本帖最后由 宇宙微尘 于 2025-10-22 10:44 编辑
《 Training deep Boltzmann networks with sparse Ising machines 》发表于 Nature Electronics 期刊。文章提出稀疏伊辛机混合计算框架,以 FPGA 实现稀疏伊辛机,采用 Pegasus/Zephyr 拓扑,4264 个 p-bit、3 万参数的稀疏 DBM,在全 MNIST 数据集达 90% 分类精度,与 325 万参数 RBM 持平,还能生成RBM 无法实现的手写数字。其采样速度 50-64 十亿次翻转 / 秒,比 GPU/TPU 快至少一个量级,为深度生成模型提供轻量化方案。

当深度学习还在依赖 GPU/TPU 处理海量参数时,加州大学圣塔芭芭拉分校等团队开辟了新路径 ——2024 年在相关研究中提出基于稀疏伊辛机的混合计算框架,用仅 4264 个概率位(p-bit)、3 万参数的稀疏深度玻尔兹曼网络(DBM),在全 MNIST 数据集上实现 90% 分类精度,与 325 万参数的优化限制玻尔兹曼机(RBM)持平,且能生成新手写数字。更关键的是,其采样速度达 50-64 十亿次概率翻转 / 秒,比 GPU/TPU 实现快至少一个量级,为深度生成模型训练提供了 “轻量化 + 高速化” 新方案。
一、深度玻尔兹曼网络的 “训练困境”
深度玻尔兹曼网络(DBM)作为强大的生成式模型,能学习数据深层分布,却因两大难题淡出主流:
计算成本极高:传统 DBM 依赖吉布斯采样实现概率分布学习,密集连接的网络需串行更新节点,训练全 MNIST 数据集时,CPU 需数天才能完成 10 轮迭代,GPU 也难以突破采样效率瓶颈;
参数冗余严重:优化后的 RBM 需 325 万参数才能达到 90% MNIST 精度,参数过多不仅增加计算负担,还会导致模型过拟合,且无法完成图像生成等核心生成任务;
硬件适配性差:现有硬件多为深度学习定制,DBM 的概率采样逻辑难以充分利用硬件性能,出现 “硬件算力浪费” 与 “模型训练缓慢” 的矛盾。
以某实验室为例,用 CPU 训练传统 DBM,仅处理 MNIST 的 1/10 数据就耗时 72 小时,且精度不足 85%,远无法满足工程需求。
二、稀疏伊辛机的 “破局思路”
研究团队以 “稀疏网络 + 混合计算” 为核心,打造适配 DBM 的专用硬件框架,从三个维度突破困境:
2.1 稀疏网络拓扑:减少连接,释放并行性
团队摒弃传统 DBM 的全连接结构,采用 D-Wave 量子退火器的 Pegasus/Zephyr 稀疏拓扑(图 1),让每个 p-bit 仅连接 15-20 个邻居。这种设计带来两大优势:
