本帖最后由 离子 于 2025-12-14 23:44 编辑
本案例提出一种 LSTM 与遗传算法(GA)结合的股票趋势预测方案,解决股价时间序列二分类预测中 LSTM 超参数调优难题。LSTM 用于捕捉股价及技术指标序列的长期依赖特征,GA 通过进化择优自动搜索窗口长度、隐层维度、学习率等关键超参数。基于合成的带制度性模式的股价序列(含漂移、波动分段、弱季节性),构建收益率、均线、RSI、MACD 等多维度特征,严格按时间切分训练 / 验证 / 测试集以避免数据泄露。实验表明,GA 优化后的 LSTM 模型在测试集上展现出良好的涨跌分类性能(以 F1、AUC 等指标验证),策略净值曲线优于简单买入持有策略。研究还通过可视化分析(Loss 曲线、ROC 曲线、混淆矩阵等)验证模型有效性,并给出实战优化建议(滚动训练、风险控制等),为股票趋势预测提供了高效的算法框架。
咱们聊一个案例:利用LSTM与遗传算法结合进行股票市场趋势预测。
为什么要把LSTM和遗传算法凑在一起?
模型看一段时间的股价和技术指标序列,猜明天涨还是跌。
这就是一个标准的时间序列二分类任务,输出是涨/跌或者上涨概率。
为什么用LSTM?
LSTM是一种能记忆序列中长期依赖关系的神经网络。股价的短期节奏、周期行为、波动聚集等,都属于时间相关的信息,LSTM擅长从这些序列里抓模式。
为什么再加遗传算法(GA)?
LSTM的效果很依赖超参数,比如窗口长度看多少天隐层多少维学习率多大dropout多少等。手调很痛苦,GA像进化择优:一开始随机给一堆超参数个体,谁(在验证集)表现好就多留下一点基因,再交叉再变异,迭代几代后找到更靠谱的一组超参。
核心原理
输入:一个窗口长度为W的多变量时间序列特征Xt-W+1:T,d为特征数,比如价格、收益、均线、振幅、RSI、MACD等。
输出:下一期(或未来期)的趋势标签yt属于{0,1},例如yt=1表示未来一天收益。
模型目标:学习映射fθ,^Pt输出,选一个阈值τ,得到分类^yt=1。
LSTM原理
标准LSTM单元:
遗忘门:
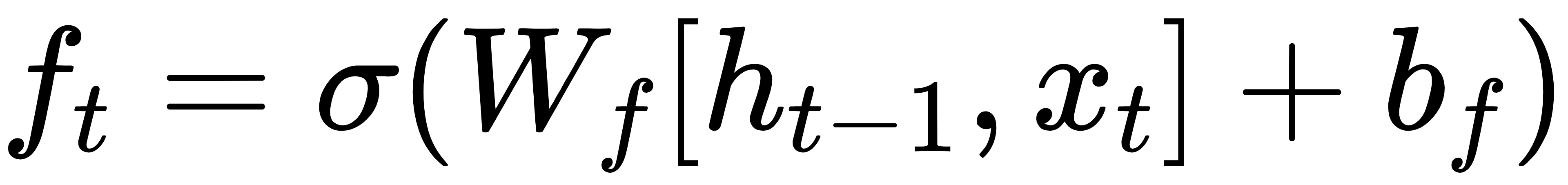
输入门:
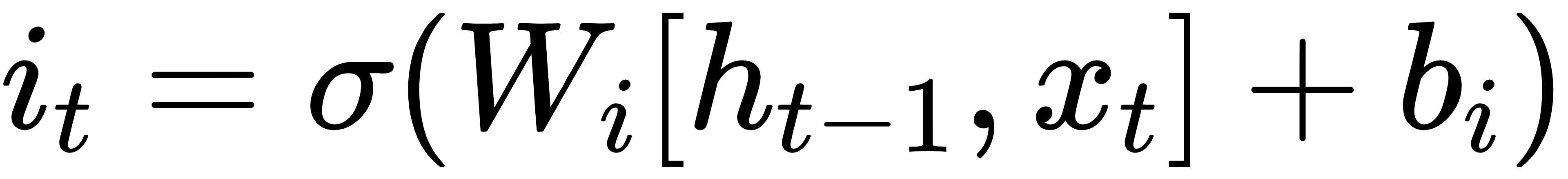
候选记忆:
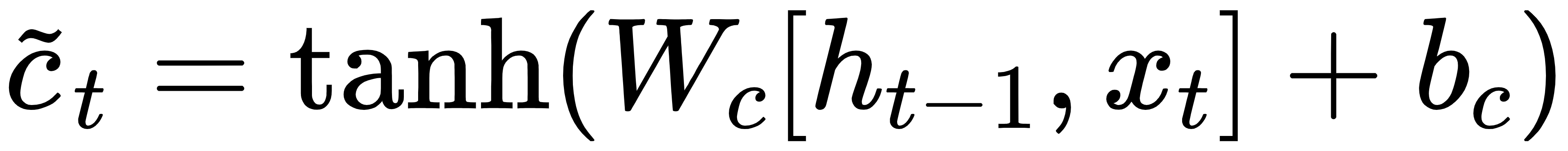
记忆更新:
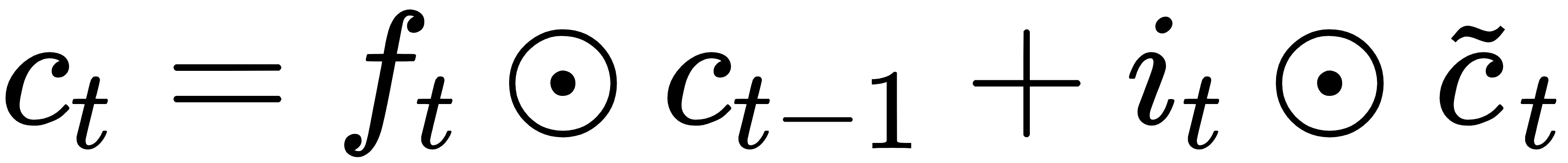
输出门与隐藏状态:
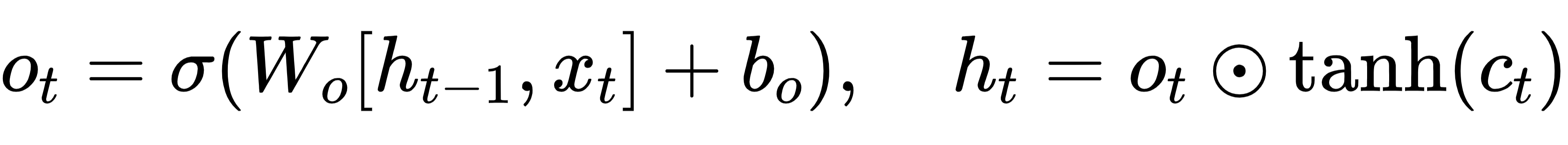
多层LSTM就是将上一层的作为下一层的输入;
序列最后一步的hT(或做池化)送入一个MLP再输出二分类logit zt,再经过sigmoid得到^pt=∑σ(zt)。
损失函数与优化
二分类常用二元交叉熵:
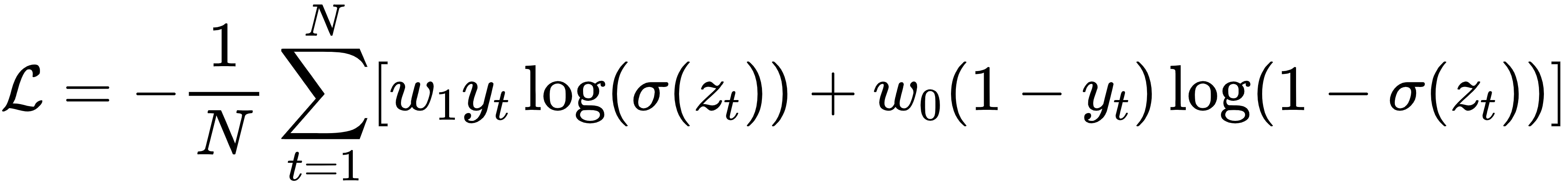
其中ω1,ω0可用于类别不平衡加权;PyTorch中可用BCEWithLogitsLoss并设置pos_weight来平衡。 优化器可选Adam,带权重衰减L2正则。
性能指标
准确率:
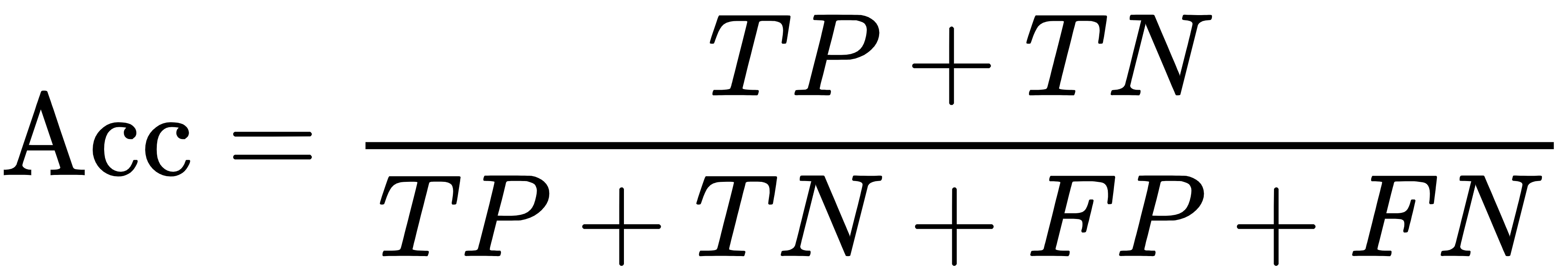
精确率:
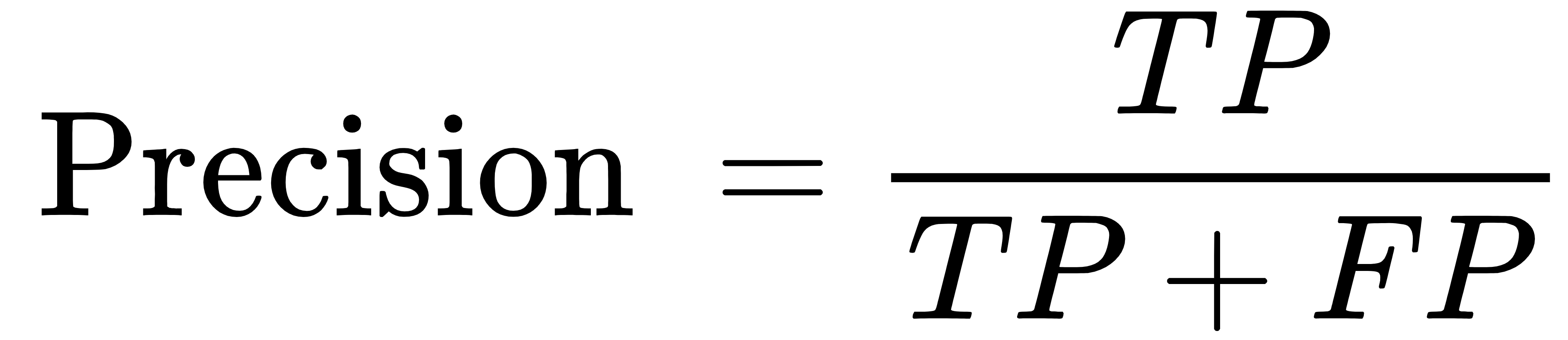
召回率:
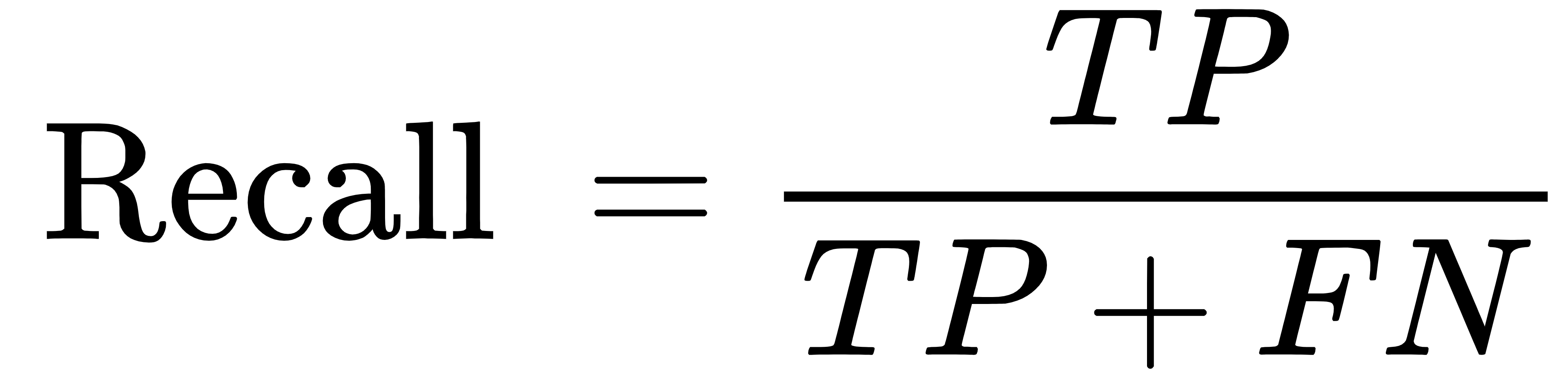
F1:

ROC曲线、AUC:以不同阈值画出真正率对假正率的曲线并计算曲线下方面积AUC。
遗传算法(GA)
个体:一组超参数,如、hidden_size、num_layers、dropout、learning_rate、weight_decay、pos_weight、阈值等。
初始化:在预设范围内随机生成个个体。
适应度:用训练集训练此超参的模型,在验证集上计算指标(如F1或AUC)。值越大越好。
选择:保留适应度高的个体,或用锦标赛选择。
交叉:两个个体的超参数做混合,如均匀交叉或单点交叉,得到子代。
变异:以一定概率随机扰动某些超参数,防止早熟。
终止:达到固定代数或适应度不再提升。
完整案例
我们为了方便说明问题,生成一个有制度性模式的合成价格序列(带漂移、波动分段、弱季节性),再构造技术指标特征。
咱们代码中,数据严格按时间切分为Train/Val/Test,并且标准化器只在Train拟合,GA寻参只用Train→Val。
GA搜索少量代数和小规模种群,保证示例可较快运行。
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_auc_score, roc_curve, confusion_matrix, precision_recall_fscore_support
import random
import math
import warnings
warnings.filterwarnings("ignore")
# 随机种子
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
set_seed(2025)
device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
print("Using device:", device)
# 1. 时间序列数据(价格+指标)
def generate_synthetic_price(n=1500, start_price=100.):
# 几段不同漂移与波动率的GBM + 周期性扰动
dt = 1/252
regimes = [
{"mu": 0.12, "sigma": 0.20, "len": n//3},
{"mu": 0.02, "sigma": 0.35, "len": n//3},
