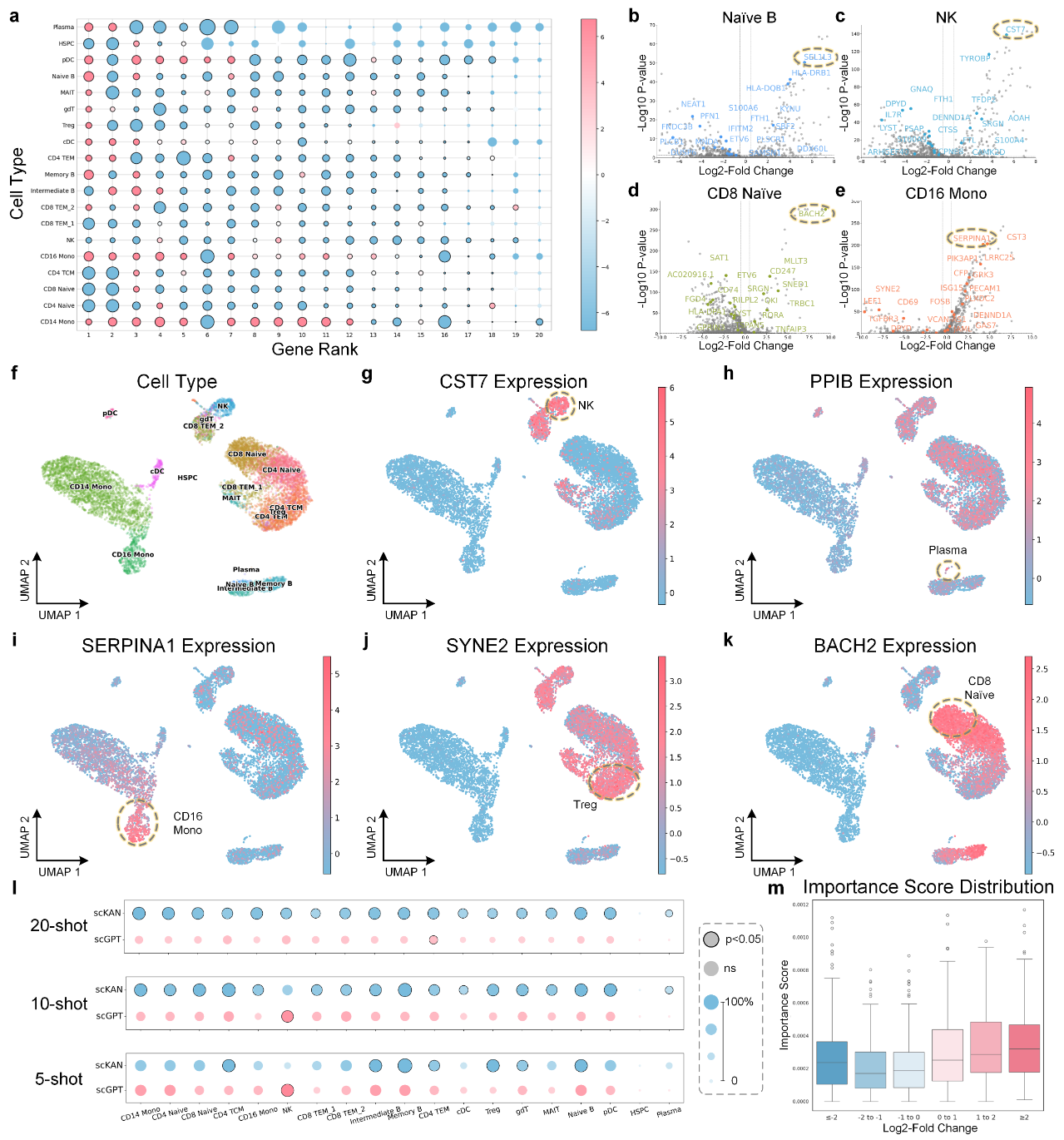
图4: scKAN的标志基因识别与验证结果
胰腺癌案例研究验证了scKAN的实用价值
为了将scKAN的分析能力转化为切实的临床应用价值,研究团队以致死率极高、治疗方案极为有限的胰腺导管腺癌(PDAC)为例,进行了一项系统的药物重定位研究。
如图5所示,研究的第一步是利用在胰腺数据集上训练好的scKAN模型,识别出PDAC中导管细胞的特异性标志基因。令人振奋的是,在前20个候选基因中,有12个已被文献证实与胰腺癌相关。随后,团队通过分析这些基因的激活曲线相似性,锁定了一个由FAP、LGALS3、MTHFD2等9个基因组成的功能核心基因集,并将其确定为潜在的药物靶点组合。
接下来,团队利用先进的药物-靶点亲和力(DTA)预测模型,对2509种FDA批准的药物进行了大规模虚拟筛选。筛选结果最终将Doconexent和Sulindac确定为综合评分最高的两个候选药物。值得注意的是,这两种药物均已有文献报道其在胰腺癌治疗中的潜力,这从侧面验证了scKAN预测的准确性和可靠性。为了进一步提供理论支持,团队对评分最高的Doconexent进行了分子对接和长达100纳秒的分子动力学(MD)模拟。结果显示,Doconexent能够与FAP、LGALS3等多个靶点蛋白形成高度稳定的结合构象,为其作为PDAC潜在治疗药物提供了坚实的理论基础。这项案例研究完整地展示了scKAN如何从单细胞数据分析出发,通过可解释的基因发现,最终筛选出具有临床转化潜力的候选药物,成功搭建了从基础研究到药物发现的桥梁。
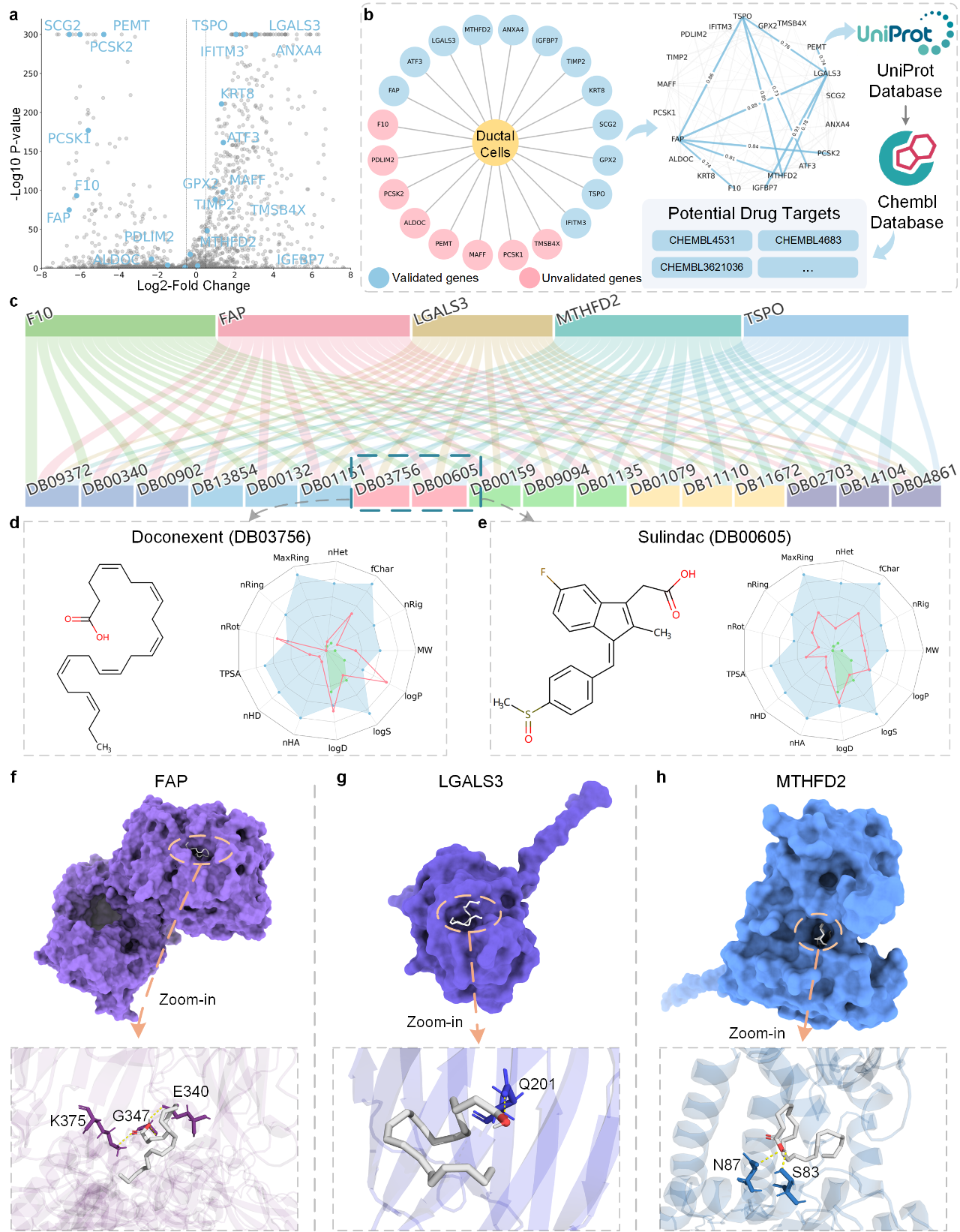
图5: scKAN在胰腺癌药物重定位案例中的分析结果
总结
