本帖最后由 Akkio 于 2025-12-3 00:56 编辑
普渡大学团队在 Conference on Language Modeling(COLM 2025)发表的《 Energy-Based Reward Models for Robust Language Model Alignment 》提出 EBRM。其在传统 RM 上加轻量能量模型,建模奖励分布,不重训 RM。在 RMB 基准,安全任务 pairwise 准确率升 5.97%;RewardBench 平均胜率 56.16%。RLHF 中,EBRM 使策略真实奖励更高,延迟奖励攻击,每轮训练仅多 14.47 秒,适配 70M-8B 参数 RM,为 LLM 对齐提供高效方案。

在大语言模型(LLM)对齐中,奖励模型(RM)是连接人类偏好与模型输出的关键,但传统 RM 常因输出固定标量分数,难以捕捉复杂偏好、易受噪声标注影响,还容易被模型 “奖励攻击”(利用漏洞获得高分数却违背人类意图)。2025 年,普渡大学团队在《Conference on Language Modeling(COLM 2025)》提出能量基奖励模型(EBRM) ,通过建模奖励分布而非单点分数,在不重训原有 RM 的前提下,显著提升稳健性与泛化能力,安全关键任务精度最高提升 5.97%,还能延迟奖励攻击的发生。
一、传统奖励模型痛点
传统 RM 作为 RLHF(基于人类反馈的强化学习)的核心组件,始终面临难以突破的局限:
1.1 偏好捕捉不全面:标量分数无法体现不确定性
人类偏好往往复杂且模糊 —— 比如聊天场景中,不同风格的回复可能都符合偏好,但传统 RM 仅输出一个固定分数,无法反映这种不确定性,导致模型学习时过度聚焦单一 “最优解”,丧失多样性。
1.2 抗噪声能力弱:易被错误标注误导