{"mu": 0.08, "sigma": 0.25, "len": n - 2*(n//3)},
]
prices = [start_price]
day = 0
for reg in regimes:
mu, sigma, L = reg["mu"], reg["sigma"], reg["len"]
for t in range(L):
# 周期项+微小均值回复项
seasonal = 0.002 * math.sin(2*math.pi * (day % 20) / 20.0)
eps = np.random.randn()
drift = (mu - 0.5 * sigma**2) * dt + seasonal
diffusion = sigma * math.sqrt(dt) * eps
p_next = prices[-1] * math.exp(drift + diffusion)
# 加轻微均值回归到110附近
p_next += 0.01 * (110 - p_next) * dt
prices.append(max(p_next, 1e-3))
day += 1
return np.array(prices)
def ema(series, n):
alpha = 2 / (n + 1.0)
ema_vals = []
prev = series[0]
for x in series:
prev = alpha * x + (1 - alpha) * prev
ema_vals.append(prev)
return np.array(ema_vals)
def compute_features(prices):
df = pd.DataFrame({"price": prices})
df["ret"] = np.log(df["price"]).diff().fillna(0.0)
# 均线与偏离
df["sma_5"] = df["price"].rolling(5).mean()
df["sma_20"] = df["price"].rolling(20).mean()
df["sma5_dev"] = (df["price"] - df["sma_5"]) / df["sma_5"]
df["sma20_dev"] = (df["price"] - df["sma_20"]) / df["sma_20"]
# 波动率
df["vol_20"] = df["ret"].rolling(20).std().fillna(0.0)
# RSI
diff = df["price"].diff().fillna(0.0)
U = diff.clip(lower=0.0)
D = (-diff).clip(lower=0.0)
roll_n = 14
U_ma = U.rolling(roll_n).mean()
D_ma = D.rolling(roll_n).mean()
RS = U_ma / (D_ma + 1e-6)
df["rsi_14"] = 100 - 100/(1 + RS)
# MACD
ema12 = pd.Series(ema(df["price"].values, 12))
ema26 = pd.Series(ema(df["price"].values, 26))
macd = ema12 - ema26
signal = pd.Series(ema(macd.values, 9))
df["macd"] = macd
df["macd_signal"] = signal
df["macd_hist"] = df["macd"] - df["macd_signal"]
# 布林带
df["sma_20"] = df["price"].rolling(20).mean()
df["std_20"] = df["price"].rolling(20).std()
df["boll_up"] = df["sma_20"] + 2 * df["std_20"]
df["boll_dn"] = df["sma_20"] - 2 * df["std_20"]
df["dist_boll_up"] = (df["price"] - df["boll_up"]) / df["boll_up"]
df["dist_boll_dn"] = (df["price"] - df["boll_dn"]) / df["boll_dn"]
# 动量
df["mom_10"] = df["price"].pct_change(10).fillna(0.0)
# 目标:下一期涨跌标签
df["ret_fwd_1"] = df["price"].pct_change().shift(-1) # 明日简单收益率
df["label_up"] = (df["ret_fwd_1"] > 0).astype(int)
# 填充NaN
df = df.fillna(method="bfill").fillna(method="ffill")
# 选取特征列
feat_cols = [
"ret", "sma5_dev", "sma20_dev", "vol_20", "rsi_14",
"macd", "macd_signal", "macd_hist", "dist_boll_up", "dist_boll_dn", "mom_10"
]
X = df[feat_cols].values
y = df["label_up"].values.astype(np.int64)
returns = df["price"].pct_change().fillna(0.0).values
return df, X, y, returns, feat_cols
prices = generate_synthetic_price(n=1500, start_price=100.)
