本帖最后由 Jack小新 于 2026-2-6 13:04 编辑
内容提要
过去十年,人工智能取得了飞跃式的发展。它可以识别图像、翻译语言、诊断疾病,甚至在某些任务上超过人类专家。然而,随着 AI 逐渐进入医疗、金融、司法等关键领域,人们开始意识到一个根本性问题:我们并不知道 AI 为什么会做出某种判断。
因此,“可解释人工智能(Explainable AI, XAI)”成为当下 AI 研究的重要方向。它关注的不再只是“准不准”,而是“能不能说清楚”。
最近,一项由 IEEE 出版、发表在第八届国际人工智能会议上的研究,给出了一个颇具未来感的答案:量子计算或能让 AI 既更聪明,也更会“说明理由”。

01 为什么AI需要解释自己?
人工智能越来越准,却越来越难解释。这是当下 AI 领域最令人焦虑的问题之一。
在医疗场景中,AI 可以判断一张影像“高度疑似疾病”,却说不清依据;在金融系统里,算法可以拒绝一笔贷款,却难以明确给出拒绝原因;在司法等关乎公平的公共领域,这种“难以言明缘由的智能”甚至可能带来不可控的偏见与后果。
如果 AI 不能解释自己,人类就很难真正信任它。这种对透明度的需求,在法律、金融、医疗等高风险领域显得尤为紧迫。

图源网络
近日,一项来自斯里兰卡莫拉图瓦大学与科伦坡大学的研究显示:量子计算极有可能让 AI 既更聪明,也更能“说清楚”。
研究团队并没有试图通过堆叠算力去打造一个“更大的黑盒模型”,而是选择从一个根本问题入手:
AI 到底是依据什么做出判断的?
为了解答这个问题,他们提出了一个听起来很“化学”的概念:活性成分(Active Ingredient)。
医疗领域如止痛药,真正起疗效的是扑热息痛(Paracetamol);食品领域如姜黄,发挥健康效益的是姜黄素(Curcumin)。
同理,在人工智能的决策过程中,也存在着决定输出结果的“活性成分”,即那些对模型输出产生最强烈影响的关键输入特征。
但问题在于,传统 AI 模型,很难清楚地告诉我们这些“活性成分”到底是什么。这一问题的深层原因在于,我们目前用来拆解 AI 理由的解释工具遇到了适配性瓶颈。
