案例解析:均衡传播算法
均衡传播算法借鉴生物神经网络的局部学习规则,通过模拟大脑突触的双阶段动态平衡,使玻尔兹曼机等能量模型摆脱传统对比散度的低效束缚。这种“神经动力学+概率建模”的耦合,不仅为生成式AI提供了更接近生物学习范式的训练框架,更在量子退火硬件上展现出指数级加速潜力,有望推动更高效、节能的神经计算硬件的发展。
本节将以均衡传播算法为例,讲述量子计算在人工智能领域的应用与创新。
附视频讲解: 均衡传播与CIM驱动的神经网络创新应用
1. Ising模型
1.1 伊辛模型的基本概念
Ising模型最初是为解释铁磁相变现象提出的经典物理模型。其核心结构由二维晶格上的离散自旋系统构成:每个晶格节点
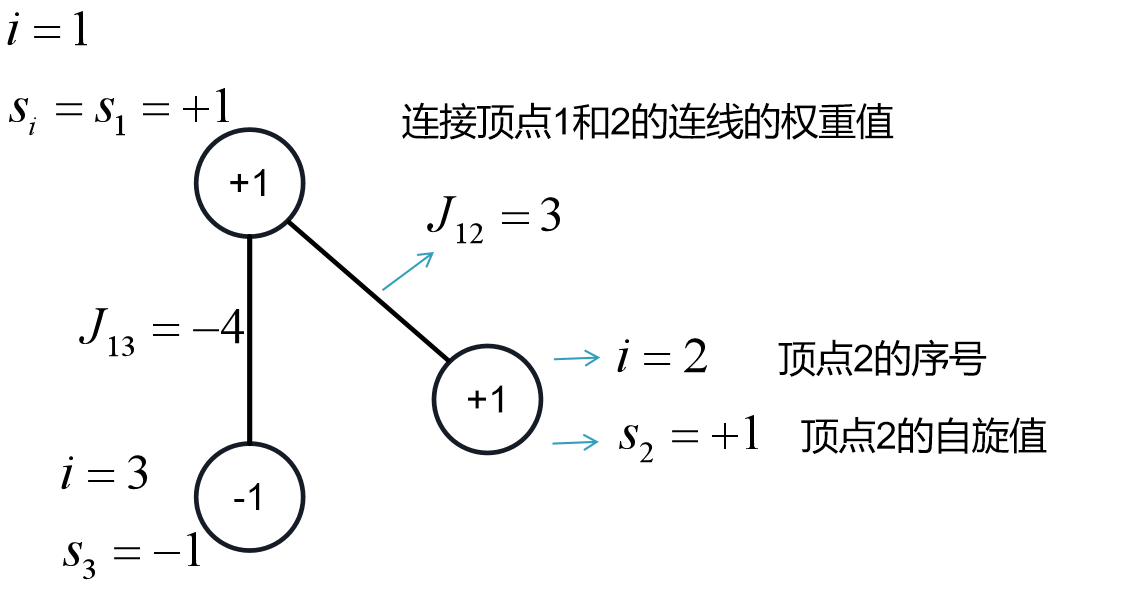
以图示的三节点系统为例:节点
1.2 伊辛模型与神经网络
Ising模型是一个有着广泛应用的模型,我们来看一下它和神经网络之间的一些联系。Ising模型的自旋演化机制与神经网络神经元更新规则存在深刻关联。在Ising系统中,相邻自旋通过耦合作用相互影响:
当耦合系数
若输入神经元激活值为