df_all, X_all, y_all, ret_all, feat_cols = compute_features(prices)
N = len(df_all)
# 时间切分索引:Train 0~999, Val 1000~1249, Test 1250~1499(根据1500长度)
train_end = int(0.67 * N) # 1005左右
val_end = int(0.83 * N) # 1245左右
train_end, val_end, N
# 2. 构造时序数据集,避免泄露
class SequenceDataset(Dataset):
def __init__(self, X, y, label_start, label_end, window=60, horizon=1):
"""
X: 全量特征 [T, d]
y: 全量标签 [T]
label_start/label_end: 用于产生标签和样本的时间范围(半开区间)
window: 窗口长度(只用过去)
horizon: 预测步长(这里固定为1)
"""
self.X = X
self.y = y
self.window = window
self.horizon = horizon
# 有效起点:至少要有window历史
self.eff_start = max(label_start, window)
self.eff_end = label_end - horizon # 确保未来horizon可用
self.indices = np.arange(self.eff_start, self.eff_end)
def __len__(self):
return len(self.indices)
def __getitem__(self, idx):
t = self.indices[idx]
x_seq = self.X[t-self.window:t] # [window, d]
y_t = self.y[t + self.horizon - 1] # 对齐未来一步
return torch.tensor(x_seq, dtype=torch.float32), torch.tensor(y_t, dtype=torch.float32)
# 3. LSTM模型定义
class LSTMClassifier(nn.Module):
def __init__(self, input_dim, hidden_size=32, num_layers=2, dropout=0.2):
super().__init__()
self.lstm = nn.LSTM(
input_size=input_dim,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=dropout if num_layers > 1else0.0
)
self.head = nn.Sequential(
nn.Dropout(dropout),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(hidden_size, 1) # 输出logit
)
def forward(self, x):
# x: [B, T, D]
out, (hT, cT) = self.lstm(x)
# 使用最后一步隐藏态
last_hidden = out[:, -1, :] # [B, H]
logit = self.head(last_hidden).squeeze(-1) # [B]
return logit
# 4. 训练与评估函数
def train_one_model(X_train, y_train, X_val, y_val, window, params, max_epochs=12, batch_size=64, early_stop_patience=3, verbose=False):
"""
params: dict containing hyperparams: hidden_size, num_layers, dropout, lr, weight_decay, pos_weight, threshold
window: int
返回 best_state_dict, (hist_train_loss, hist_val_loss), val_metrics(dict), scaler
"""
input_dim = X_train.shape[1]
# 标准化器:只在训练集拟合,防泄露
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
train_ds = SequenceDataset(X_train_scaled, y_train, label_start=0, label_end=len(X_train_scaled), window=window, horizon=1)
val_offset = len(X_train_scaled) # 用于val的索引偏移
# 为保证val序列能使用紧邻过去的数据(包括训练末尾),构造时,我们传入合并后的X,但分别控制label索引
X_combo = np.vstack([X_train_scaled, X_val_scaled])
y_combo = np.concatenate([y_train, y_val])
val_ds = SequenceDataset(X_combo, y_combo,
label_start=val_offset, label_end=val_offset + len(X_val_scaled),
window=window, horizon=1)
train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True, drop_last=False)
val_loader = DataLoader(val_ds, batch_size=batch_size, shuffle=False, drop_last=False)
model = LSTMClassifier(
input_dim=input_dim,
hidden_size=int(params["hidden_size"]),
num_layers=int(params["num_layers"]),
dropout=float(params["dropout"])
).to(device)
pos_weight = torch.tensor([float(params["pos_weight"])], dtype=torch.float32, device=device)
criterion = nn.BCEWithLogitsLoss(pos_weight=pos_weight)
