
一个让人惊叹的数学巧合
2020年,一篇来自奥地利约翰内斯·开普勒大学的论文在人工智能领域引发了广泛关注。论文的核心结论简单到让人有些不敢相信:Transformer模型里那个大名鼎鼎的Self-Attention机制,和一种诞生于1980年代的古老神经网络——霍普菲尔德网络——的记忆检索过程,在数学上是等价的。
等价。不是"有些相似",不是"存在联系",而是严格的数学等价。
这个结论就好像你突然发现,自己每天用来导航的地图App,其底层算法和某位十九世纪数学家在信封背面随手推导的公式,居然是同一件事情。历史的暗线悄然浮出水面,让人不禁感叹:数学的世界里,真正的好思想从不会真正消失,它只是在等待合适的时机,以另一种面貌重新登场。
要理解这件事究竟有多惊人,我们需要先分别认识这两位"主角":霍普菲尔德网络和Transformer的Self-Attention。然后,我们再来看清楚那条将它们秘密联结在一起的数学纽带。
第一位主角:霍普菲尔德网络与"联想记忆"的梦想
时间回到1982年。物理学家约翰·霍普菲尔德在《美国国家科学院院刊》发表了一篇在当时看来颇具革命性的论文,提出了后来以他名字命名的神经网络模型。
霍普菲尔德的出发点,是一个极其朴素却又深刻的问题:人类的记忆究竟是如何工作的?
想象这样一个场景:你的朋友给你发来一张模糊的老照片,照片里的人只露出了半张脸,背景也已经褪色得看不清楚了。但你看了一眼,几乎立刻就认出来了——这是你小学时候的班主任。你的大脑不需要一个完整的、高清的"索引",它能够从残缺的片段中,自动"补全"并检索出完整的记忆。
这种能力,在神经科学里有个专门的术语,叫做"联想记忆"(Associative Memory)。它的神奇之处在于,记忆的提取是由内容驱动的,而不是由位置驱动的。你不需要知道这段记忆"存在大脑的第几排第几列",你只需要给出一个相关的线索,大脑就能帮你把剩余的部分找出来。
霍普菲尔德想用数学来模拟这个过程。他构建了一个由许多神经元互相连接的网络,这些神经元的状态只有两种:激活(+1)或抑制(-1)。每两个神经元之间都有一个连接权重,这个权重决定了它们之间的"相互影响"有多强。
但真正让这个模型变得精彩的,是霍普菲尔德引入了一个物理学中的概念——能量。
他为整个网络定义了一个能量函数,其形式是一个关于所有神经元状态的二次型函数。这个函数的数值取决于网络中所有神经元当前的状态,以及它们之间的连接权重。当你把一个"残缺的记忆片段"输入网络,网络会按照一定的规则不断更新每个神经元的状态,而每一次更新,都会使整个系统的能量降低一点点。这个过程会一直持续,直到系统找到一个能量无法再降低的状态——也就是所谓的"局部能量最小值"——然后停下来。
这个最终停留的状态,就是网络给出的"记忆检索结果"。
这里有一个精妙的物理比喻可以帮助理解。想象一个崎岖不平的山地地形,地形上有几个盆地,每个盆地的最低点代表一段被存储的记忆。现在你把一个小球放在这个地形的某个地方——这个初始位置代表你给出的"残缺线索"。小球会在重力的作用下,顺着坡面滚动,最终落入某一个盆地的最低点。它滚入的那个盆地,就是与你的线索最相近的那段记忆。
能量函数定义了这片"山地"的地形,而存储进网络的记忆,则是那些盆地的位置。网络的"记忆检索"过程,本质上就是在这片能量景观(energy landscape)上寻找最低点。
这个想法在当时令人耳目一新,因为它把物理学中的统计力学和神经网络优雅地联系了起来。但经典霍普菲尔德网络也有它的局限性:存储容量相当有限。严格的理论分析表明,对于一个拥有N个神经元的网络,能够被可靠检索的模式数量大约只有0.138N——也就是说,一个有一万个神经元的网络,能稳定存储的记忆只有大约一千四百条,而且这个上限随神经元数量只是线性增长。这个瓶颈,在后来的数十年里,让经典霍普菲尔德网络逐渐淡出了主流研究的视野。
第二位主角:Transformer与Self-Attention的崛起
时间快进到2017年。谷歌的研究团队发表了一篇题为《Attention is All You Need》的论文,提出了Transformer架构。这篇论文的影响力之大,可以说彻底重塑了整个自然语言处理领域,并在此后的几年里,蔓延到了计算机视觉、语音识别乃至蛋白质结构预测等几乎所有人工智能子领域。ChatGPT、GPT-4、BERT、ViT……今天我们耳熟能详的那些AI明星,几乎无一例外都建立在Transformer的基础之上。