研究指出,目前主流的解释工具如 SHAP,其核心假设是各特征之间是相互独立、互不干扰的。然而,在复杂的经典模型(如玻尔兹曼机)中,节点往往是紧密互联的;而在量子模型中,“量子纠缠” 的存在更是彻底打破了特征独立的假设:一个量子比特的状态直接影响另一个,它们之间存在着微妙且深刻的关联。
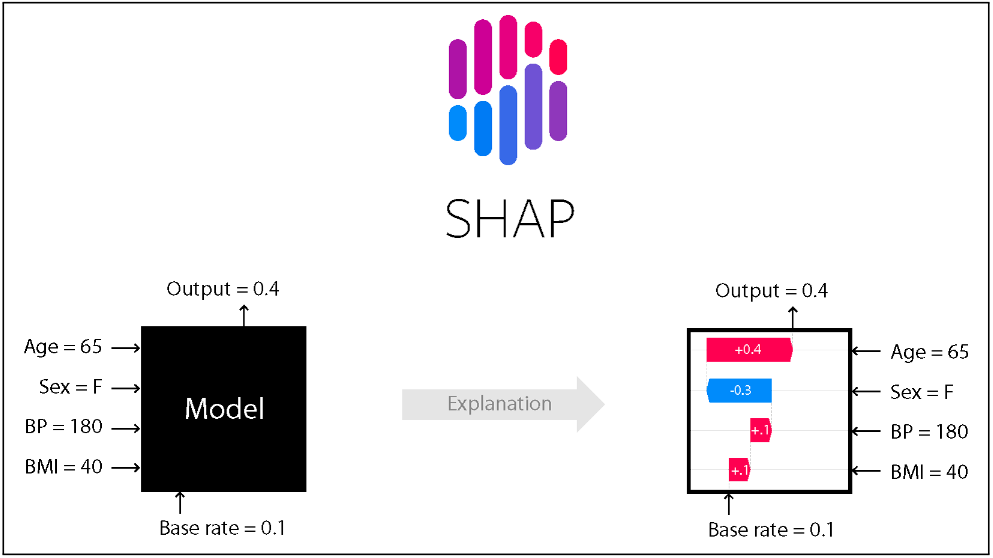
SHAP工作原理表示(图源论文)
由于看不清这种复杂的“纠缠关系”,传统方法往往只能给出模糊、甚至误导性的解释。而这项研究的目标,正是要验证量子计算是否能比传统模型更精准地抓取到这些驱动决策的“活性成分”。
02 经典 AI与量子 AI:一场关于“信任”的技术对决
研究团队选取了一个经典且非常适合“看清内部机制”的任务:识别手写数字中的“0”和“1”。这个问题足够简单,不会被复杂语义干扰;同时又足够真实,能反映模型在做出判断时究竟关注了哪些信息。

MINIST数据集(图源论文)
为了让实验更加严谨,研究团队并没有直接将整张图像(28×28 像素)丢给 AI。为了适配当前量子硬件的限制并减少计算开销,他们先引入了一道名为 PCA(主成分分析)的关键预处理程序,将原本复杂的 784 维图像数据压缩成了 4 个最核心的维度(记作 PC0 到 PC3)。
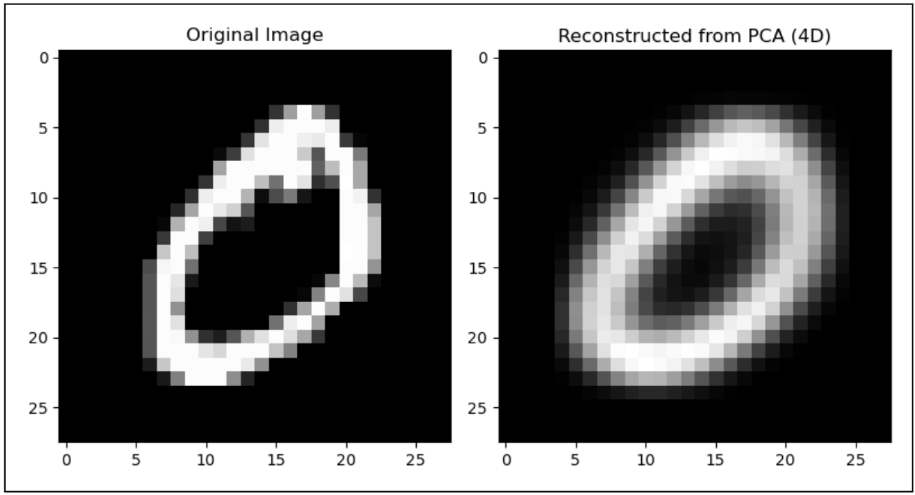
数据集中“0”数据的降维前后(图源论文)
可以把这一步理解为:在一副杂乱的拼图中,先提炼出最关键的四条线索,再让模型据此做判断。
随后,研究团队在相同的训练条件下,训练了两种思路截然不同的模型:
· 经典方:受限玻尔兹曼机(RBM)
这是一种典型的能量模型,其可见层由 4 个节点组成(对应 4 个 PCA 特征),隐藏层则包含 2 个二进制随机单元。它代表了我们熟悉的经典机器学习思路:通过对比散度(Contrastive Divergence)算法不断调整内部权重,学习数据的隐藏结构与不确定性。