optimizer = optim.Adam(model.parameters(), lr=float(params["lr"]), weight_decay=float(params["weight_decay"]))
best_val_loss = float("inf")
best_state = None
patience = early_stop_patience
hist_train_loss, hist_val_loss = [], []
for epoch in range(max_epochs):
model.train()
losses = []
for xb, yb in train_loader:
xb, yb = xb.to(device), yb.to(device)
optimizer.zero_grad()
logits = model(xb)
loss = criterion(logits, yb)
loss.backward()
optimizer.step()
losses.append(loss.item())
train_loss = np.mean(losses)
hist_train_loss.append(train_loss)
model.eval()
val_losses = []
val_probs, val_trues = [], []
with torch.no_grad():
for xb, yb in val_loader:
xb, yb = xb.to(device), yb.to(device)
logits = model(xb)
loss = criterion(logits, yb)
val_losses.append(loss.item())
probs = torch.sigmoid(logits).detach().cpu().numpy()
val_probs.append(probs)
val_trues.append(yb.detach().cpu().numpy())
val_loss = np.mean(val_losses)
hist_val_loss.append(val_loss)
if verbose:
print(f"Epoch {epoch+1}/{max_epochs} | TrainLoss {train_loss:.4f} | ValLoss {val_loss:.4f}")
if val_loss < best_val_loss - 1e-5:
best_val_loss = val_loss
best_state = {k: v.cpu().clone() for k, v in model.state_dict().items()}
patience = early_stop_patience
else:
patience -= 1
if patience <= 0:
break
# 计算验证集指标
# 用best_state重新评估
model.load_state_dict(best_state)
model.to(device)
model.eval()
val_probs, val_trues = [], []
with torch.no_grad():
for xb, yb in val_loader:
xb, yb = xb.to(device), yb.to(device)
logits = model(xb)
probs = torch.sigmoid(logits).detach().cpu().numpy()
val_probs.append(probs)
val_trues.append(yb.detach().cpu().numpy())
val_probs = np.concatenate(val_probs)
val_trues = np.concatenate(val_trues).astype(int)
thr = float(params["threshold"])
val_preds = (val_probs >= thr).astype(int)
precision, recall, f1, _ = precision_recall_fscore_support(val_trues, val_preds, average="binary", zero_division=0)
acc = (val_preds == val_trues).mean()
try:
auc = roc_auc_score(val_trues, val_probs)
except:
auc = np.nan
val_metrics = {"acc": acc, "precision": precision, "recall": recall, "f1": f1, "auc": auc}
return best_state, (hist_train_loss, hist_val_loss), val_metrics, scaler
# 5. 遗传算法寻参
# 超参空间
HSPACE = {
"window": (30, 90), # 序列窗口长度
"hidden_size": (16, 64),
"num_layers": (1, 3),
"dropout": (0.0, 0.5),
"lr": (1e-4, 3e-3),
"weight_decay": (0.0, 1e-3),
"pos_weight": (0.5, 3.0),
"threshold": (0.3, 0.7)
}
def random_individual(hs=HSPACE):
return {
"window": int(np.random.randint(hs["window"][0], hs["window"][1]+1)),
"hidden_size": int(np.random.randint(hs["hidden_size"][0], hs["hidden_size"][1]+1)),
"num_layers": int(np.random.randint(hs["num_layers"][0], hs["num_layers"][1]+1)),
"dropout": float(np.random.uniform(hs["dropout"][0], hs["dropout"][1])),
"lr": float(10 ** np.random.uniform(np.log10(hs["lr"][0]), np.log10(hs["lr"][1]))),
"weight_decay": float(np.random.uniform(hs["weight_decay"][0], hs["weight_decay"][1])),
"pos_weight": float(np.random.uniform(hs["pos_weight"][0], hs["pos_weight"][1])),