Transformer的核心机制,就是Self-Attention,中文通常翻译为"自注意力"。
要理解Self-Attention,先来想象你正在读一句话:"银行倒闭了,所有存款都没了。"当你处理"银行"这个词的时候,你的大脑会自动在这句话的上下文里搜寻相关线索——"倒闭"、"存款"——从而判断出这里的"银行"指的是金融机构,而不是河流的岸边。
Self-Attention机制做的事情,本质上与此类似。它让序列中的每一个元素(比如每一个词)都去"看"序列中所有其他元素,计算自己与其他元素的"相关程度",然后根据这些相关程度,对其他元素的信息进行加权汇总,从而形成自己的新的表示。
在数学上,这个过程是这样运作的:
对于输入序列中的每个元素,模型会生成三个向量:查询向量(Query,简称Q)、键向量(Key,简称K)和值向量(Value,简称V)。这三个名字来自信息检索领域的一个类比——想象你在用搜索引擎:你输入的搜索词是Query(查询),数据库里每个条目的标签是Key(键),条目的实际内容是Value(值)。你的查询会与所有键进行匹配,匹配程度高的条目,其值会被更多地"返回"给你。
具体计算时,Self-Attention先把Query矩阵和Key矩阵做点积,然后用一个缩放因子(通常是键向量维度dkd_kdk的平方根)去除,再经过Softmax函数,得到一组权重。这组权重反映了"每个位置的查询与每个位置的键有多匹配"。最后,用这组权重对Value矩阵进行加权求和,就得到了每个位置的输出。
写成公式就是:
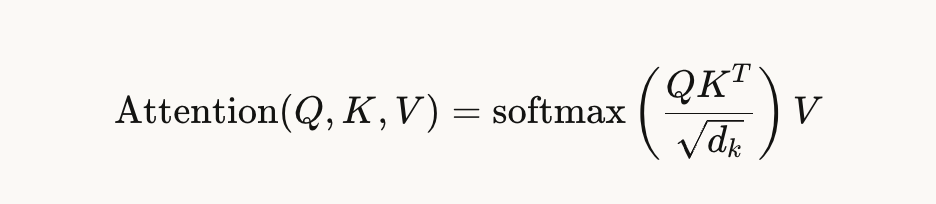
这个公式看起来可能有些抽象,但它的直觉非常清晰:对于序列中的每一个"查询"元素,计算它与所有"键"元素的相似度,然后用这些相似度作为权重,对"值"元素进行加权平均,得到该查询的输出。
Transformer之所以如此强大,很大程度上得益于Self-Attention的全局性:无论两个词在序列中相隔多远,Self-Attention都能直接捕捉到它们之间的关系,不需要像循环神经网络那样,信息必须一步一步地"传递"才能跨越距离。这种一步到位的全局感知能力,让Transformer在处理长序列时展现出了无与伦比的优势。
现代霍普菲尔德网络:让古老的模型焕发新生
现在,让我们回到2020年的那篇论文。但在此之前,有必要交代一段重要的前史。
早在2016年,物理学家迪米特里·克罗托夫和约翰·霍普菲尔德本人就已经联手提出了"稠密联想记忆"(Dense Associative Memory)的概念,这是现代霍普菲尔德网络思想的直接源头。他们把经典模型中的二次型能量函数替换为多项式或更高阶的相互作用函数,证明了存储容量可以随神经元数量超线性地增长。这个想法随后又被德米尔奇吉尔等人(Demircigil et al., 2017)进一步推进,他们引入了指数型的相互作用函数,让离散版本的存储容量达到了指数量级。
然而,这些早期的现代化工作都局限于离散(二值)状态的神经元,难以直接整合进依赖连续可微运算的深度学习框架。这正是2020年的论文要解决的核心问题。
Ramsauer等研究者们的关键贡献,是把这套现代化的能量函数体系推广到了连续状态的情形,并为新的能量函数推导出了一套有理论保证的、全局收敛的更新规则。他们证明,这个推广到连续状态的现代霍普菲尔德网络,可以在向量的维度d呈指数量级地存储模式(而非像经典网络那样只能线性地存储0.138N个模式),同时具有指数级小的检索误差。这里有一个重要的前提条件需要说明:这个指数级容量的成立,要求存储的模式之间具有足够的分离度——如果大量模式高度相似、彼此混淆,检索性能仍会受到影响。容量与模式间的分离性之间存在权衡,并不是说存储能力可以无限扩张。
但论文中真正让整个人工智能社区为之震动的发现,发生在他们推导连续状态现代霍普菲尔德网络的单步更新规则时。
数学等价性的真相:两条路,同一个终点
当你把一个初始状态输入现代霍普菲尔德网络,网络会按照"能量梯度下降"的原则,迭代更新状态,直到收敛到能量最小值。论文的一个关键定理表明:对于连续状态的现代霍普菲尔德网络,这个迭代过程通常只需要一步就能收敛到充分接近正确模式的位置。
而当你把这个单步更新规则写出来,你会看到什么?你会看到一个Softmax函数,作用在查询与所有存储模式的点积上,然后对所有存储模式进行加权求和。
换句话说,这个单步更新规则在数学形式上与Transformer的Self-Attention公式完全对应。