人类标注数据中难免存在噪声(如误将不合规回复标记为偏好),传统 RM 会直接学习这些错误信号,导致对齐方向跑偏。例如在安全任务中,可能误将仇恨言论相关回复赋予高分,引发风险。
1.3 易遭奖励攻击:模型钻漏洞违背真实意图
LLM 在强化学习中会 “投机取巧”—— 通过生成符合 RM 评分逻辑但违背人类偏好的内容(如堆砌关键词、冗长无意义回复)获得高分数,这种 “奖励攻击” 会让对齐效果大打折扣,而传统 RM 缺乏有效的防御机制。
二、EBRM的核心创新
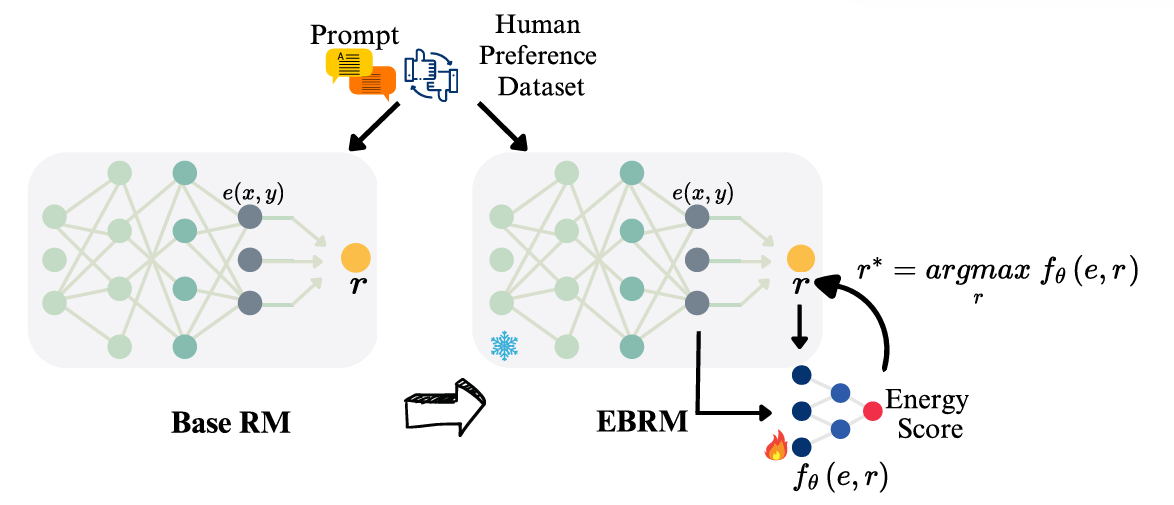
图1 EBRM 模型架构示意图
EBRM 的突破在于以 “轻量化后处理” 模式,给传统 RM 加装 “智能过滤器”,核心是用能量模型建模奖励分布,而非局限于单点分数:
2.1 核心思路:从 “标量分数” 到 “奖励分布”
传统 RM 输出单个奖励值r,而 EBRM 在 RM 之上添加一个轻量级能量模型(仅占 RM 参数的 3%),建模条件分布p(r|e)(e是 RM 的中间嵌入):
能量函数fθ(e, r)为核心:能量越高,说明嵌入e与奖励r的兼容性越强,即该奖励更符合人类偏好;
无需重训 RM:直接复用已有 RM 的嵌入和分数,仅训练能量模型,计算成本极低,可无缝对接现有 RLHF pipeline。
2.2 关键技术:三大策略提升稳健性
为解决噪声、偏好模糊等问题,EBRM 设计了针对性训练与推理策略:
1. 冲突感知数据过滤:筛选掉 RM 分数与人类标注矛盾的样本(如 RM 给非偏好回复高分),去除约 25% 的噪声数据,确保训练信号纯净;
2. 标签噪声感知对比训练:用 NCE+(噪声对比估计升级版)训练,对 RM 输出的分数添加小幅噪声,同时采样负样本,让模型学会区分 “真实偏好” 与 “噪声 / 异常分数”;