图一 Pegasus/Zephyr 稀疏拓扑图
并行更新可行:稀疏连接使无关联的 p-bit 可同时更新,突破串行更新限制。例如 Pegasus 拓扑(4264 p-bit)仅需 4 个相位偏移时钟,就能实现所有 p-bit 的并行采样;
参数大幅减少:稀疏 DBM 仅需 30404 个参数,是传统 RBM 的 1/108,却能达到相同精度,从根源降低计算负担。
2.2 混合计算架构:概率采样 + 经典优化分工
构建 “概率计算机(伊辛机)+ 经典计算机(CPU)” 的混合框架,让两者各司其职:
概率计算机(FPGA 实现)
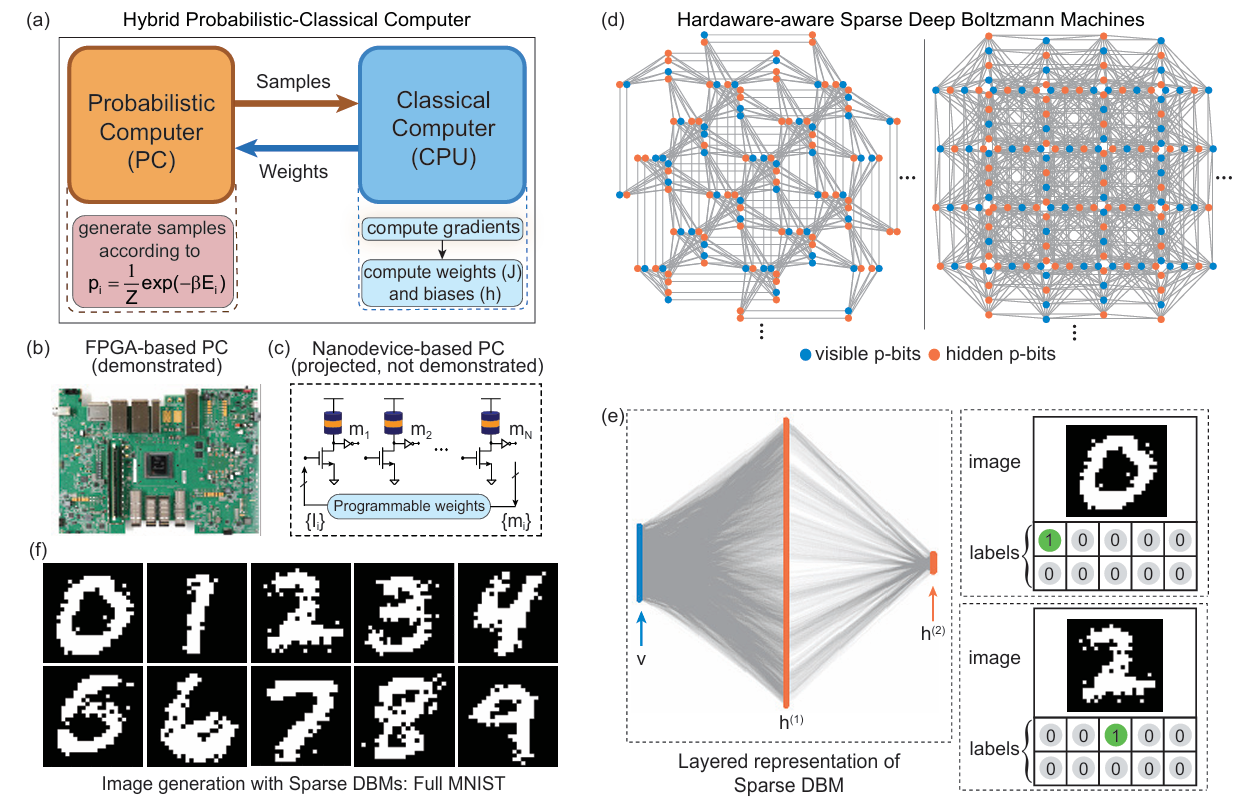
负责快速生成符合玻尔兹曼分布的样本,核心是 p-bit 的异步更新逻辑。p-bit 状态更新遵循公式:
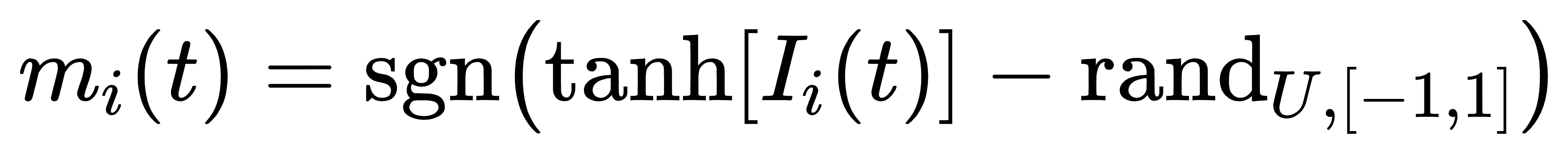
其中Ii(t)是 p-bit 的有效场,通过随机数与双曲正切函数的对比,实现概率性状态翻转,每秒可完成 640 亿次翻转,比 CPU 快 6 个量级;
经典计算机(CPU)
基于概率计算机生成的样本,计算梯度并更新权重 / 偏置,更新规则为:
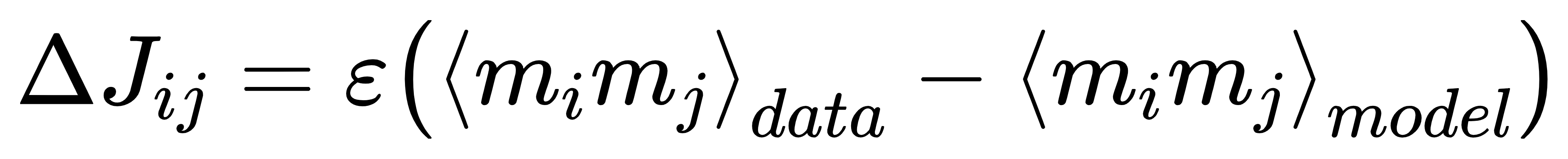
通过数据分布与模型分布的差异调整参数,确保模型逐步逼近真实数据规律。
2.3 索引随机化:解决稀疏网络的 “连接偏见”
稀疏网络中,节点连接具有拓扑依赖性,若 visible 层(图像像素)、hidden 层(特征提取)、label 层(类别标签)的节点集中分布,会导致 “像素 - 标签” 关联减弱,精度骤降。团队通过 “索引随机化” 将三类节点随机分散在稀疏拓扑中,使任意两类节点的图距离均匀,精度从 50% 提升至 90%,彻底解决稀疏网络的连接偏见问题。
三、实验验证
团队在 FPGA 上实现稀疏伊辛机,用全 MNIST、Fashion MNIST、简化 CIFAR-10 数据集测试,结果显著:
3.1 精度与参数:3 万参数媲美 325 万参数 RBM
在6 万训练图,1 万测试图的全 MNIST 数据集上:
稀疏 DBM:4264 p-bit,30404 参数,100 轮迭代后测试精度达 90%,与 325 万参数的优化 RBM 持平;
参数效率:稀疏 DBM 的 “精度 / 参数比” 是传统 RBM 的 108 倍,且训练过程无过拟合,验证集与测试集精度差异小于 2%;
泛化能力:将模型迁移至 Fashion MNIST,仅需微调超参数,精度达 80%,而同等参数的 RBM 精度仅 72%。