实际上,Ising模型的求解是很困难的,属于NP-hard组合优化问题,传统算法面临指数级复杂度挑战。本文后面将详细讨论Ising模型的高效求解方案——相干伊辛机(Coherent Ising Machine, CIM)。2018年《Science》报道的CIM突破性研究显示,CIM的光学计算架构在求解2000自旋问题时,速度较经典模拟退火算法提升近两个数量级,为复杂优化问题提供了物理计算的新的解决方案。
2. 均衡传播
2.1 均衡传播与反向传播
为深入理解均衡传播(Equilibrium Propagation, EP)的创新性,需系统对比其与传统反向传播(Backpropagation, BP)的算法差异。传统反向传播算法需要构建完整的计算图,通过链式法则将输出端的误差信号逐层逆向分解,每个神经元的权重更新都严格依赖于后续层的梯度信息:给定损失函数
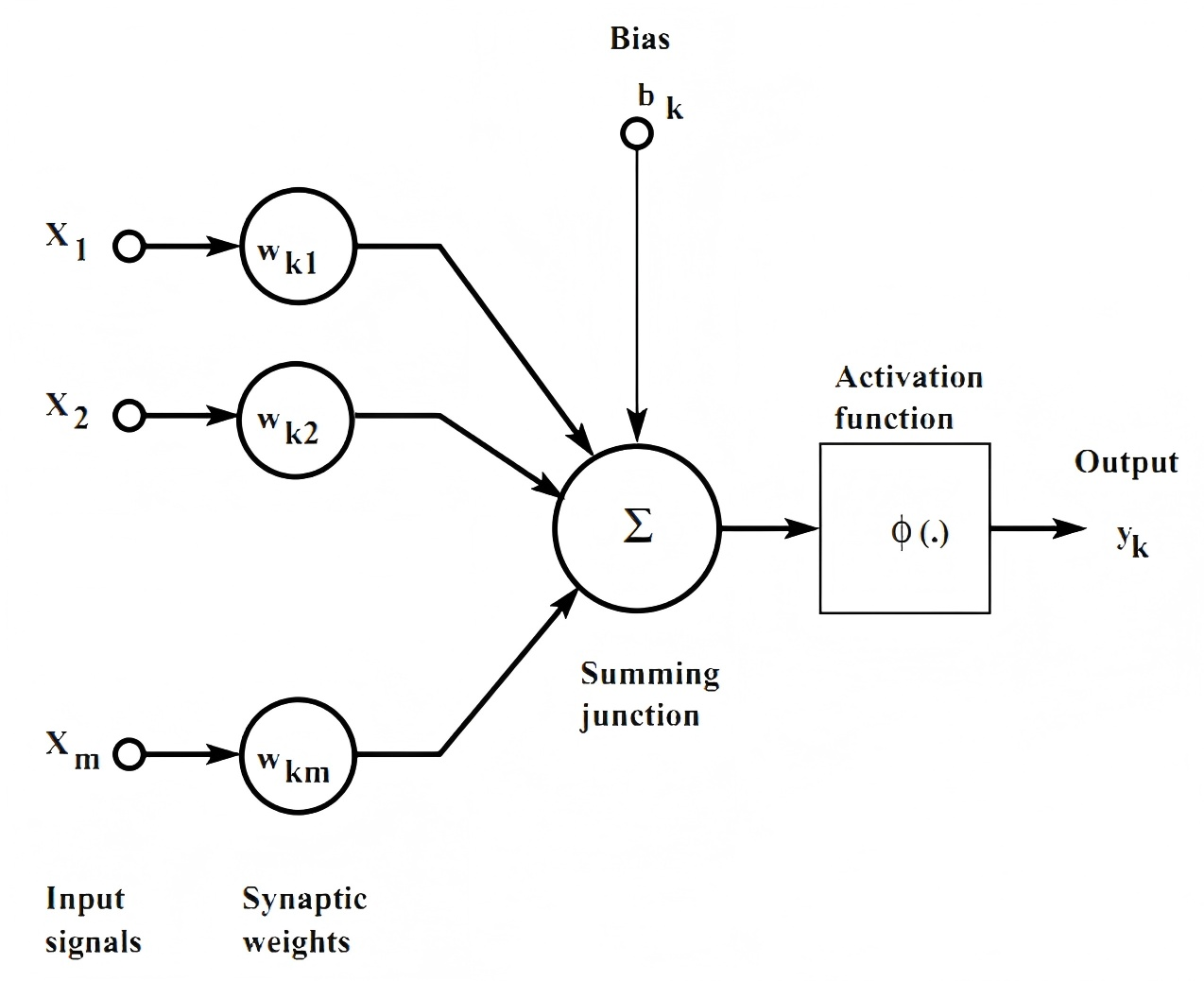
与反向传播相比,均衡传播具有如下图所示的优势。均衡传播建立在能量基模型(Energy-Based Models, EBMs)框架下,将网络视为动态系统,其状态演化由能量函数