· 量子方:量子玻尔兹曼机(QBM)
这是一种将量子电路与经典神经层结合的混合模型。研究者通过 RY 旋转门(角度嵌入)将提炼出的 4 个特征编码进 4 个量子比特中,再利用包含 CNOT 门的强纠缠层,将这些特征在一个高度关联的量子空间中“绑”在一起。模型最终通过测量每个量子比特的 Pauli-Z 算子期望值来提取量子特征,并传回经典层进行分类。这种机制让模型能够利用量子并行性,在更丰富的状态空间中同时探索多种特征组合。
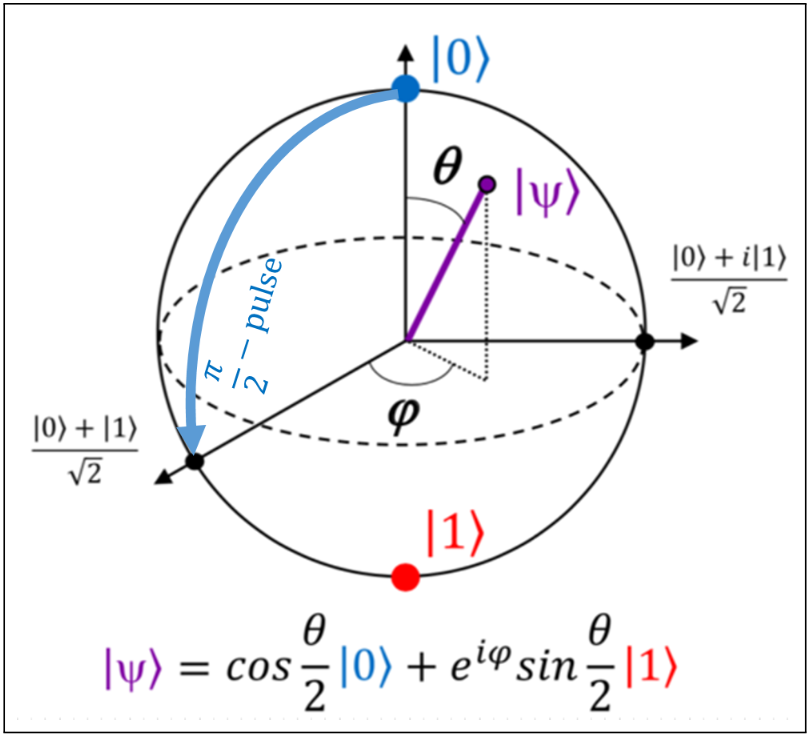
使用布洛赫球表示法可视化一个量子比特(图源论文)
尽管内部机制不同,但双方的目标完全一致:尽可能准确地区分手写数字 0 和 1。经过 50 个训练轮次,实验结果很直观:量子模型更准,也更“专注”。
准确率方面,量子模型(QBM)明显领先,正确率达到了 83.5%,展现出了强大的特征捕捉能力;而经典模型(CBM)仅为 54.0%,在缩减了维度的数据面前表现得有些捉襟见肘。
但真正让研究者兴奋的,是两者“解释理由”时的巨大差异:量子模型知道自己在“看什么”。
· 经典模型如同在“撒网”
研究团队在使用 SHAP 工具分析模型的决策依据时发现,经典模型的注意力平均分散在四个维度上,没有哪个特征能占据主导地位,这是因为 SHAP 假设特征相互独立,但 CBM 的节点往往紧密互联,存在大量联合特征交互,导致解释变得模糊,这种模糊性在 1.38 的高熵值中体现得淋漓尽致。
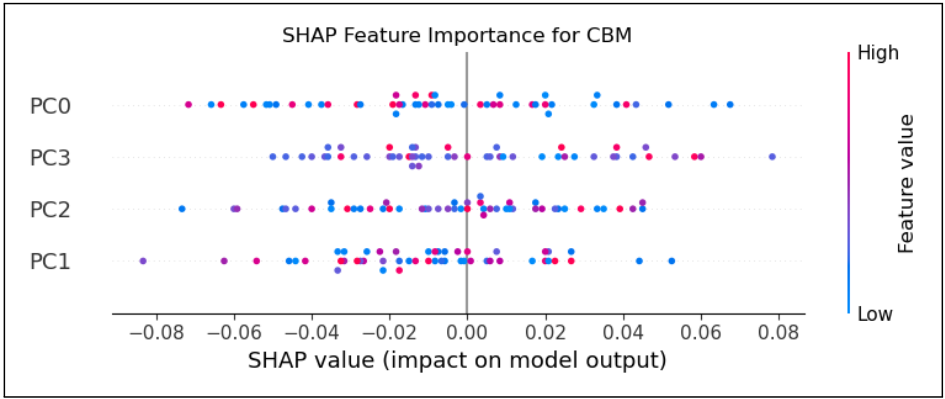
CBM的SHAP特征归因:没有哪个单一特征能完全主导模型的决策过程(图源论文)
· 量子模型则在“精准狙击”
通过对梯度显著图(Saliency Maps)所反映的特征关注集中程度进行量化分析,研究发现量子模型的特征分布熵值仅为 1.27,这意味着它的注意力高度集中,只依赖少数几个关键特征来做判断,明确锁定了 PC0 和 PC2 作为决策的“活性成分”。