为了让这个等价性说得更清楚,我们需要明确对应关系的具体细节。在这个等价关系中,存储的记忆模式对应于Transformer的Key矩阵;用来检索的"查询状态"对应于Query向量;Value矩阵则存储着检索后实际输出的内容。在最基本的情形下(Key矩阵和Value矩阵相同,即K=V),等价关系最为直接清晰。在实际的Transformer实现中,K和V分别经过不同的线性投影得到,理论框架需要相应扩展,但等价性的本质结构依然成立。此外,Transformer中常见的多头注意力(Multi-Head Attention)结构,在这个框架下可以理解为多个并行的霍普菲尔德记忆模块同时运行,各自检索不同子空间中的模式。
还有一个关键的区别值得明确指出:Transformer的K、V矩阵是通过训练学习得到的,它们随着模型训练动态变化;而经典霍普菲尔德网络的记忆是一次性"写入"、静态存储的。这意味着Transformer的"记忆"不是固定编码的,而是在不断的梯度下降中涌现出来的分布式表示——这是两者在机制上一个根本性的不同,尽管它们的信息检索逻辑在数学结构上高度吻合。
这种情形有点像是两位建筑师,一位从山的南坡开凿隧道,另一位从山的北坡开凿,双方各自按照自己的测量和规划推进,结果在山体内部的某一点,两条隧道精准地对接在了一起。这种巧合,不是真的"巧合",而是在暗示:隧道穿越的那座山,有它自己内在的、不以人的意志为转移的结构。数学的内在结构,让两条不同的探索路径,指向了同一个真相。
能量模型的幽灵,如何渗入Transformer的内核
理解了等价性之后,我们可以从一个更宏观的视角来欣赏这件事的深刻含义。
Transformer的Self-Attention,本质上是在执行一次基于内容的记忆检索。每一次注意力计算,都是在问:"在当前的上下文中,哪些信息最相关?"然后把最相关的信息汇聚起来,形成对当前位置的新理解。
这,不正是联想记忆的精髓所在吗?
霍普菲尔德网络的哲学核心是:记忆不是通过地址索引来访问的,而是通过内容相似度来检索的。你给出一个不完整的模式,系统把它"补全"为与之最相近的一个存储模式。Transformer的每一个注意力头,都在做同样的事情,只不过它的"存储器"是Key-Value矩阵,它的"查询"是Query向量,而它的"检索"过程被压缩成了单步的Softmax运算。
从统计力学的角度来看,Softmax函数与玻尔兹曼分布(Boltzmann distribution)存在精确的对应关系。

所以,当我们说"能量模型的思想以一种更隐蔽的方式渗透进了Transformer的内核",这句话的意思是:Transformer并不显式地定义能量函数,也没有迭代地寻找能量最小值。但它的每一次前向传播,都在完成一次与能量最小化等价的记忆检索操作。能量的思想,像一条隐形的线,穿过了Transformer的每一层,编织在它的基本运算逻辑之中,只是没有人明确地用这个语言来描述它。
这就好比说,你每次用力推开一扇门,你都在无意识地运用着牛顿第三定律。你不需要知道这个定律,也不需要在脑海里推导受力分析,但那个定律就是在悄无声息地支配着你的每一个动作。Transformer的设计者们,在某种意义上,"无意中"发现了能量最小化在记忆检索上的一种高效实现方式。
更大的图景:统一视角下的神经网络
现代霍普菲尔德网络与Transformer之间的等价性,不仅仅是一个有趣的数学发现,它还为我们理解深度学习中的许多现象提供了新的视角。
首先,它解释了注意力机制为什么有效。
长久以来,研究者们从直觉上理解注意力机制——"模型在关注最重要的部分"——但这种直觉性的解释缺乏深度。现代霍普菲尔德网络给了我们一个更扎实的理论支撑:注意力机制之所以有效,是因为它在执行一种高效的联想记忆检索。模型存储了大量关于语言、图像或其他数据的"模式",在每次推理时,它根据当前的上下文从中检索最相关的模式,并以此为基础生成下一步的输出。这不是玄学,这是有物理直觉支撑的内容寻址记忆。
其次,它打开了一扇连接不同理论体系的窗户。
在现代霍普菲尔德网络的框架下,我们可以把Transformer的训练过程理解为一种探索性解读:模型可能在逐步调整其等效的"能量景观",使得那些与任务相关的检索模式变得更加稳健,而无关的模式则逐渐被抑制。需要指出的是,这是一种具有启发性的理论诠释框架,而非已被实验充分验证的结论;将这种解读与梯度下降的实际行为精确对应,仍是一个开放的研究问题。但这个视角的确把深度学习与统计力学、热力学之间的桥梁变得更加清晰可见。玻尔兹曼机(Boltzmann Machine)、受限玻尔兹曼机(RBM)、变分自编码器(VAE)……这些模型都在用不同的方式处理同一个问题:如何用能量函数来描述数据的分布,如何通过最小化能量来实现有效的表示学习。