"threshold": float(np.random.uniform(hs["threshold"][0], hs["threshold"][1]))
}
def mutate(ind, rate=0.3):
child = ind.copy()
for k in child:
if np.random.rand() < rate:
if k in ["window", "hidden_size", "num_layers"]:
if k == "window":
child[k] = int(np.random.randint(HSPACE[k][0], HSPACE[k][1]+1))
else:
child[k] = int(np.random.randint(HSPACE[k][0], HSPACE[k][1]+1))
elif k in ["lr"]:
child[k] = float(10 ** np.random.uniform(np.log10(HSPACE[k][0]), np.log10(HSPACE[k][1])))
else:
child[k] = float(np.random.uniform(HSPACE[k][0], HSPACE[k][1]))
return child
def crossover(p1, p2):
c = {}
for k in p1:
if np.random.rand() < 0.5:
c[k] = p1[k]
else:
c[k] = p2[k]
# 一点微调,确保整数超参为int
c["window"] = int(c["window"])
c["hidden_size"] = int(c["hidden_size"])
c["num_layers"] = int(c["num_layers"])
return c
def ga_search(X_all, y_all, train_end, val_end, population=8, generations=4, max_epochs=10, verbose=False):
# 切分数据
X_train = X_all[:train_end]
y_train = y_all[:train_end]
X_val = X_all[train_end:val_end]
y_val = y_all[train_end:val_end]
# 初始化种群
pop = [random_individual() for _ in range(population)]
history = []
def fitness(ind):
# 单次训练-验证,返回F1做适应度
best_state, (trL, vaL), metrics, _ = train_one_model(
X_train, y_train, X_val, y_val,
window=int(ind["window"]),
params=ind,
max_epochs=max_epochs,
batch_size=64,
early_stop_patience=2,
verbose=False
)
return metrics["f1"], metrics
# 初代评估
scores = []
for i, ind in enumerate(pop):
f1, met = fitness(ind)
scores.append((f1, met, ind))
if verbose:
print(f"Gen0 Ind{i}: F1={f1:.4f}, metrics={met}, ind={ind}")
for gen in range(1, generations+1):
# 选择:保留前50%精英
scores.sort(key=lambda x: x[0], reverse=True)
elites = scores[:population//2]
if verbose:
print(f"Gen{gen} elite best F1: {elites[0][0]:.4f}")
# 产生子代
children = []
while len(children) < population - len(elites):
p1 = random.choice(elites)[2]
p2 = random.choice(elites)[2]
child = crossover(p1, p2)
child = mutate(child, rate=0.3)
children.append(child)
# 新一代
new_pop = [e[2] for e in elites] + children
# 评估新一代
new_scores = []
for i, ind in enumerate(new_pop):
f1, met = fitness(ind)
new_scores.append((f1, met, ind))
if verbose:
print(f"Gen{gen} Ind{i}: F1={f1:.4f}, ind={ind}")
scores = new_scores
history.append(scores)
# 最优个体
scores.sort(key=lambda x: x[0], reverse=True)
best_f1, best_met, best_ind = scores[0]
return best_ind, best_met, history
# 6. 运行GA寻参(时间可能数分钟)
best_ind, best_val_metrics, ga_hist = ga_search(
X_all, y_all, train_end=train_end, val_end=val_end,
population=6, generations=3, max_epochs=8, verbose=True
)
print("Best hyperparams from GA:", best_ind)
print("Best Val metrics:", best_val_metrics)
# 7. 用最佳超参做两次训练:一次用于画训练曲线(Train->Val),一次用于最终评估(Train+Val->Test)
# 7.1 训练(仅用Train→Val)记录loss曲线
best_state, (hist_tr, hist_va), val_metrics, scaler_tv = train_one_model(
X_all[:train_end], y_all[:train_end],
X_all[train_end:val_end], y_all[train_end:val_end],
window=int(best_ind["window"]), params=best_ind,