在这项研究中,作者介绍了一种创新的、可解释的单细胞分析框架scKAN。通过巧妙地整合知识蒸馏与科尔莫戈罗夫-阿诺德网络,scKAN成功地在模型性能、计算效率和生物学可解释性之间取得了卓越的平衡。
该研究工作在多个方面做出了重要贡献:
· 提出了一种高效的知识蒸馏框架,在大幅降低计算资源消耗的同时,实现了超越现有SOTA模型的细胞注释精度。
· 创新性地应用了KAN网络进行可解释性建模,通过学习激活曲线和计算重要性分数,为发现细胞特异性的功能基因集和标志基因提供了强大的新工具。
· 通过详尽的胰腺癌案例研究,验证了模型在转化医学中的巨大应用价值,展示了从单细胞洞见到药物重定位的完整工作流。
展望未来,scKAN的框架不仅为单细胞分析领域提供了强大的新工具,其设计理念也有望扩展到更复杂的生物学任务,如扰动响应预测和多模态数据整合。随着这项技术的不断完善和应用场景的拓展,我们有望见证其在精准医疗和药物研发的多个环节中发挥关键作用,为攻克复杂疾病带来新的希望。
参考资料
He, H., Tang, Z., Chen, G. et al. scKAN: interpretable single-cell analysis for cell-type-specific gene discovery and drug repurposing via Kolmogorov-Arnold networks. Genome Biol 26, 300 (2025). https://doi.org/10.1186/s13059-025-03779-0
代码地址:https://github.com/hehh77/scKAN
文章改编转载自微信公众号:DrugAI
原文链接:https://mp.weixin.qq.com/s/eH1mVdKO5dB9HSPBGbdDlw?scene=1 | 





