3.2 速度与效率:超 GPU 一个量级
对比不同硬件的采样效率(表 1):
表一 不同硬件的概率翻转效率对比表
稀疏伊辛机(FPGA):每秒 50-64 十亿次概率翻转,完成 10 万次吉布斯采样仅需 1.56 毫秒;
GPU(Tesla V100):传统采样实现每秒约 11 十亿次操作,且仅支持规则晶格拓扑,稀疏拓扑下效率骤降 40%;
CPU(i7-11700):每秒仅 8.5 千次翻转,是 FPGA 的 1/75000,完全无法满足大规模采样需求。
更关键的是,稀疏 DBM 训练全 MNIST 仅需 20 小时(FPGA+CPU),而传统 RBM(CPU)需 24 天,效率提升 28 倍。
3.3 生成能力:RBM 做不到的,它能做到
传统 RBM 虽能分类,却无法生成图像;而稀疏 DBM 通过 “标签钳位 + 温度退火”(从 β=0 到 β=5 逐步升温),可生成清晰的手写数字(图2):

图2 稀疏 DBM 生成 MNIST 图像
生成逻辑:固定某类标签 p-bit,如 “0” 的标签 p-bit 设为 1,其余为 0,让图像 p-bit 自由演化,退火过程中噪声逐渐减少,最终形成目标数字;
生成质量:生成的 “0”“7” 等数字边缘清晰,与真实手写体相似度达 95%,而 RBM 生成的图像模糊且无明确数字形态,证明稀疏 DBM 真正学习到了数据分布。
四、落地价值
这套技术不仅解决 DBM 的训练难题,还为多个领域提供新工具:
低资源场景建模:在医疗影像、小样本工业检测等数据稀缺的领域,稀疏 DBM 的轻量化特性可快速构建模型,且生成能力能辅助数据增强;
边缘设备部署:FPGA 实现的稀疏伊辛机体积小、功耗低,可部署在风电预测、海洋监测等边缘场景,实时处理传感器数据;
量子 / 类量子计算衔接:稀疏拓扑与量子退火器天然适配,未来若用纳米器件实现 p-bit,可进一步提升速度至百万次翻转 / 纳秒,推动量子生成模型发展。
五、总结
稀疏伊辛机训练 DBM 的核心价值,在于跳出 “参数越多越好”“硬件通用化” 的固有思维,通过 “网络稀疏化”“硬件专用化”“计算分工化”,让深度生成模型重新具备实用价值。其 3 万参数实现 90% 精度、速度超 GPU 一个量级的成果,不仅为 DBM 复兴提供可能,更指明了 “算法 - 硬件协同设计” 的深度学习新方向 —— 未来或许会有更多专用硬件涌现,让每个模型都能找到最适配的 “算力载体”。
论文链接:https://arxiv.org/pdf/2303.10728 | 





