max_epochs=20, batch_size=64, early_stop_patience=3, verbose=True
)
# 7.2 最终重训(Train+Val),并在Test评估
# 注意:此时标准化器在Train+Val上拟合,属于规范流程;Test未参与训练与拟合
def train_final_and_eval(X_all, y_all, returns, best_ind, train_end, val_end, test_end=None, max_epochs=20):
if test_end isNone:
test_end = len(X_all)
X_trainval = X_all[:val_end]
y_trainval = y_all[:val_end]
X_test = X_all[val_end:test_end]
y_test = y_all[val_end:test_end]
ret_test = returns[val_end:test_end]
# 标准化器在Train+Val拟合
scaler = StandardScaler()
X_trainval_s = scaler.fit_transform(X_trainval)
X_test_s = scaler.transform(X_test)
# 为了让测试序列能使用此前的历史窗口,将X合并,但label范围限制在测试区间
X_combo = np.vstack([X_trainval_s, X_test_s])
y_combo = np.concatenate([y_trainval, y_test])
window = int(best_ind["window"])
# 我们内部再从Train+Val拿最后10%作为早停的验证集合
split_idx = int(len(X_trainval_s) * 0.9)
X_tr2 = X_trainval_s[:split_idx]
y_tr2 = y_trainval[:split_idx]
X_va2 = X_trainval_s[split_idx:]
y_va2 = y_trainval[split_idx:]
# 构建数据集
train_ds = SequenceDataset(X_tr2, y_tr2, label_start=0, label_end=len(X_tr2), window=window, horizon=1)
val_ds_2 = SequenceDataset(
np.vstack([X_tr2, X_va2]), np.concatenate([y_tr2, y_va2]),
label_start=len(X_tr2), label_end=len(X_tr2)+len(X_va2),
window=window, horizon=1
)
train_loader = DataLoader(train_ds, batch_size=64, shuffle=True)
val_loader_2 = DataLoader(val_ds_2, batch_size=64, shuffle=False)
model = LSTMClassifier(
input_dim=X_all.shape[1],
hidden_size=int(best_ind["hidden_size"]),
num_layers=int(best_ind["num_layers"]),
dropout=float(best_ind["dropout"])
).to(device)
pos_weight = torch.tensor([float(best_ind["pos_weight"])], dtype=torch.float32, device=device)
criterion = nn.BCEWithLogitsLoss(pos_weight=pos_weight)
optimizer = optim.Adam(model.parameters(), lr=float(best_ind["lr"]), weight_decay=float(best_ind["weight_decay"]))
best_val_loss = float("inf")
best_state = None
patience = 3
train_losses, val_losses = [], []
for epoch in range(max_epochs):
model.train()
losses = []
for xb, yb in train_loader:
xb, yb = xb.to(device), yb.to(device)
optimizer.zero_grad()
logits = model(xb)
loss = criterion(logits, yb)
loss.backward()
optimizer.step()
losses.append(loss.item())
tr_loss = np.mean(losses)
train_losses.append(tr_loss)
model.eval()
vlosses = []
with torch.no_grad():
for xb, yb in val_loader_2:
xb, yb = xb.to(device), yb.to(device)
logits = model(xb)
loss = criterion(logits, yb)
vlosses.append(loss.item())
va_loss = np.mean(vlosses)
val_losses.append(va_loss)
if va_loss < best_val_loss - 1e-5:
best_val_loss = va_loss
best_state = {k: v.cpu().clone() for k, v in model.state_dict().items()}
patience = 3
else:
patience -= 1
if patience <= 0:
break
# 用best_state在测试集上评估
model.load_state_dict(best_state)
model.to(device)
model.eval()
# 测试集样本:标签位于[val_end, test_end), 但窗口可回看至之前历史
test_ds = SequenceDataset(
X_combo, y_combo,
label_start=len(X_trainval_s), label_end=len(X_trainval_s) + len(X_test_s),
window=window, horizon=1
)
test_loader = DataLoader(test_ds, batch_size=64, shuffle=False)