2.2 均衡传播的训练过程
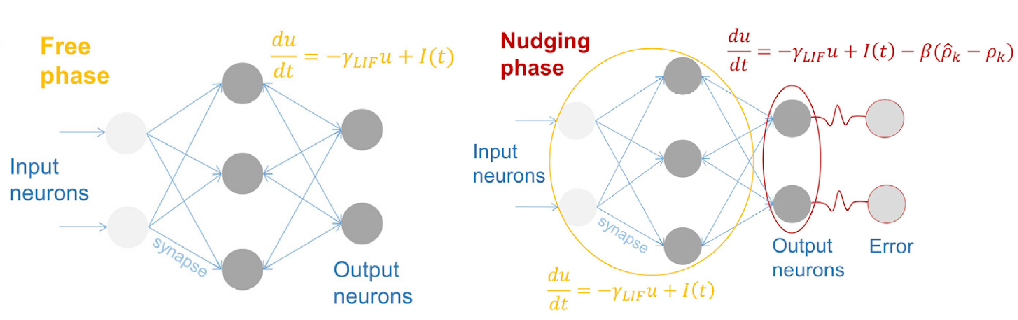
均衡传播的训练过程主要分为四个阶段:初始化参数、自由阶段、约束阶段和更新权重阶段。
(1)初始化参数: 网络由节点(神经元或自旋变量)和连接权重构成,节点状态
(2)自由阶段(Free Phase): 系统在输入数据
节点状态遵循梯度动力学方程:
当
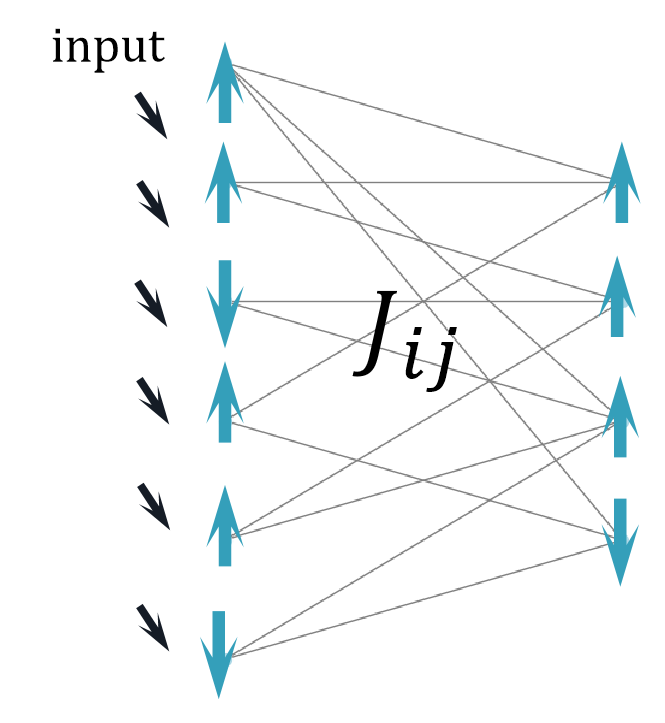
(3)引导阶段(Nudge Phase): 在自由阶段基础上,对输出层施加目标导向的约束,修正能量函数:
其中约束项
因此,其动力学方程为:
参数
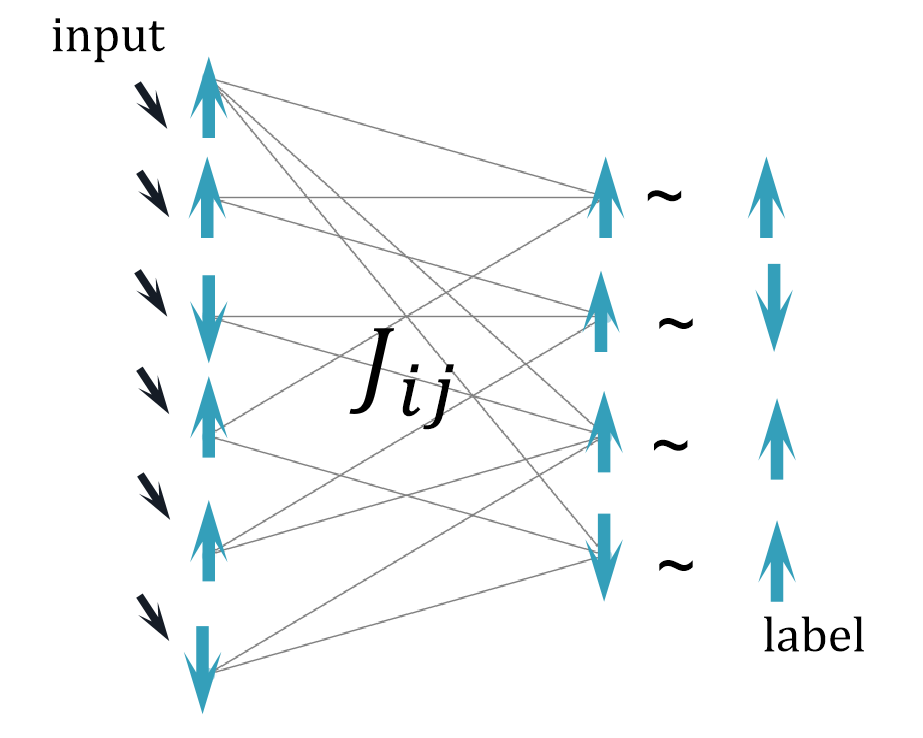
(4)参数更新: 通过对比两阶段的差异,计算梯度:
此规则仅依赖相邻节点的状态乘积差异,符合局部学习特性。权重更新方向使约束项
也就是说,尽管均衡传播仅利用局部信息,其梯度方向与反向传播的全局梯度一致,但规避了链式求导的计算开销。
数学注记: 上述结论源于对扩展能量泛函
的优化过程,通过交替求解
可导出参数更新量与损失函数梯度的一致性关系。