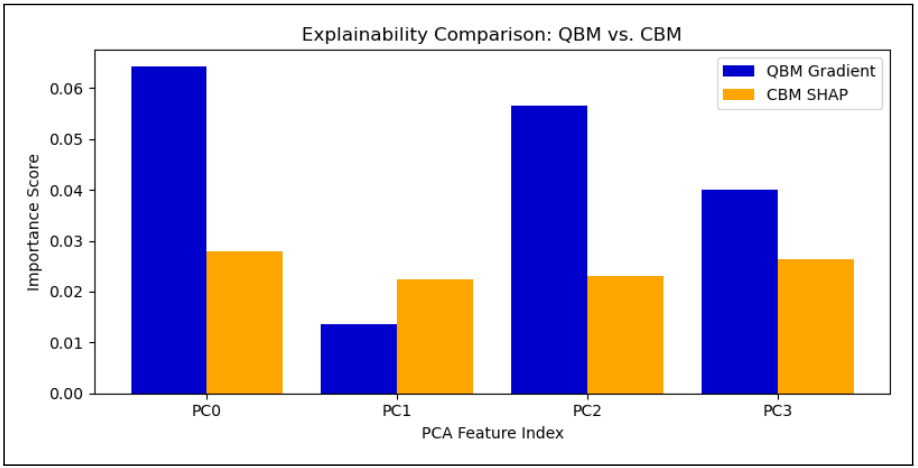
QBM梯度与CBM SHAP的对比图:QBM明显更重视PC0和PC2(图源论文)
为了进一步证明量子模型的“清醒”,研究团队利用 t-SNE 算法对模型的隐藏状态进行了降维观察,可视化结果令人惊叹:在量子潜空间里,“0”和“1”被清晰地分成了两个几乎没有重叠的簇(Clusters)。
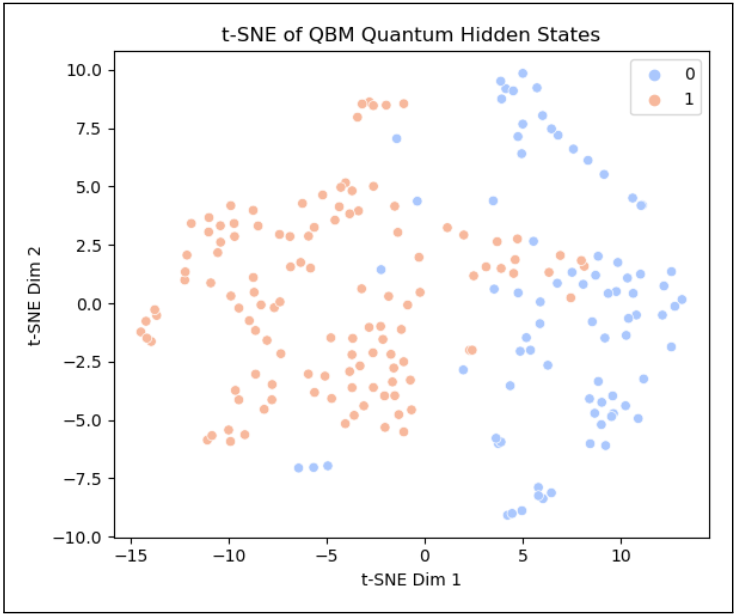
量子隐藏态的t-SNE可视化(图源论文)
这意味着量子模型不仅能告诉你答案,还能理直气壮地给出解释:
“我之所以这么判断,是因为我敏锐地捕捉到了 PC0 和 PC2 这两个关键活性成分,它们在我的量子场中边界清晰,绝不混淆。”
03 量子 AI:通往“可信人工智能”的直梯
长期以来,AI 领域存在一种近乎“公理”的无奈:模型越复杂,就越难解释。性能和可解释性就像鱼与熊掌,难以兼得。
但这项研究给出了一个颠覆性的信号。量子计算并非简单地通过增加参数让 AI 变得更臃肿,而是通过一种完全不同的信息处理方式,让模型在内部形成更清晰的结构。
该项研究结果令人振奋:模型不仅更强(准确率从 54% 跃升至 83.5%),而且由于其内部形成的“量子能量景观(Quantum Energy Landscape)”更具判别性,决策过程反而变得更容易被理解了。这对于未来的 AI 应用意义重大。
在医疗中,这意味着 AI 不仅能给出诊断,还能依据其捕捉到的“全局重要模式”,告诉医生哪些临床特征是真正的“活性成分”;在金融与法律等高风险领域,这意味着算法能够识别出那些被传统工具(如 SHAP)所忽略或过度简化的微妙特征交互,从而提供更实质性的透明度。
相比于传统工具假设特征之间彼此独立,量子方法通过梯度分析,展现了一种“全局式”的解释能力,它能看清特征之间是如何像量子比特一样“纠缠”在一起共同影响结果的,而不再是像 SHAP 那样由于无法处理紧密互联的特征交互而给出模糊的属性分配。