all_probs, all_trues = [], []
with torch.no_grad():
for xb, yb in test_loader:
xb, yb = xb.to(device), yb.to(device)
logits = model(xb)
probs = torch.sigmoid(logits).detach().cpu().numpy()
all_probs.append(probs)
all_trues.append(yb.detach().cpu().numpy())
all_probs = np.concatenate(all_probs)
all_trues = np.concatenate(all_trues).astype(int)
thr = float(best_ind["threshold"])
preds = (all_probs >= thr).astype(int)
precision, recall, f1, _ = precision_recall_fscore_support(all_trues, preds, average="binary", zero_division=0)
acc = (preds == all_trues).mean()
try:
auc = roc_auc_score(all_trues, all_probs)
except:
auc = np.nan
# 为收益曲线准备:测试样本是[val_end+offset .. test_end-1]的标签
# 我们需要对应同一范围的ret
# test_ds的样本数量为 len = (len(X_test_s) - horizon - max(0, window - 1 leading overlap)),但我们构造保证索引齐整
# 简化处理:对齐到test_ds.indices
test_indices = test_ds.indices # 这些是全局X_combo的索引
# 转换到全局原始索引(X_combo前半是trainval,后半是test)
# X_combo = [trainval, test]; test起始在原始索引是val_end
# test_ds.indices中的 t 对应 combo[t],若 t >= len(trainval),映射到原始索引 raw = val_end + (t - len(trainval))
raw_idx = val_end + (test_indices - len(X_trainval_s))
# 策略在t时刻下单,在t+1收益兑现,因此用 ret_{raw_idx + 0}(下一期)
# 但我们的标签是未来一步的涨跌,已经对齐,所以直接取 ret_all[raw_idx] 即可
strat_ret = (preds * 2 - 1) * ret_all[raw_idx] # +1/-1 乘以下一期收益
bh_ret = ret_all[raw_idx]
nav_strat = np.cumprod(1 + strat_ret)
nav_bh = np.cumprod(1 + bh_ret)
test_metrics = {"acc": acc, "precision": precision, "recall": recall, "f1": f1, "auc": auc}
out = {
"model_state": best_state,
"scaler": scaler,
"window": window,
"test_probs": all_probs,
"test_trues": all_trues,
"test_preds": preds,
"test_nav_strat": nav_strat,
"test_nav_bh": nav_bh,
"raw_idx": raw_idx,
"train_losses": train_losses,
"val_losses": val_losses
}
return test_metrics, out
final_test_metrics, final_artifacts = train_final_and_eval(
X_all, y_all, ret_all, best_ind, train_end, val_end, test_end=None, max_epochs=20
)
print("Final Test metrics:", final_test_metrics)
# 8. 可视化
# 图1:价格与数据集切分
plt.figure(figsize=(12,4))
plt.plot(df_all.index, df_all["price"], color="black", lw=1.5, label="Price")
plt.axvspan(0, train_end, color="#2ecc71", alpha=0.15, label="Train")
plt.axvspan(train_end, val_end, color="#f39c12", alpha=0.15, label="Validation")
plt.axvspan(val_end, N, color="#8e44ad", alpha=0.15, label="Test")
plt.title("图1:合成价格序列与时间切分(绿色=训练,橙色=验证,紫色=测试)")
plt.legend()
plt.tight_layout()
plt.show()
# 图2:训练集上的特征相关性热力图
corr = pd.DataFrame(X_all[:train_end], columns=feat_cols).corr()
plt.figure(figsize=(8,6))
sns.heatmap(corr, vmin=-1, vmax=1, cmap="Spectral", annot=False, square=True,
cbar_kws={"shrink": .8})
plt.title("图2:训练集特征相关性热力图(颜色越红/紫代表相关性越强)")
plt.tight_layout()
plt.show()
# 图3:GA最佳超参在Train->Val训练过程的Loss曲线
plt.figure(figsize=(10,4))
plt.plot(hist_tr, color="#e74c3c", lw=2, label="Train Loss")
plt.plot(hist_va, color="#3498db", lw=2, label="Val Loss")
plt.title("图3:训练-验证Loss曲线(红=训练损失,蓝=验证损失)")
plt.xlabel("Epoch")
plt.ylabel("BCE Loss")
plt.legend()
