基于专用量子计算的信用评分特征筛选方法
摘要:在金融行业中,信用评分是银行信贷业务的核心环节,它关系到银行贷款的风险控制和收益。目前商业银行大多都使用基于AI的信用评分模型来对客户进行打分。在这一过程中,特征筛选作为数据预处理的关键步骤,对于构建高效、准确的信用评分模型至关重要。然而,目前依赖于专家经验和传统模型的特征筛选方法存在主观性较强、计算成本高以及过拟合风险等问题。
本项目通过使用专用量子计算机求解QUBO模型来实现特征选择,相比传统特征筛选方法, 在不牺牲准确率的前提下, 效率更高而且人工干扰更少,为银行风控领域带来了新的技术突破。
1. 项目描述
信用评分是一种常用的金融风控策略, 通过建立一套评分模型,利用量化的方法评估借款人或客户的信用状况。银行根据最终的评分结果来决定是否进行贷款或划分不同的贷款额度和利率,以提升银行贷款业务收益,降低金融交易过程中的坏账风险。在信用评分的建模过程中, 特征筛选起着至关重要的作用,尤其针对当前金融行业客户特征数据复杂、高纬度、低价值纯度的特点,不同的特征选择将决定信用评分模型的整体效果,影响模型的准确率和泛化能力。
信用评分模型在银行业务中是一个普遍使用的产品,其准确度微小提升都能带来显著的业务价值。据测算,信用评分模型的准确度每提高1%,银行的坏账率可以降低约0.5%至1%。这意味着,对于一个拥有数十亿贷款组合的银行来说,即使是1%的准确度提升,也可能减少数千万甚至上亿的潜在损失。准确的信用评分模型不仅可以避免发放超过借款人实际偿债能力或需求的贷款,减少银行的坏帐率,同时也能够确保放贷额度合理,避免因授信不足对银行收益率的负面影响。
随着大数据时代的到来,客户数据维度呈指数型增长,传统的特征筛选方法依赖于专家经验, 不仅存在一定的主观性,而且面对巨大、复杂的特征空间,往往也需要大量的计算资源和时间,且很难保证选择出最优的特征集合。量子计算作为新质算力的代表,为解决这一难题提供了新的可能性。
专用量子计算机以光量子比特作为基本单位,模拟伊辛模型(伊辛模型在数学上等价于QUBO模型)的演化过程。专用于求解大规模组合优化类问题,已被证实可有效求解NP-hard问题,并且具有相比经典计算指数级的加速优势和更高的最优解求解概率。本项目通过量子计算解决QUBO模型来实现特征选择,相比传统信用评分的特征筛选方法, 在不牺牲准确率的前提下,效率更高而且人工干扰更少,为解决数据维度大时的特征筛选难题提供了新的求解思路。
2. 问题描述
问题:从给定的n个特征中,选择出表征能力更强且特征间相关度更低的m个特征,构建特征子集,用于训练信用评分模型。
目标:最小化特征之间的关系同时最大化单个特征的影响权重。
3. 建模过程
特征筛选的目标将是找到与向量
目标函数由两部分组成,第一个部分表示特征对标记的类的影响为:
第二个组成部分代表了独立性为:
4. 结果
本项目采用德国信用数据进行测试,其中包括20个特征(7个数字特征,13个分类特征)和1个二元分类特征(良好信用或不良信用)。在此基础上,本项目采用两种数据预处理的方式进行实验:
方式A:将分类特征进行one-hot编码,使得特征数增加为48个;
方式B:采用传统信用评分业务中的建模逻辑对原始数据进行WOE分箱处理,不改变原有的特征数。
以下的实验结果均是基于1000次洗牌和20%的测试份额的初始设置进行,并且根据K-S和ROC指标来判断算法的好坏。
实验A 用one-hot编码对原始数据处理后获得的实验结果:
| 超参数α | 训练集平均精度 | 测试集平均精度 | 平均精度 |
|---|---|---|---|
| 0.90 | 0.699 6 | 0.701 2 | 0.699 9 |
| 0.91 | 0.699 7 | 0.701 3 | 0.700 0 |
| 0.92 | 0.699 5 | 0.701 1 | 0.699 8 |
| 0.93 | 0.713 5 | 0.713 1 | 0.713 4 |
| 0.94 | 0.737 4 | 0.733 0 | 0.736 5 |
| 0.95 | 0.737 9 | 0.730 4 | 0.736 4 |
| 0.96 | 0.749 6 | 0.738 0 | 0.747 3 |
| 0.97 | 0.760 2 | 0.746 3 | 0.757 4 |
| 0.98 | 0.777 8 | 0.761 1 | 0.774 3 |
| 0.99 | 0.780 0 | 0.755 6 | 0.775 1 |
表1: 不同的超参数进行量子特征选择的结果
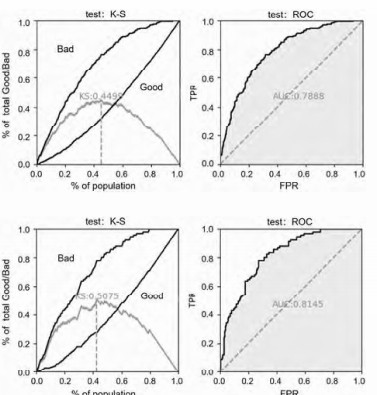
图1:
实验B 用WOE分箱策略预处理数据,获得的实验结果:
| 超参数α | 训练集平均精度 | 测试集平均精度 | 平均精度 |
|---|---|---|---|
| 0.7 | 0.699 7 | 0.701 3 | 0.700 0 |
| 0.8 | 0.727 4 | 0.722 8 | 0.726 5 |
| 0.9 | 0.761 5 | 0.756 7 | 0.760 5 |
| 1.0 | 0.773 5 | 0.760 8 | 0.771 0 |
表2: 不同的超参数进行量子特征选择的结果
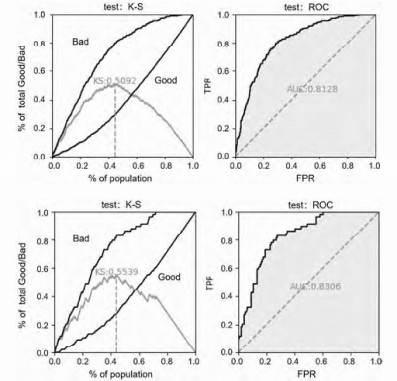
图2:
根据研究表明,在德国信用数据上使用传统的特征选择准确性得分通常在70%~75%之间, 标准差在5%左右。我们可以发现,通过量子计算方法筛选得到的特征与传统方法筛选的特征相比差别极小,在不降低准确率的情况下, 基于量子计算的特征选取策略减少了人为的参与, 提高效率并降低对业务人员的依赖, 从而减少操作风险。 而在K-S以及ROC这两个评价模型中, 量子计算策略明显优于传统筛选策略,证明了量子计算应用于特征筛选该类特定问题上的可行性, 尤其在特征数指数级增长的的情况下,量子计算的优势更为明显。
5. 场景延展
特征筛选指从原始数据集中识别和选择对模型最有影响的特征的过程,是一种数据预处理方法。有效的特征筛选方法有助于提高模型的可解释性以及减少过拟合风险,已被证明可以适用在各种数据挖掘和机器学习问题上,在多个领域有着广泛的应用。以下是一些具体的应用场景:
- AI大模型:量子特征筛选方法有助于加速人工智能大模型的训练过程,减少算力消耗,提高训练效率。
- 多因子选股:通过量子特征筛选,可以从大量可能的因子中识别出对股票收益预测最有效的因子,从而提高模型的预测准确性。同时有助于减少模型中因子的数量,降低模型的复杂度,避免过拟合。
- 产品推荐系统:电商平台和流媒体服务可以通过特征筛选从用户行为中提取关键特征,提高当前推荐系统的效果,为用户提供个性化的推荐。
- 医疗临床决策: 特征筛选结果可以集成到临床决策支持系统中,帮助医生在诊断和治疗过程中做出更加精准的决策。
论文链接:基于光量子计算的信用评分特征筛选研究报告