3. 均衡传播与CIM
3.1 借助CIM实现均衡传播
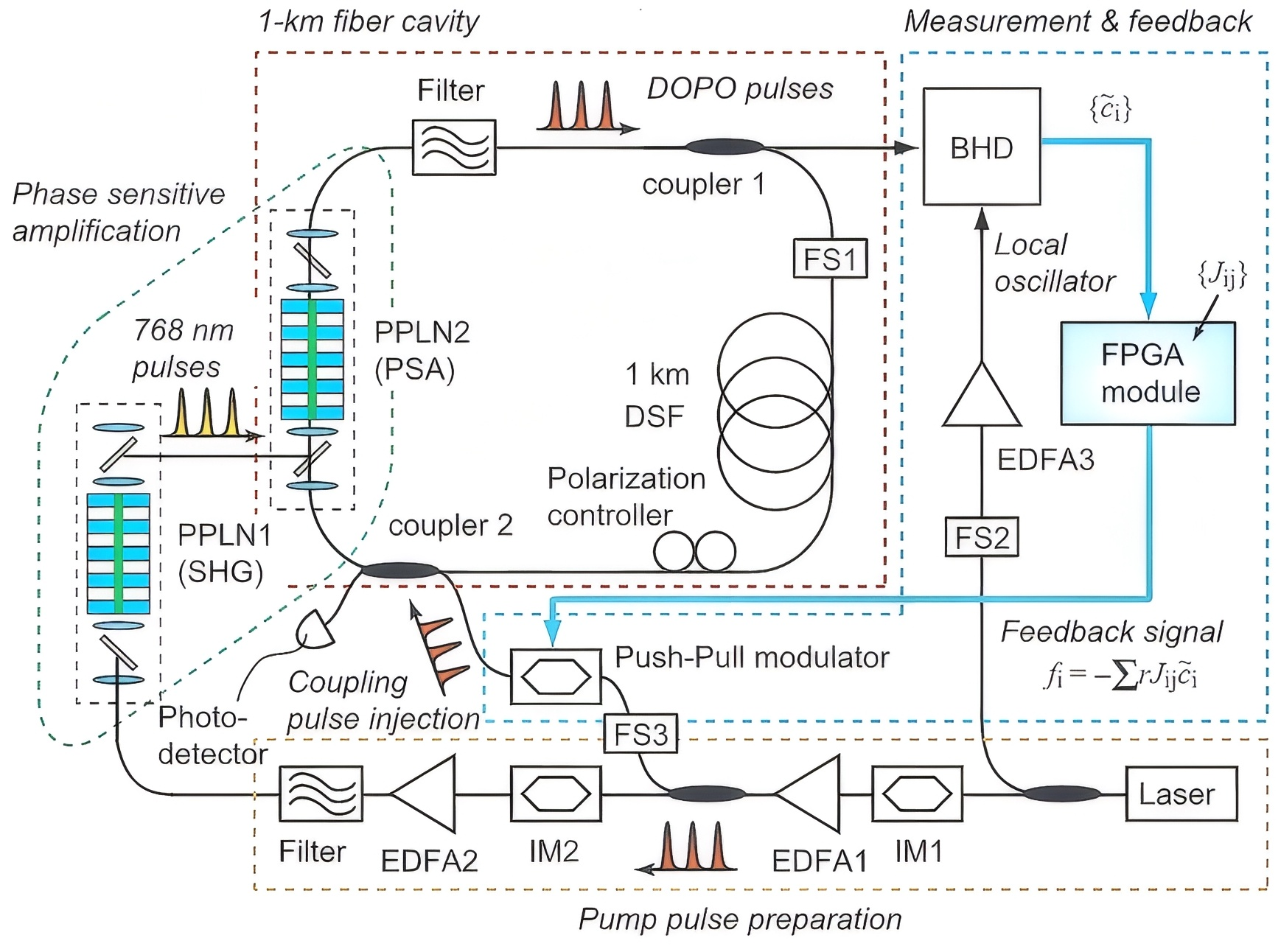
将均衡传播映射到CIM硬件实现时,需解决连续梯度与离散状态的适配问题。CIM通过物理系统的稳态演化实现均衡传播(EP):耦合权重
其中
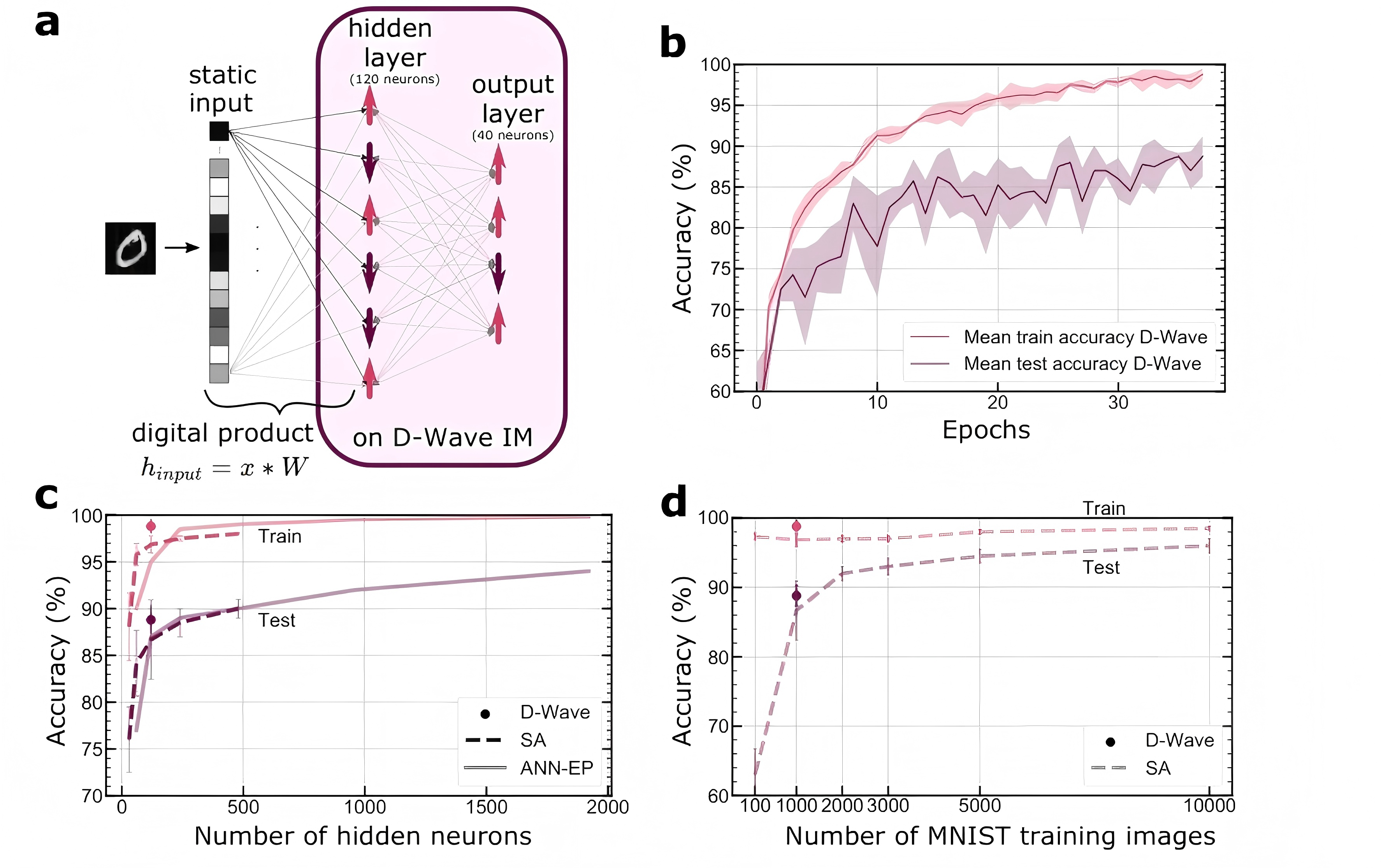
在CIM硬件上实现均衡传播的实证研究中,我们构建了面向MNIST手写数字识别的专用架构。输入层采用28×28=784个光学参量振荡器,其相位状态直接编码图像像素强度(
3.2 伊辛模型与玻尔兹曼机
玻尔兹曼机(BM)与均衡传播(EP)均以能量最小化为核心范式,但其建模目标与实现路径存在本质差异。玻尔兹曼机的概率分布定义为:
其中可见层
这一过程通过调整能量曲面使训练样本处于低能谷,本质上属于无监督特征学习。与之对比,均衡传播则构建监督学习导向的能量函数:
其中
二者的核心区别体现在:
| 维度 | 玻尔兹曼机 | 均衡传播 |
|---|---|---|
| 学习范式 | 无监督生成模型 | 监督学习框架 |