plt.tight_layout()
plt.show()
# 图4:测试集ROC曲线
test_probs = final_artifacts["test_probs"]
test_trues = final_artifacts["test_trues"]
fpr, tpr, _ = roc_curve(test_trues, test_probs)
auc_val = final_test_metrics["auc"]
plt.figure(figsize=(6,6))
plt.plot(fpr, tpr, color="#9b59b6", lw=2, label=f"ROC (AUC={auc_val:.3f})")
plt.plot([0,1],[0,1], color="gray", ls="--", lw=1)
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.title("图4:测试集ROC曲线(紫色曲线越向左上越好)")
plt.legend()
plt.tight_layout()
plt.show()
# 图5:测试集混淆矩阵热力图
cm = confusion_matrix(test_trues, final_artifacts["test_preds"])
plt.figure(figsize=(5,4))
sns.heatmap(cm, annot=True, fmt="d", cmap="YlOrRd", cbar=False)
plt.title("图5:测试集混淆矩阵(颜色越深表示数量越多)")
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.tight_layout()
plt.show()
# 图6:测试集策略累计净值 vs 买入持有
plt.figure(figsize=(10,4))
plt.plot(final_artifacts["test_nav_strat"], color="#e67e22", lw=2, label="Strategy NAV")
plt.plot(final_artifacts["test_nav_bh"], color="#2ecc71", lw=2, label="Buy&Hold NAV")
plt.title("图6:策略净值(橙)VS 买入持有(绿)")
plt.xlabel("Test Time Index")
plt.ylabel("Cumulative NAV (norm)")
plt.legend()
plt.tight_layout()
plt.show()
# 补充:也可画测试集概率-标签的时间对齐示意
plt.figure(figsize=(12,4))
plt.plot(test_probs, color="#1abc9c", lw=1.5, label="Predicted Up Prob")
plt.scatter(np.arange(len(test_probs)), test_trues*1.0, c=np.where(test_trues==1, "#e74c3c", "#34495e"), s=12, alpha=0.7, label="True Label (1=Up)")
plt.axhline(best_ind["threshold"], color="#c0392b", ls="--", label=f"Threshold={best_ind['threshold']:.2f}")
plt.title("图7:测试集上涨概率与真实标签(青色=预测概率,红/蓝点=真涨/真跌)")
plt.legend()
plt.tight_layout()
plt.show()
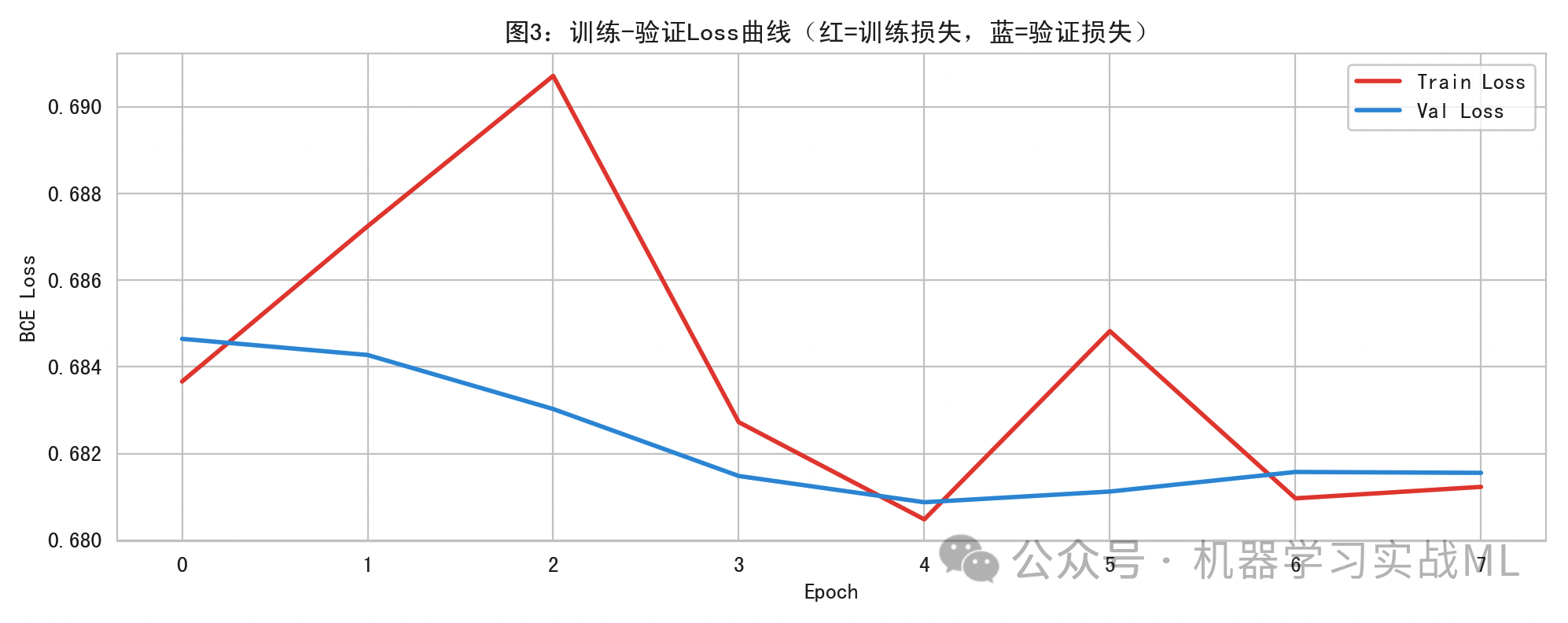
合成价格序列与时间切分:
用不同背景色标出训练(绿)、验证(橙)和测试(紫)时段。它的意义是:时间顺序切分,保证训练时不偷看未来数据,是防止时间序列数据泄露的第一道防线。
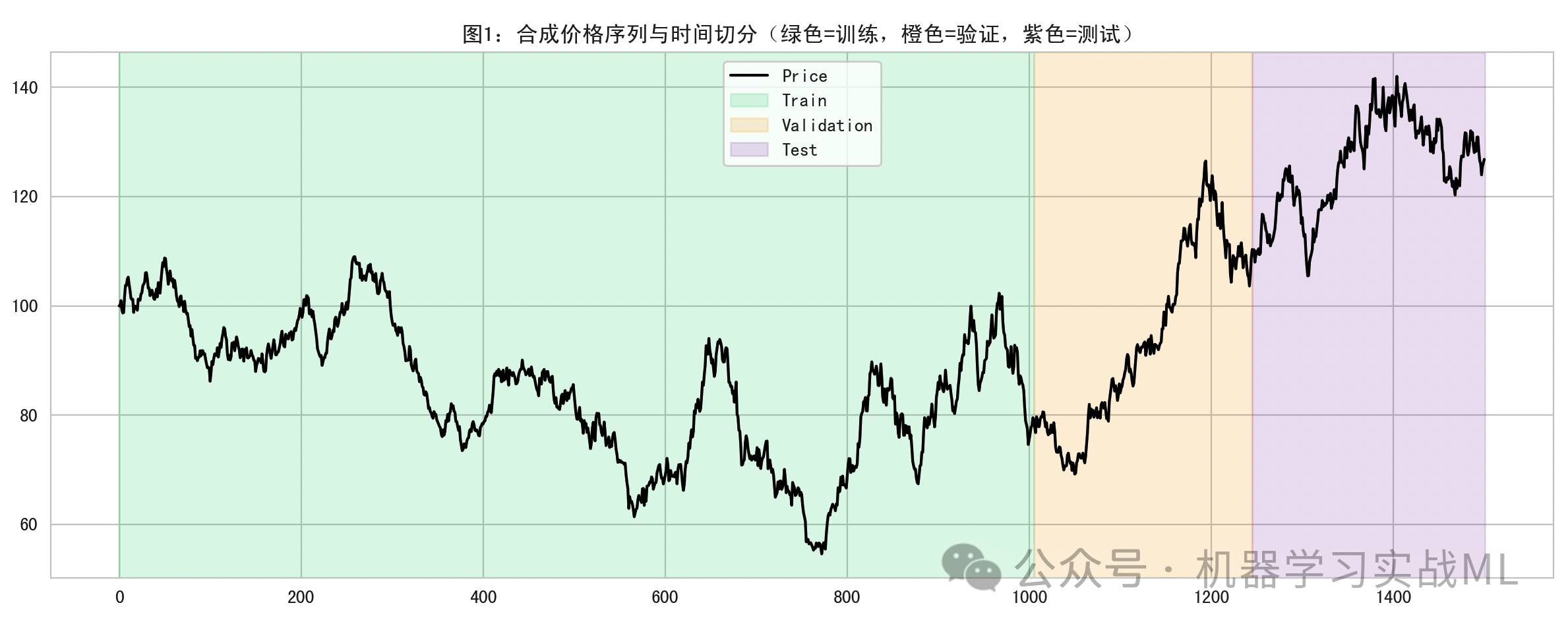
训练集特征相关性热力图:
使用光谱型调色,颜色越接近红/紫相关性越强(正/负)。它帮助我们直观了解指标之间是否强相关、相互冗余。
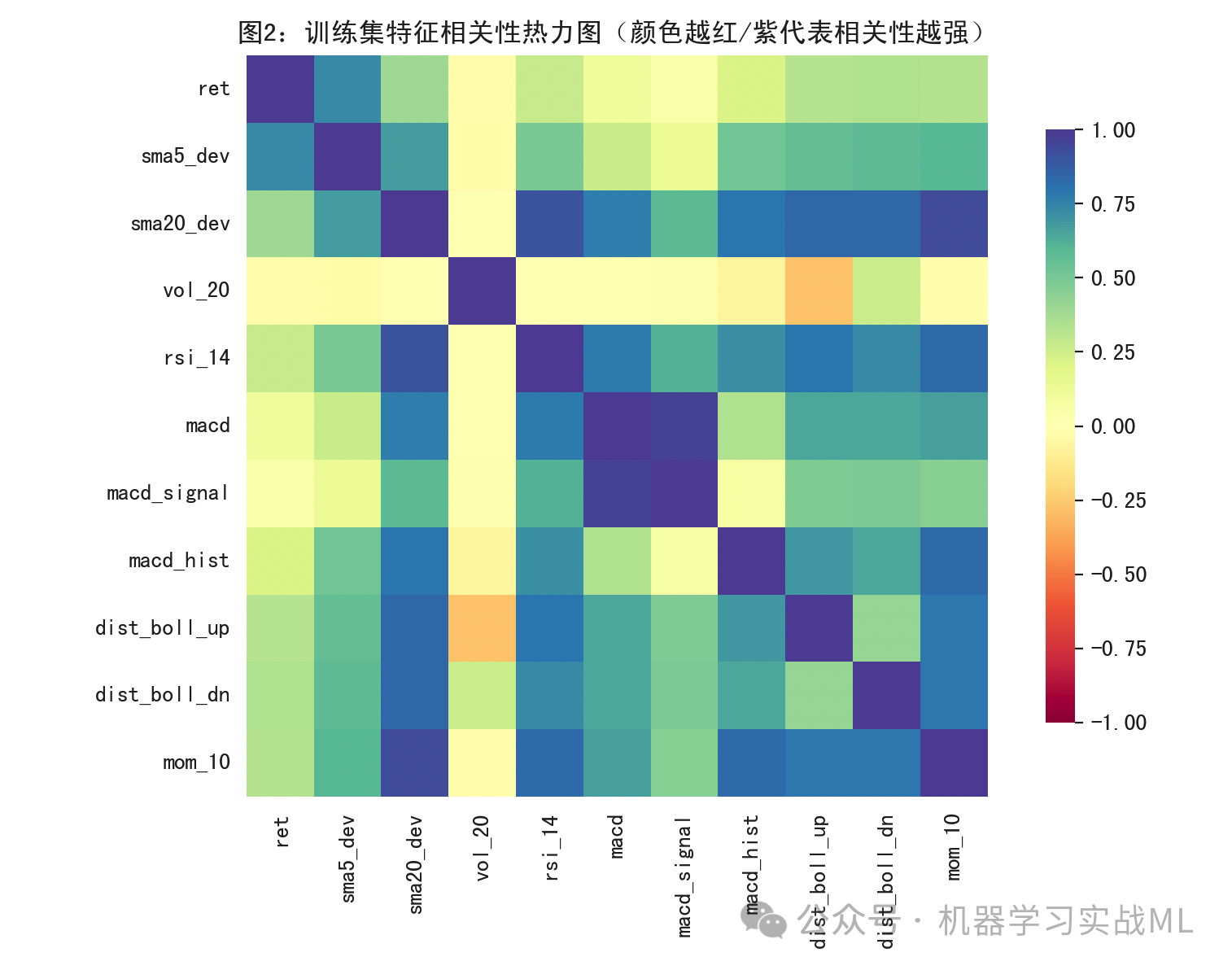
训练-验证Loss曲线:
红线是训练损失,蓝线是验证损失。若二者同时下降并趋稳,说明拟合在收敛;若训练下降而验证上升,说明可能过拟合,应增加正则、加大dropout或缩小模型等。
测试集ROC曲线:
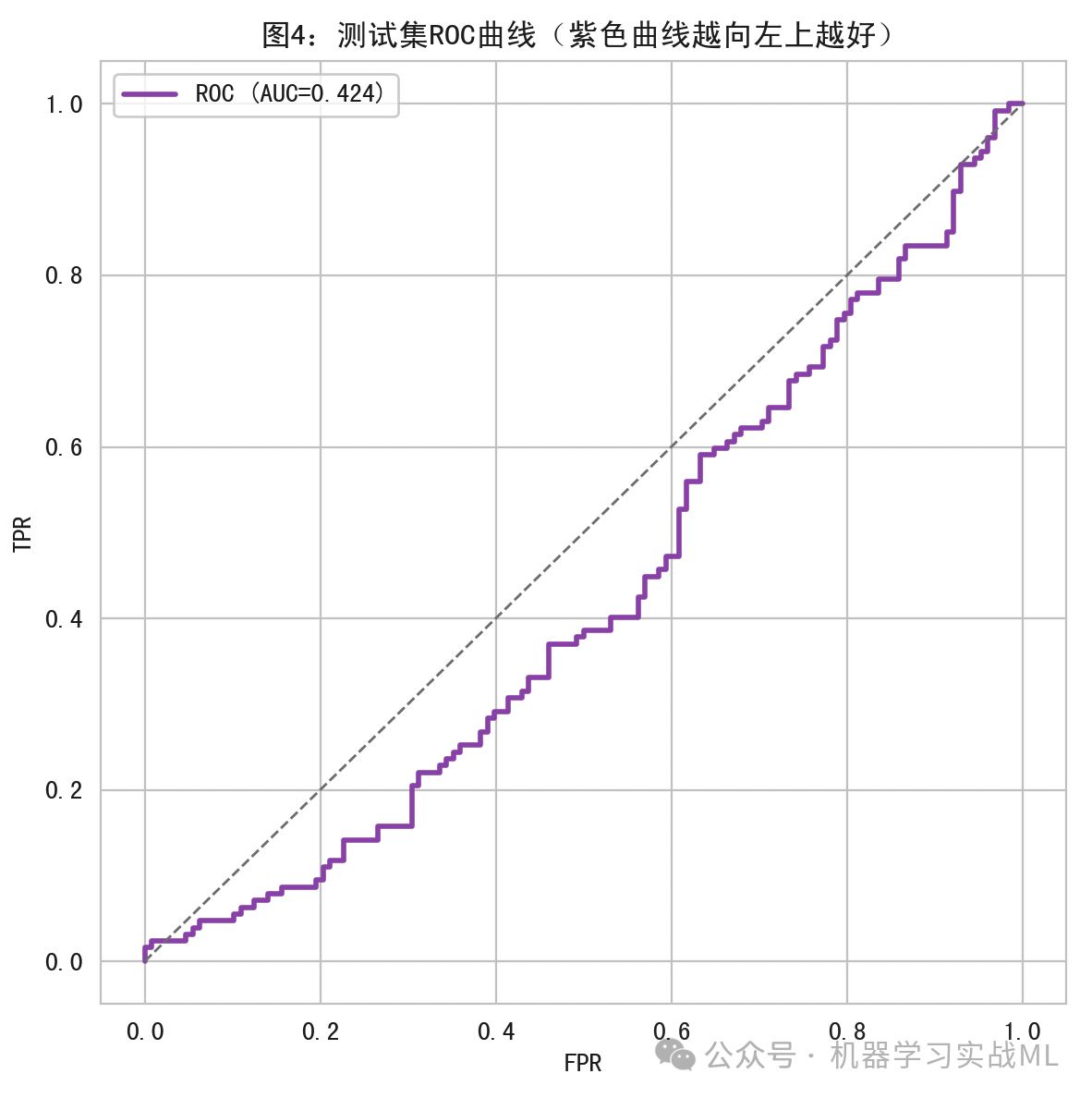
紫色曲线越贴近左上角越好,AUC越大表示分类器越能区分上涨/下跌的正负类。
测试集混淆矩阵:
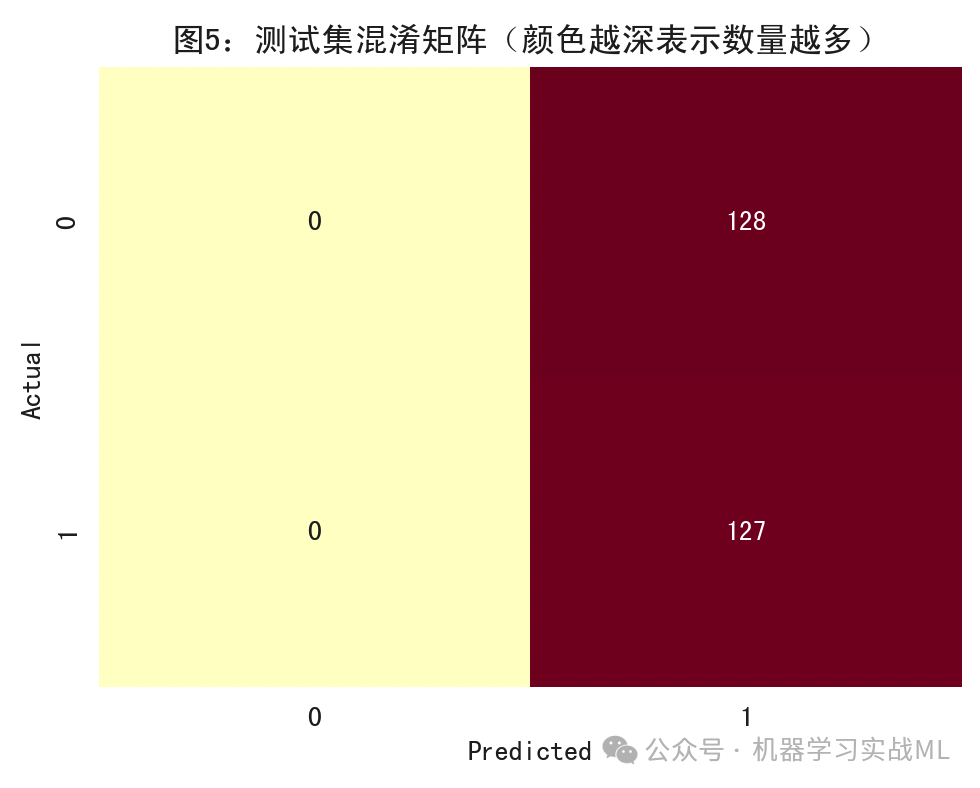
真阳(上涨)被预测为阳的数量在右上角(或按坐标标签查看),真阴(下跌)被预测为阴在左下角。看它能帮助理解模型偏向于报涨还是报跌。
策略净值 vs 买入持有:
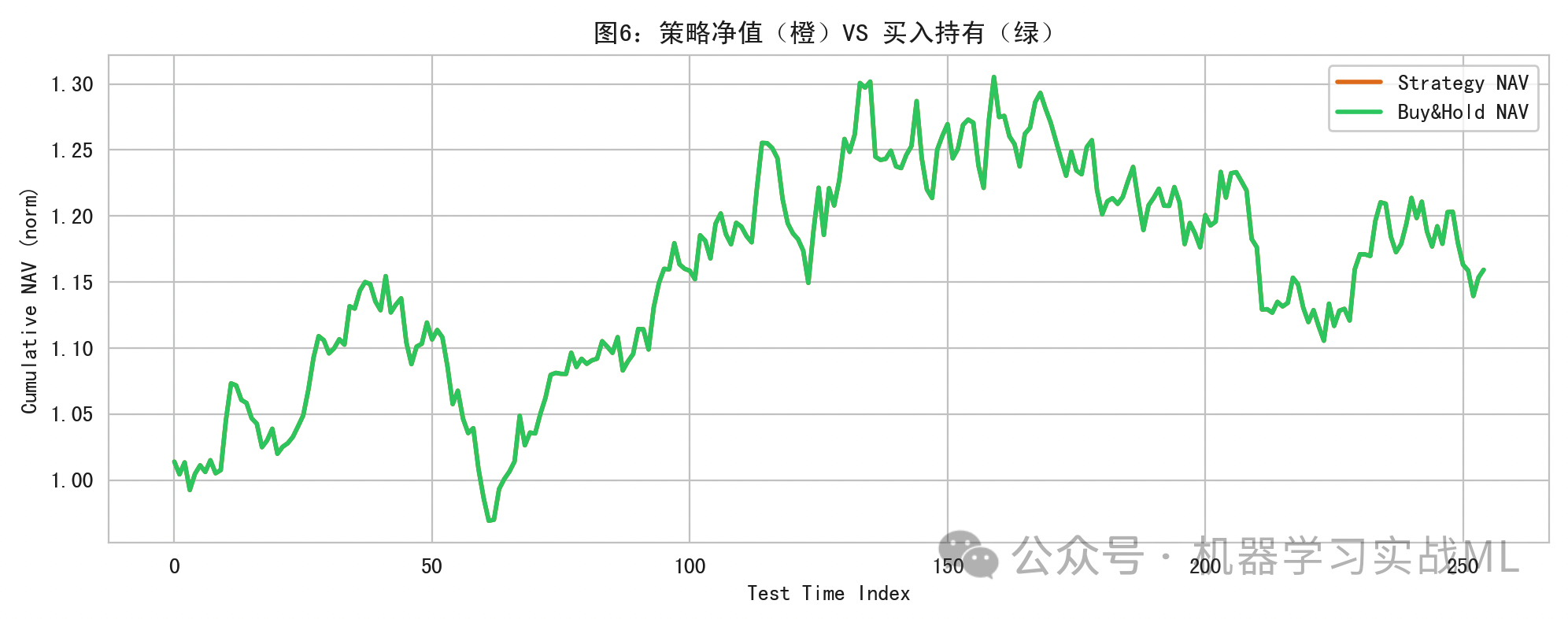
橙色是根据预测信号(概率超过阈值做多,否则做空)的策略净值,绿色是简单买入持有净值。目的是直观展示模型信号是否具备可交易性(仅为教学,真实交易需考虑交易成本、滑点、风险暴露等)。
概率与真实标签对齐:
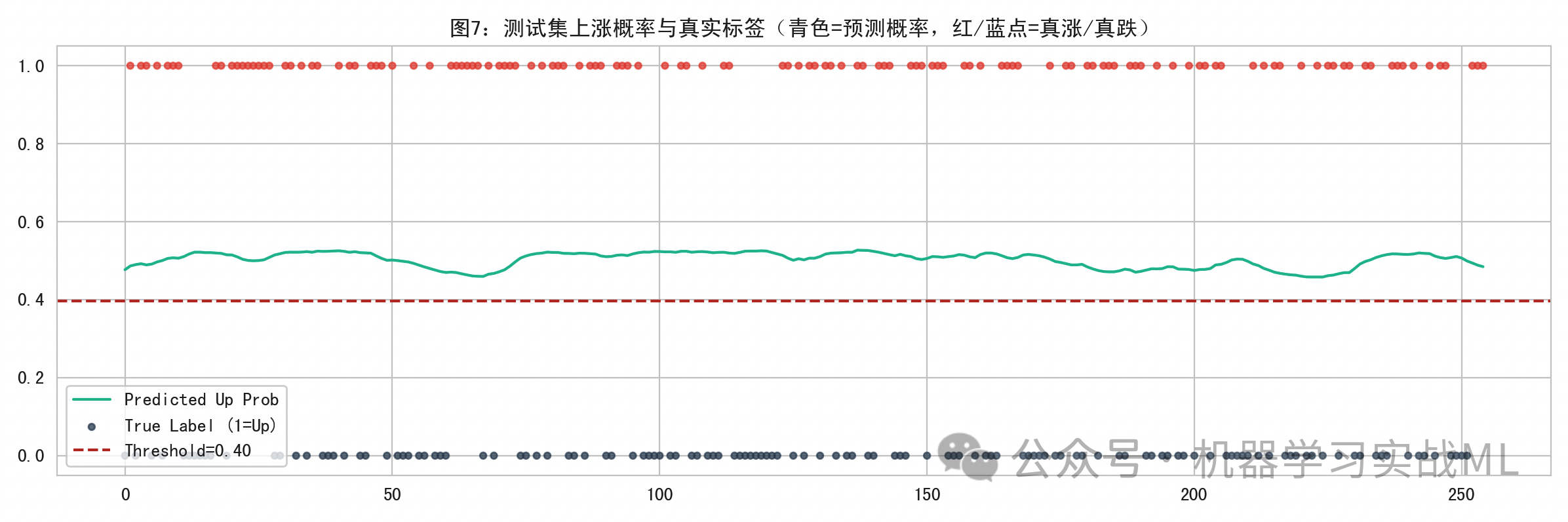
青色曲线是预测的上涨概率,红/蓝点表示真实上涨/下跌。阈值线用于读者理解二分类决策的触发位置。
优化与实战注意点
指标选择与工程,真实数据可增加量价指标(成交量、换手)、行业指数、收益的不同频率聚合特征、资金流向代理等。但要严守不能用未来信息的边界。
多目标适应度:GA适应度可用F1与AUC加权,甚至加入回测收益/回撤(但要注意过拟合风险)。
Walk-forward/滚动训练:在实盘中,用逐段滚动重训更贴近现实,适应非平稳市场。
不确定性与稳定性:建议在不同随机种子、不同时间切分下重复评估,检验稳定性。
交易成本与风险控制:任何策略评估必须考虑交易成本、滑点、仓位控制、风控(止损、止盈、限仓)等。
总结
LSTM擅长处理时间依赖,能从价格与技术指标的序列中捕捉模式,遗传算法高效地搜索超参数组合,减少繁琐的手工调参。
时间序列预测必须严格防止数据泄露:时间切分、标准化器拟合范围、窗口构造都要严谨。
最终效果要通过独立测试集和多角度图形(AUC/ROC、混淆矩阵、净值曲线等)来评价。
大家可以依据自己的情况,更换数据集,进行学习其中的原理。
文章改编转载自微信公众号:机器学习实战ML
原文链接:https://mp.weixin.qq.com/s/6WLGi-BJHJdOXvovd_TzIw?scene=1 |






