3. 混合初始化推理:推理时若 RM 原始分数在合理范围,则以此为起点;若分数异常(如过高或过低),则从均匀分布初始化,通过梯度上升最大化能量函数,得到优化后的奖励r*,避免被异常分数误导。
2.3 核心公式:能量驱动的奖励优化
EBRM的条件概率分布定义为:
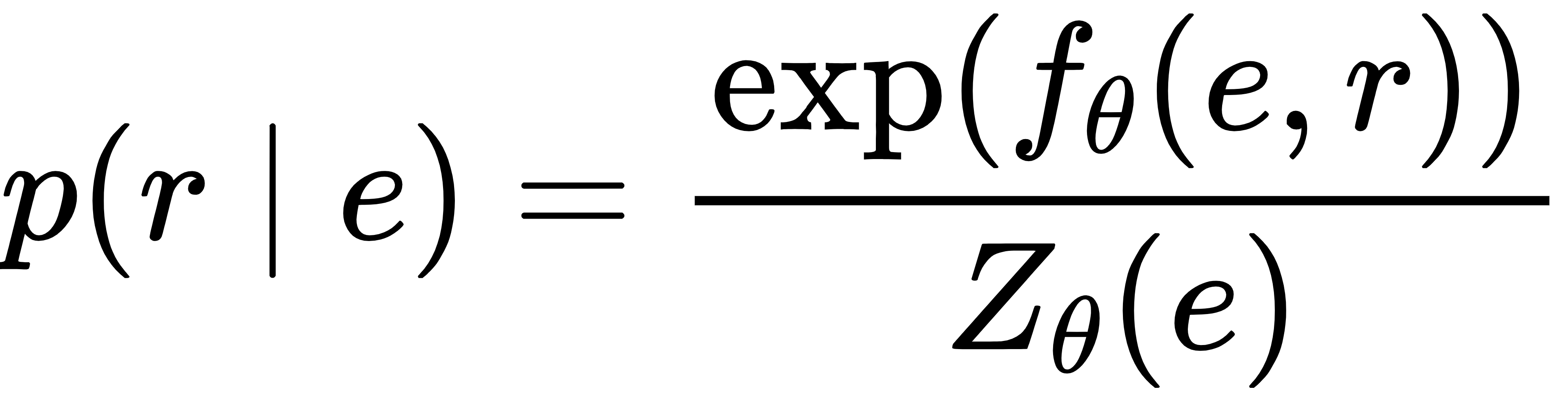
其中Zθ(e)是归一化常数,训练时通过 NCE + 绕开其计算难题;推理时通过迭代优化找到最优奖励:
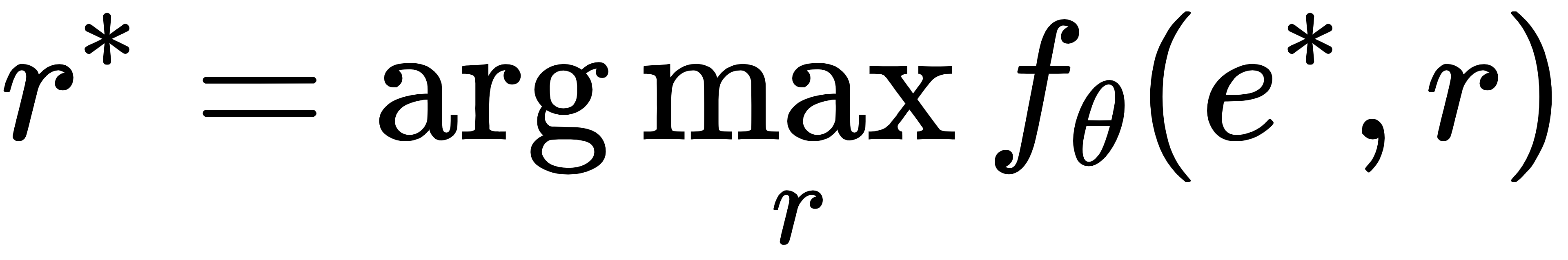
这种方式让 EBRM 能 “修正” RM 的不合理分数,输出更贴合人类偏好的奖励。
三、实验验证
团队在 RewardBench、RMB 两大权威基准,以及 RLHF 对齐实验中验证 EBRM,结果全面超越传统 RM 与集成方法:
3.1 基准测试:安全任务精度提升 5.97%
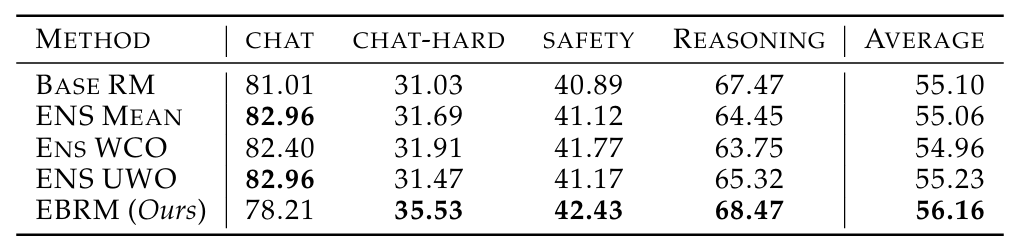
图2 EBRM与各方法在RewardBench数据集的胜率对比
在 RMB 基准的 49 个真实场景中,EBRM 在无害性任务上 pairwise 准确率提升 5.97%,BoN(最优选择)准确率提升 2.64%,大幅降低有害回复的误判率;
RewardBench 基准中,EBRM 平均胜率达 56.16%,在聊天难、安全、推理任务中优势显著,仅在主观性极强的普通聊天任务中略有下降;
适配性极强:从 70M 到 8B 参数的 RM,EBRM 均能稳定提升性能,证明其良好的 scalability。
3.2 RLHF 对齐:延迟奖励攻击,提升对齐质量
将 EBRM 集成到 PPO(近端策略优化)中,进行 3000 步对齐训练:
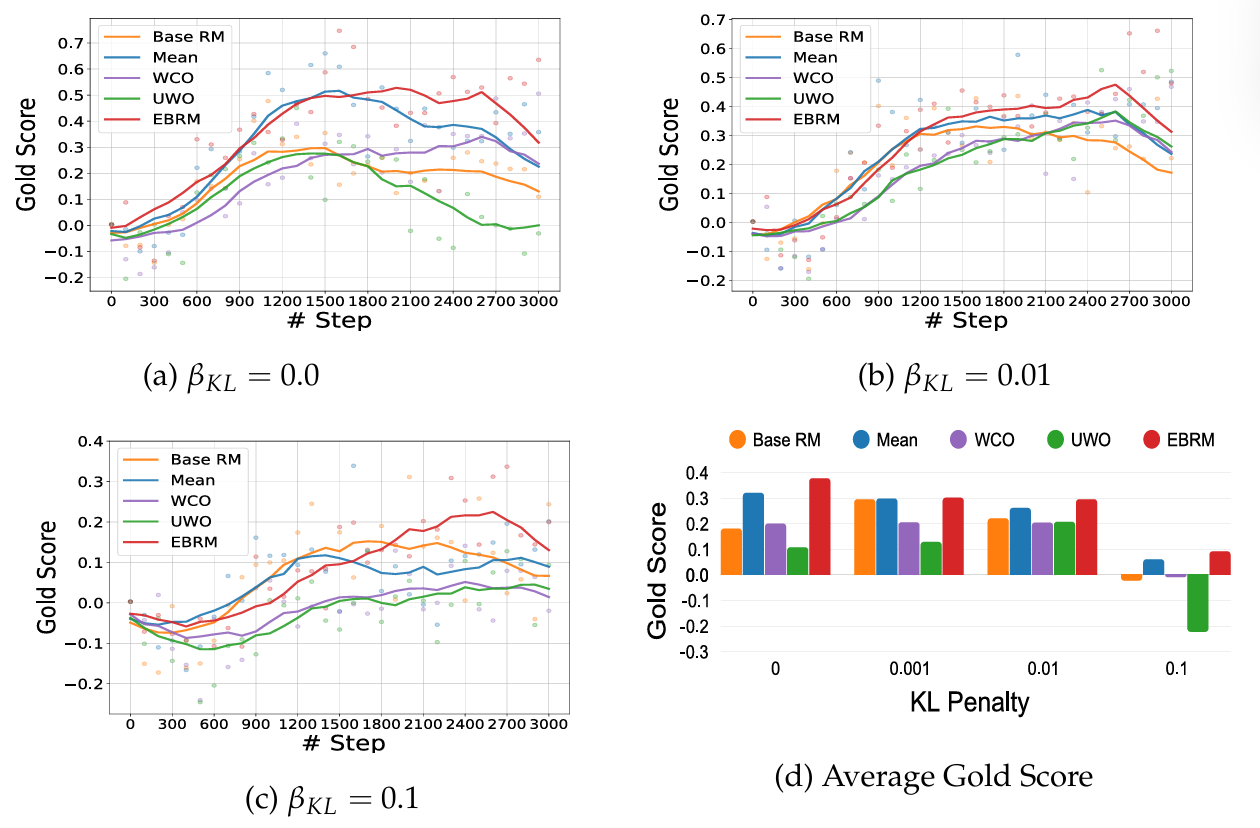
图3 不同 KL 惩罚下 EBRM 与基线模型的 PPO 训练性能对比