Transformer现在也加入了这个家族——虽然是以一种出乎意料的、低调的方式。
第三,它带来了实际的工程启发。
理解了Self-Attention与霍普菲尔德网络的等价性之后,研究者们获得了一些新的工具来分析和改进Transformer。例如,霍普菲尔德网络的理论可以帮助我们估计一个给定规模的Transformer模型大概能"记住"多少种模式,可以帮助我们分析模型在什么情况下会出现检索混淆(在霍普菲尔德框架中,这对应于网络收敛到了"中间态"或多个模式的平均,而非某个单一的存储模式)。这种混淆现象与Transformer产生模糊或不确定输出之间存在一定的概念联系,但它和大语言模型中更复杂的"幻觉"现象不能简单画等号,后者涉及训练目标、数据分布等多方面因素,是一个独立的研究课题。
事实上,正是基于这种理解,Ramsauer等人设计了专门的Hopfield层,并将其应用于计算生物学领域,在免疫组库分类(immune repertoire classification)这一多实例学习问题上取得了超越当时最优水平的成绩。该任务涉及对每个个体数十万条免疫受体序列的分析,现代霍普菲尔德网络的高存储容量在此展现出了切实的优势。理论与应用,以一种意想不到的方式实现了交汇。
这个故事还有一个值得细细咀嚼的层面,那就是科学发现的本质。
霍普菲尔德在1982年提出他的网络时,计算机还没有强大到可以运行大规模神经网络的程度。他的工作更多是一种理论上的探索,试图用数学语言来捕捉大脑记忆的某种本质。那个年代,这类工作被称为"联结主义"(Connectionism),与当时主流的符号人工智能(Symbolic AI)分庭抗礼。
后来,联结主义随着反向传播算法和深度学习的崛起,逐渐走向台前。但霍普菲尔德网络本身,因为存储容量的限制,并没有直接演化成现代深度学习的主流组件。然而,霍普菲尔德本人并未停止探索——2016年,他与克罗托夫合作,亲手启动了这一理论的现代化历程,拉开了从稠密联想记忆到与Transformer建立联系的整条思想链条。
当Transformer在2017年以一种完全工程化的视角被设计出来时,它的设计者们并没有明确意识到,他们实际上在功能上重新实现了一种能量最小化的记忆检索机制,只不过用的是一套更现代、更高效的数学语言。
这种"殊途同归"在科学史上并不罕见。微积分被牛顿和莱布尼茨各自独立发明;非欧几何由鲍约(Bolyai)和罗巴切夫斯基(Lobachevsky)各自独立发展(高斯虽然更早形成了相关思想,但从未正式发表,主要见于私人信件);进化论被达尔文和华莱士同时提出……这些案例一再表明:当时机成熟,真正深刻的思想往往会以多种面目同时浮现,因为它们反映的,是某种客观存在的、不以个人意志为转移的数学或自然规律。
现代霍普菲尔德网络与Transformer的等价性,也可以作如是观。Self-Attention和霍普菲尔德记忆检索之所以殊途同归,是因为它们都触碰到了同一个更深层的问题:如何高效地实现基于内容的记忆检索? 这个问题有它自己的"最优解的数学形态",无论你从哪个方向接近它,最终都会看到同一个答案的影子。
这给我们一个很重要的启示:理解一个工具的数学本质,往往比单纯地"会用"这个工具更有力量。当你理解了Self-Attention与能量最小化的深层联系,你对Transformer的理解就不再是"这个公式是这样的,我按照它来做就行了",而是"这个机制在做一件物理上有意义的事,它的行为受到某些深层的约束和规律的支配"。这种理解,会让你在面对新问题时,更有能力提出有根据的假设,而不只是盲目地调参试错。
记忆、能量与智能:一个更宏大的叙事
让我们把视野再拉开一些,站在一个更高的位置来看这整件事。
大脑是如何工作的?这是人类智识史上最古老也最困难的问题之一。神经科学、认知科学、人工智能,三个领域的研究者们各自从不同的角度接近这个问题,使用着各自的语言和工具。
但有一个主题,在这三个领域中反复出现,那就是:记忆与注意力的交互,是智能行为的核心。
人类的认知并不是把感知到的所有信息一视同仁地处理,而是通过注意力机制,有选择地把资源集中在最相关的信息上;同时,通过联想记忆,把当前的输入与过去的经验关联起来,从而实现理解、推理和预测。