| 梯度估计 | 概率采样(MCMC) | 确定性平衡态差异 |
| 硬件适配性 | 需高温退火(模拟退火) | 直接利用Ising机基态搜索 |

3.3 实验架构与结果
本部分使用MNIST进行伊辛机实现均衡传播的实证研究。MNIST 数据集是机器学习和深度学习领域中最经典的基准数据集之一,由 Yann LeCun 等研究者于 1998 年创建,包含60,000个训练样本和10,000个测试样本,主要用于手写数字识别任务。每个样本是28×28像素的灰度图像,对应0到9的数字类别。

针对MNIST/100的子集(1000训练样本,100测试样本)构建专用架构:
- 输入层:28×28=784个光学参量振荡器,相位编码像素强度(
为墨迹, 为空白); - 隐层:120个可调谐耦合节点;
- 输出层:40节点扩展编码(每数字类别分配4节点)。
实验结果表明,EP算法在训练集上达到了98.8% 的准确率,在测试集上达到了88.8% 的准确率。
4. 应用与展望
4.1 均衡传播的应用
均衡传播(EP)的发展深度融合了硬件创新与算法优化,已经在跨学科领域展现独特优势。
图片生成 :结合均衡传播(EP)和Hopfield网络的变分自编码器(VAE)训练,用于生成建模任务研究利用Hopfield网络的对称性,设计了一个模型同时作为编码器和解码器。实验表明,该方法在生成图像质量上与传统反向传播训练的VAE相当。

神经网络模拟:均衡传播被用于训练脉冲神经网络(SNN),这是一种更接近生物神经网络的计算模型,将脉冲信号与能量最小化相结合。基于均衡传播的权重更新表现出尖峰时间依赖性可塑性(STDP),与生物学机制相契合。
4.2 均衡传播的展望
均衡传播(EP)作为一种基于物理系统的机器学习范式,其核心优势在于通过硬件与算法的深度协同实现高效训练。
在硬件加速领域,未来可进一步探索与光子、超导量子比特等新型计算架构的结合,突破传统冯・诺依曼瓶颈。
跨学科应用方面,EP的能量最小化机制与物理系统的自组织特性高度契合,可扩展至化学分子结构优化、热力学系统相变预测等领域。例如,在生物医学中,通过构建蛋白质相互作用的Ising模型,EP可高效求解蛋白质折叠问题,其离散状态特性恰好匹配生物分子的二态性特征,有望推动交叉学科的突破性进展。
算法改进层面,当前EP在梯度计算中依赖两阶段状态差异的近似(