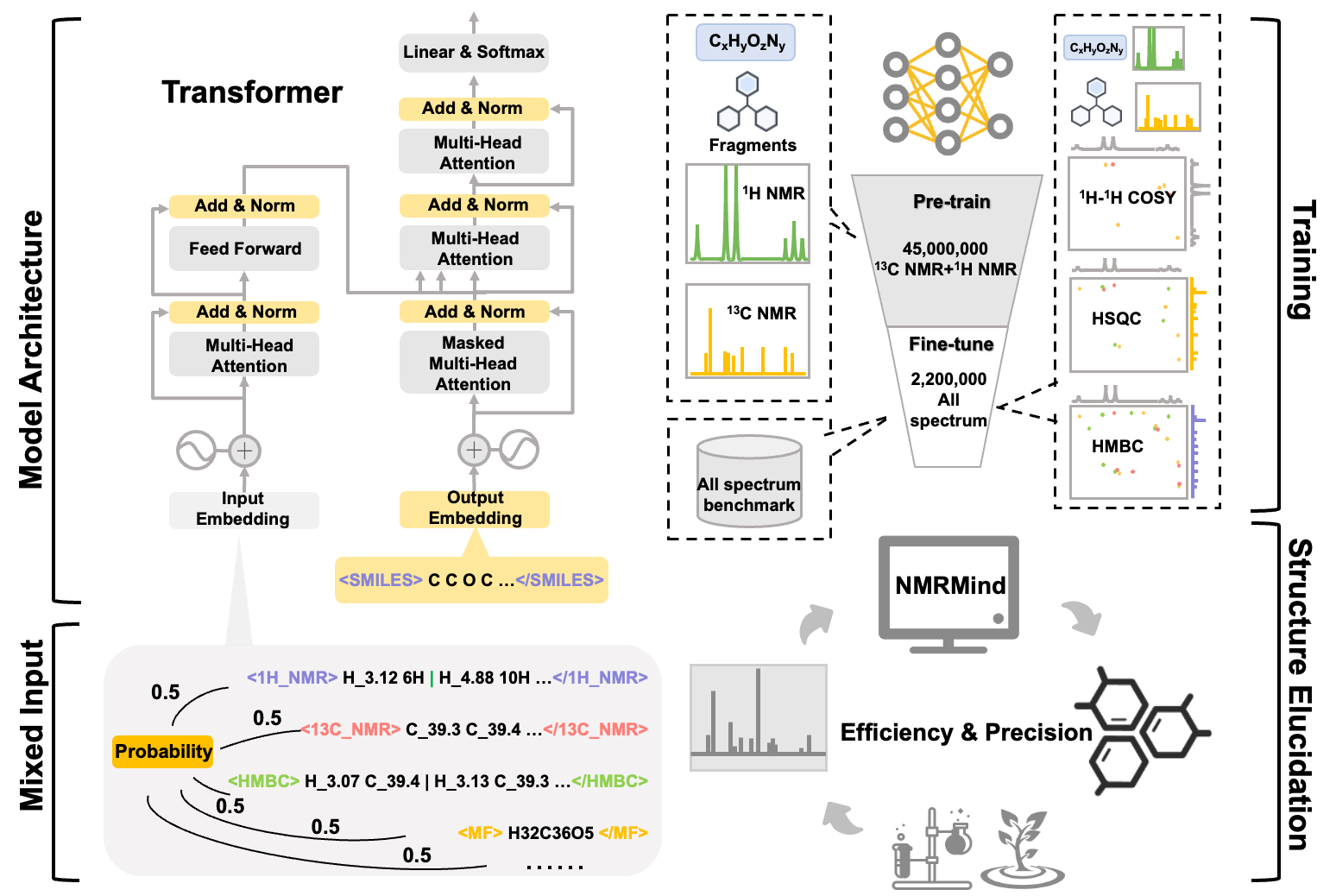
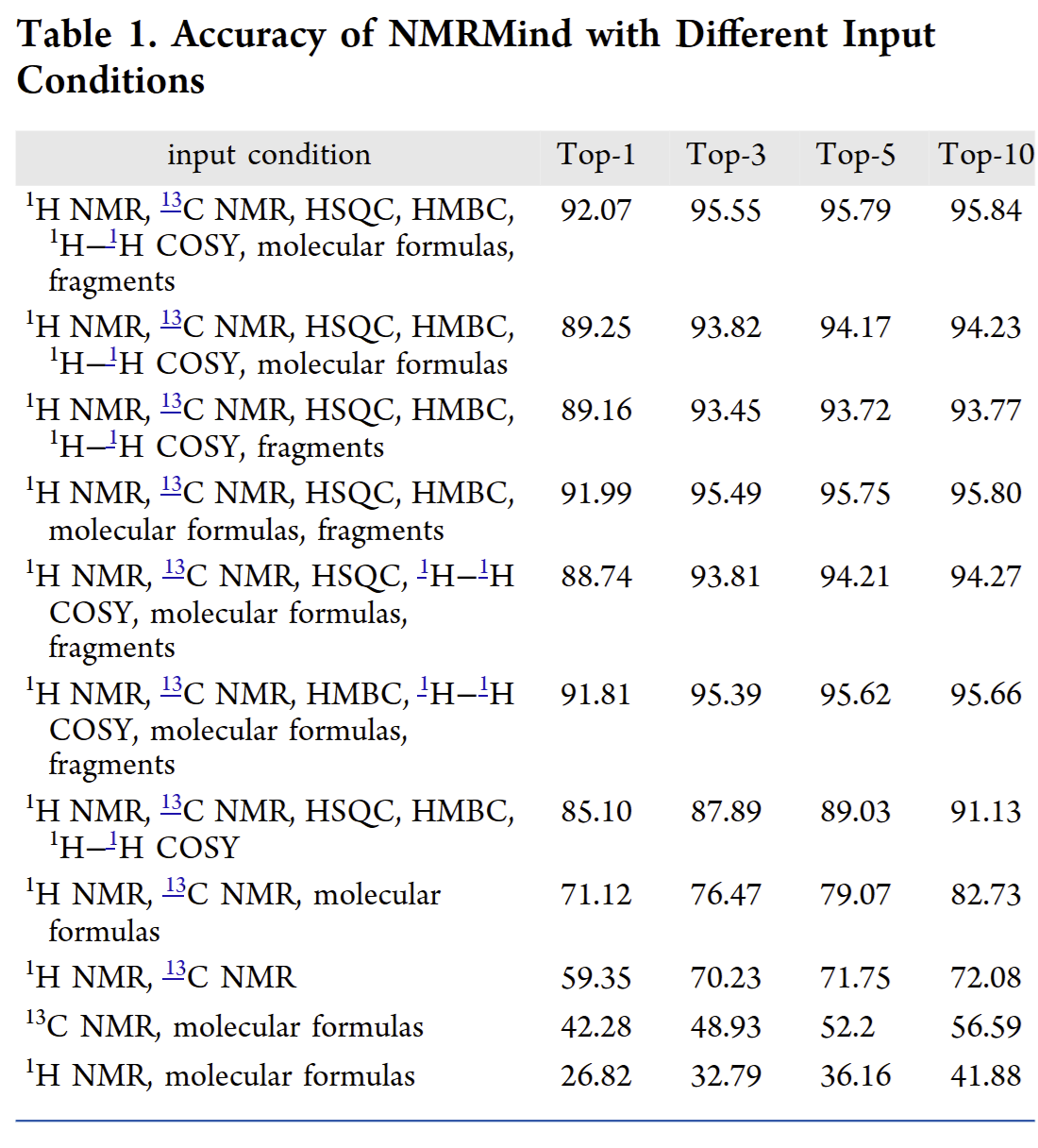
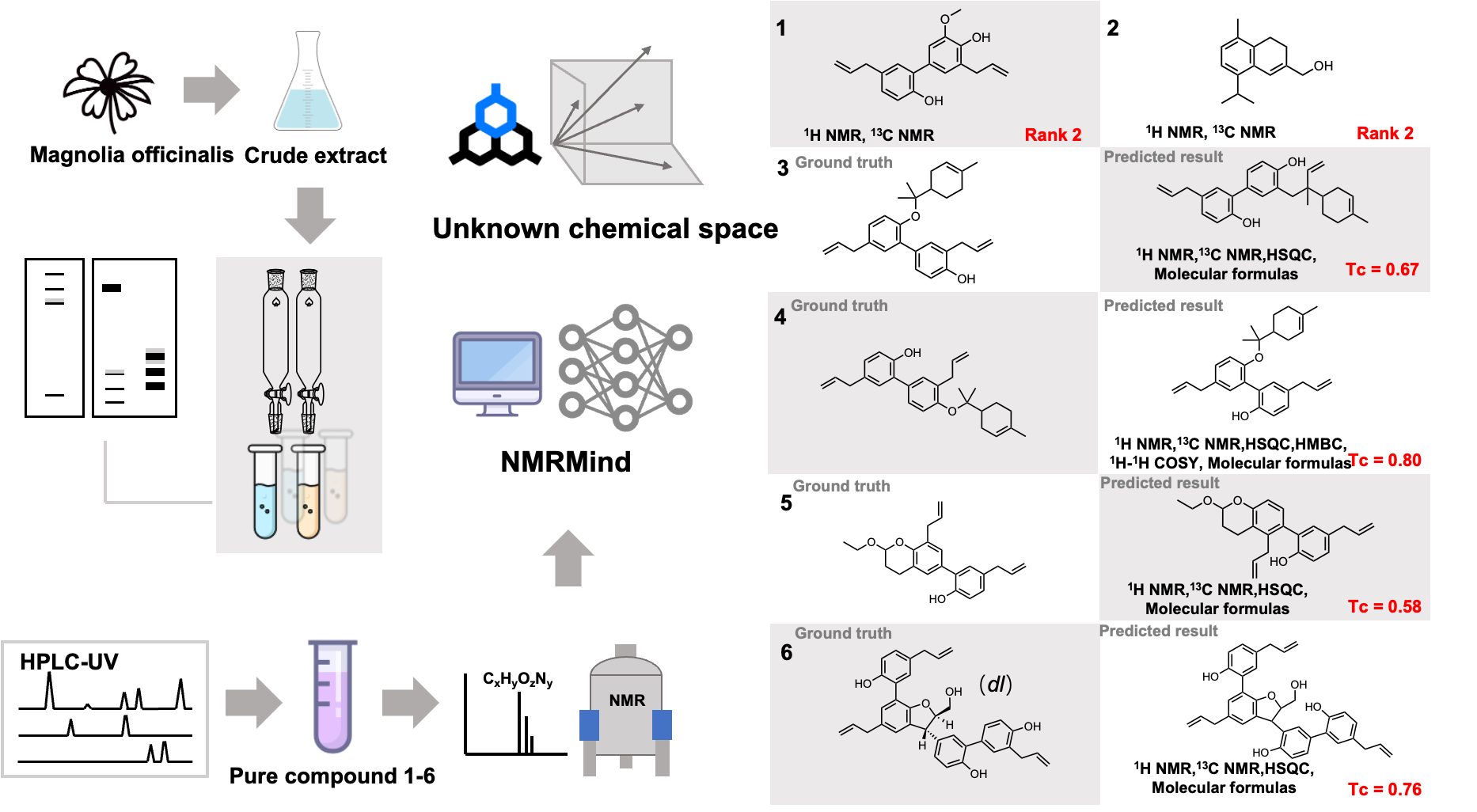
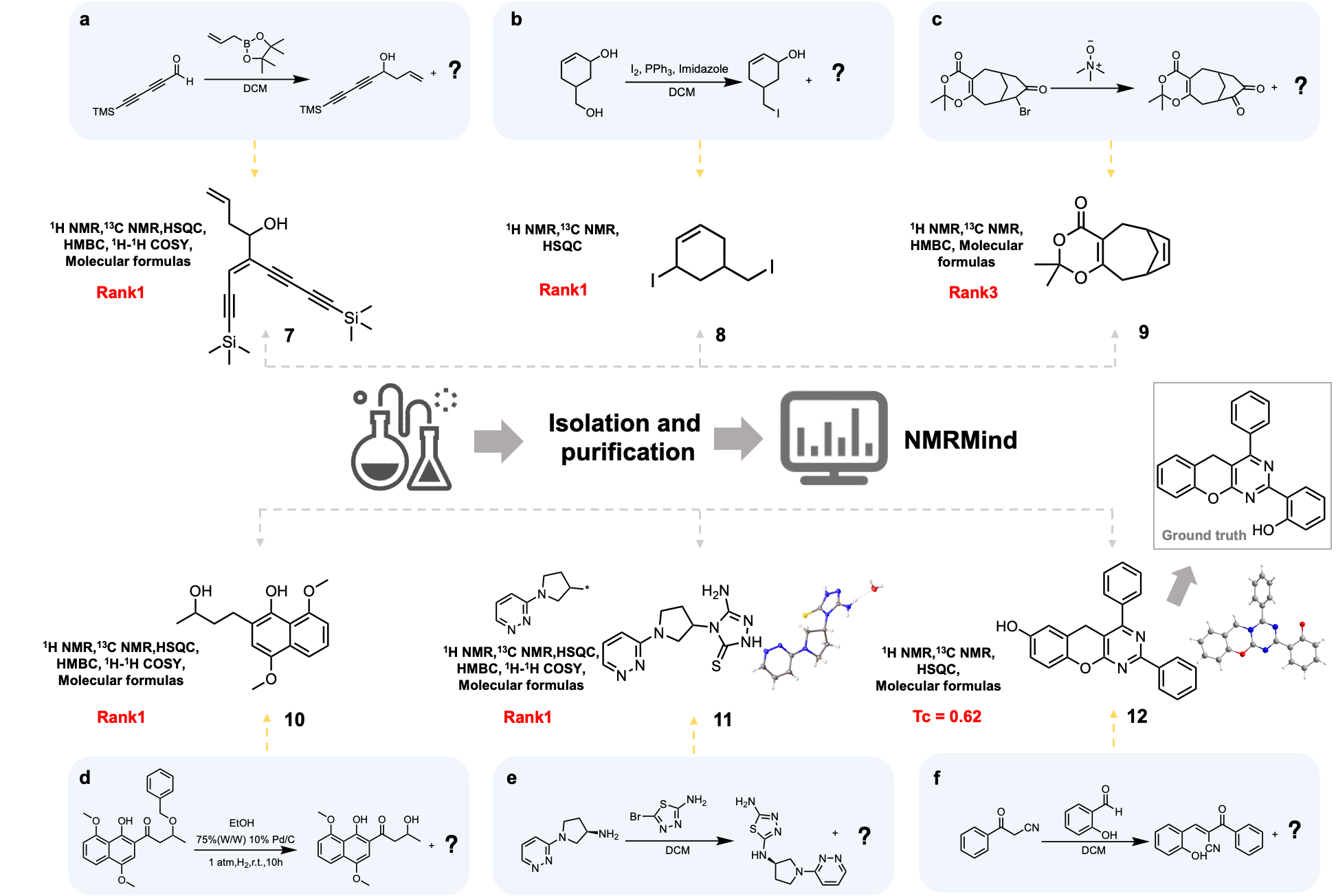
NMRMind:AI驱动的多维NMR谱图到分子结构的精准解析 |
|
Akkio
2025-11-13 17:39:50
生命科学
算法解析
1063
0
0
0
| |

Copyright 2021-2026 开物量子开发者社区 版权所有 All Rights Reserved. 相关侵权、举报、投诉及建议等,请发E-mail: business@boseq.com



完成任务,轻松获取真机配额
×


提交成功
真机配额已发放到您的账户,可前往【云平台】查看



考核目标

通过奖励

开发者权益


第二步

第三步
*
开发者权益
恭喜您完成考核
您将获得量子AI开发者认证标识及考核奖励
1000 bit*5
配额
Assessment Objectives
Pass Rewards
Developer Benefits
Step 1

Step 2
Step 3
*
Developer Benefits
Congratulations on Completing the Assessment
You will receive the Quantum AI Developer Certification Badge and Assessment Rewards
550bit*10
Quotas