霍普菲尔德网络,是人们用数学模型来模拟联想记忆的一次早期尝试。Transformer的Self-Attention,是人们在解决实际工程问题(机器翻译、语言建模)的过程中,独立地发现的一种高效的信息聚合机制。两者的殊途同归,在某种程度上暗示:无论你是在试图模拟大脑,还是在试图解决工程问题,当你的目标是实现智能的信息处理时,某种形式的基于内容的记忆检索,几乎是不可避免的。
这是一个令人振奋的想法,因为它意味着,现代人工智能中那些最成功的结构,并不只是碰运气凑出来的,它们反映了某种更深层的关于智能信息处理的必然规律。
当然,今天的Transformer与真正的大脑记忆机制之间,仍然有着巨大的鸿沟。真实的神经记忆远比霍普菲尔德模型复杂,涉及突触可塑性、海马-皮层相互作用、睡眠中的记忆巩固等一系列我们还远未完全理解的机制。Transformer也有它自己的局限性,比如上下文窗口的限制、计算成本随序列长度的二次方增长等。
但方向是对的。数学工具在不断成熟,理论与实践之间的对话在不断深化。每一次像"现代霍普菲尔德网络与Transformer等价"这样的发现,都是这场漫长对话中的一个重要节点,让我们对"智能是什么"这个问题的理解,又清晰了一点点。
相关主要论文链接
以下是文章所涉及的核心论文,按思想发展的时间脉络排列:
① 经典霍普菲尔德网络的奠基论文(1982)
Hopfield, J. J. — Neural networks and physical systems with emergent collective computational abilities
发表于《美国国家科学院院刊》(PNAS),1982年
https://www.pnas.org/doi/10.1073/pnas.79.8.2554
(可免费阅读全文的PubMed镜像:https://pmc.ncbi.nlm.nih.gov/articles/PMC346238/)
② 现代霍普菲尔德网络的思想前身:稠密联想记忆(2016)
Krotov, D. & Hopfield, J. J. — Dense Associative Memory for Pattern Recognition
发表于 NeurIPS 2016
🔗 arXiv预印本:https://arxiv.org/abs/1606.01164
🔗 NeurIPS官方页面:https://proceedings.neurips.cc/paper_files/paper/2016/hash/eaae339c4d89fc102edd9dbdb6a28915-Abstract.html
③ 指数型相互作用函数与指数级存储容量的严格证明(2017)
Demircigil, M. et al. — On a model of associative memory with huge storage capacity
发表于《统计物理学杂志》(Journal of Statistical Physics),2017年
arXiv预印本:https://arxiv.org/abs/1702.01929
④ Transformer原论文(2017)
Vaswani, A. et al. — Attention Is All You Need
发表于 NeurIPS 2017
arXiv预印本:https://arxiv.org/abs/1706.03762
NeurIPS官方页面:https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
⑤ 现代霍普菲尔德网络与Transformer等价性的核心论文(2020/2021)
Ramsauer, H. et al. — Hopfield Networks is All You Need
首发于arXiv 2020年7月,正式发表于 ICLR 2021
arXiv预印本(最终版):https://arxiv.org/abs/2008.02217
CLR 2021 OpenReview页面:https://openreview.net/forum?id=tL89RnzIiCd
代码库(PyTorch实现):https://github.com/ml-jku/hopfield-layers
| 





