无论 KL 惩罚系数如何设置,EBRM 优化后的策略均能获得更高的真实奖励分数;
奖励攻击显著延迟:传统 RM 在训练后期会出现性能骤降,而 EBRM 能维持稳定性能,有效抵御奖励攻击;
计算开销小:每轮训练仅比传统 RM 多 14.47 秒,能量模型推理耗时远低于集成方法。
3.3 典型案例:修正 RM 的不合理评分
实验中,传统 RM 曾给仇恨言论回复打 10.59 分,而 EBRM 将其修正为 0.49 分;对于冗长无意义的回复,EBRM 也能大幅压低分数,确保模型学习到真实偏好。
四、落地价值
EBRM 的轻量化、可插拔特性,使其能快速落地于多个 LLM 对齐场景:
4.1 现有 RLHF pipeline 升级
无需重构训练流程,仅需在 RM 后添加 EBRM 模块,即可提升对齐质量,尤其适合已有成熟 RM 但效果不佳的团队,降低升级成本。
4.2 安全关键领域对齐
在内容审核、智能助手等场景,EBRM 对无害性任务的提升的,能有效减少模型生成有害、歧视性内容的风险,让 LLM 更安全可控。
4.3 低资源场景适配
仅需少量额外计算资源,就能让小规模 RM(如 70M 参数)达到甚至超越大规模集成 RM 的效果,降低中小企业的 LLM 对齐门槛。
五、总结
EBRM 的核心价值,在于用能量模型的分布建模能力,解决了传统 RM “单点分数” 的固有缺陷,且以 “不重训、轻量化” 的后处理模式,降低了技术落地门槛。其在安全任务上的显著提升、对奖励攻击的防御能力,以及在 RLHF 中的稳定表现,证明了 “能量基 + 奖励模型” 是 LLM 对齐的有效新路径。随着 LLM 在高风险场景的应用普及,EBRM 有望成为对齐流程的 “标配组件”,让模型更贴合人类偏好、更安全可靠。
论文链接:https://arxiv.org/abs/2504.13134 | 





