图源网络
尽管这项研究目前仍处于早期阶段,为了适配当前量子硬件的限制,研究者使用了 PCA 技术将数据简化到了 4 个主成分,并主要在模拟环境中运行,但它展示了一条非常重要的思路:未来的 AI,不一定只靠堆叠海量数据和参数,而可能依赖更“聪明”的计算范式。
研究团队已经明确了下一步的方向:
1.挑战复杂数据:将该方法应用于更复杂、维度更高的数据集。
2.进化电路结构:进一步改进量子电路的拓扑结构以提升效率。
3.构建混合系统:尝试将量子与经典的解释技术融合,打造混合可解释人工智能(Hybrid XAI)系统。
人工智能的发展,正在从“能不能做到”,走向“能不能被理解”。这项关于量子玻尔兹曼机的研究证明了:真正先进的 AI,不只是给答案,而是能以一种更集中、更清晰的方式说明理由。值得注意的是,这种以玻尔兹曼结构为核心、结合量子机制的研究路径,并非孤立的学术探索。国际上,D-Wave已围绕QBM布局,国内领军量子计算企业玻色量子也发布了自研量子玻尔兹曼机及开源编程套件,这意味着QBM在全球范围内正走向实际使用阶段。
如果传统 AI 是一个沉默寡言的天才,那么量子 AI 正展现出一种天赋:它能够利用量子力学的底层逻辑,把纷乱的决策依据梳理得井井有条。当 AI 能够像人类专家一样清楚解释“判断依据”,信任的基石才算真正奠定。
而这,可能正是下一代人工智能最重要的能力之一。
Reference:
1、https://arxiv.org/abs/2601.08733
2、https://quantumzeitgeist.com/83-5-percent-ai-accuracy-explainable-achieves-quantized-active-ingredients/
文章转载自微信公众号:量子前哨
原文链接:https://mp.weixin.qq.com/s/RYtBDTuRBJ3Gw8BA3nQLwA | 





















