案例解析:银行云柜员调度优化问题
量子计算与运筹优化的结合是当前量子技术应用的重要方向,其核心是利用量子计算的并行性优势解决经典计算难以高效处理的复杂优化问题,两者结合的研究可以显著提升人工智能、物流、金融等行业的决策效率,是量子计算最具商业价值的应用方向之一。
本节将以银行云柜员调度优化问题为例,讲述量子+运筹优化的结合应用。
场景介绍
云柜台专门服务由自助设备渠道接入的客户,客户点击接入按键后,系统会将用户自动分配至空闲柜员并开启连线,如果全部柜员繁忙没有空闲窗口,客户会自动进入等待队列。 云柜系统每月初会对当月每日值班人数进行排班,值班人数依据每月的忙期闲期制定,排班会限定每天可用的柜员人数上限。此外,需要安排每日的时间表,每日8:30-17:30为工作时间,每半小时为一个班次,需要指定该班次人员。
这是一个经典的M/M/1模型问题,M/M/1模型问题是排队论中最简单的一种模型。排队是一个运筹学知识概念,它是指一个单一服务台,顾客到达服从泊松分布,服务时间服从指数分布的排队系统。其中,M表示到达率和服务率都是指数分布,1表示只有一个服务台。
在M/M/1模型中,顾客到达率λ和服务率μ是两个重要的参数。到达率λ表示单位时间内到达系统的顾客数的期望值,服从参数为λ的泊松分布;服务率μ表示单位时间内一个顾客被服务完成的期望值,服从参数为μ的指数分布。假设顾客到达和服务时间是独立的,且服务时间服从无记忆性的指数分布,则该模型的稳态分析可以得到以下几个重要的性质:
- 平均队长L:系统中平均等待服务的顾客数;
- 平均逗留时间W:顾客在系统中逗留的平均时间;
- 平均服务时间S:一个顾客接受服务的平均时间;
- 系统利用率ρ:服务台被占用的时间比例;
这些性质可以通过使用稳态分析方法来计算,其中最常用的方法是利用平衡方程法。通过计算这些性质,可以对M/M/1模型进行评估和优化,以提高系统的效率和服务质量。
M/M/1模型虽然简单,但是在实际应用中有着广泛的应用,如电话交换系统、计算机网络、银行窗口等。因此,掌握M/M/1模型的基本原理和分析方法对于学习排队论和实际应用都具有重要意义。
泊松分布是一种离散概率分布,它描述了在一段时间内某个事件发生的次数,如一小时内接到的电话数、一天内发生的交通事故数等。泊松分布的概率密度函数为:
其中,
泊松分布的特点是:在一定时间内,事件发生的次数是独立的,且事件发生的概率相等。泊松分布的期望值和方差都等于λ,即:
需要注意的是,泊松分布只适用于事件发生的概率很小、事件之间是独立的、事件发生的平均次数是已知的情况。如果事件发生的概率很大,或者事件之间不是独立的,或者事件发生的平均次数是未知的,则泊松分布就不适用了。
一、假设条件
- 云柜员没有工作效率高低之分;
- 云业务没有办理时间长短之分。
二、决策变量
- 每月1日决定该月各工作日的云柜员数量(不超过60);每个工作日为月初分配到当日的云柜员安排工作时间,从早上8点半到下午5点半每半小时一档。每天总共是18个半小时长的时间档。
- 第一阶段建模将每月1日决定该月各工作日的云柜员数量做为给定约束条件处理;第二阶段建模再考虑使用Benders decomposition进行每月1日和每个工作日两个层次的共同优化。
三、优化目标
- 最小化当日客户平均等待时间的最大值(每个时间档都统计客户平均等待时间);
- 最小化云柜员的工时。
四、约束条件
- 每位云柜员每个工作日的工作总时间最长为8小时(无须连续);
- 保证排队系统达到稳态,队伍长度不会持续增加,即云柜员数乘以云柜员服务率应大于客户到达率。
五、优化目标的数学定义
首先将问题描述成一个整数规划问题(IP),变量为某工作日21个时间档(8:30-19:00,每半小时一档)每个时间档分配的工时亦即云柜员数量。
注意:这里工时的定义跟一般工时的定义不一样。为了简化数学表达式,这里1个工时的定义是:1个工时=1位工人0.5小时。所以最小化总工时的优化目标可以表达为:
另外我们可以使用每月1日决定该月各工作日的云柜员数量来表达每位云柜员每个工作日的工作总时间最长为8小时(即16个半小时)的约束:
其中
注意:这里使用了云柜员没有工作效率高低之分的假设条件,同时忽略了每位云柜员具体的排班时间。因为在该假设条件下每位云柜员的工时是不可区分(indistinguishable)的,虽然每位云柜员的身份是独一无二(distinct)的。
假定我们已知客户平均等待时间与云柜员数量和时间档的映射关系:
其中
该问题有如下等价的线性规划表达式:
整合以上各个优化目标和约束条件,我们得到如下云柜员调度优化问题的整数规划问题表达式:
为了问题求解的便利,建议使用以下客户最大等待时间与云柜员数量和时间档的映射关系模板对客户最大等待时间进行统计概率分布拟合:
该模板的好处是分离了客户最大等待时间对云柜员数量的依赖关系和客户最大等待时间对时间档的依赖关系,同时对云柜员数量的依赖关系是线性的。这里我们使用了第二个假设条件——云业务没有办理时间长短之分:常数
同时建议客户最大等待时间对时间档的依赖关系
六、客户平均等待时间与云柜员数量的映射关系
通过观察客户到达速率的特征,发现客户流服从Poisson分布,柜员服务时间服从Erlang分布。通过观察业务处理模式,发现场景适用运筹学M/Er/R排队系统[1]。在本例中,
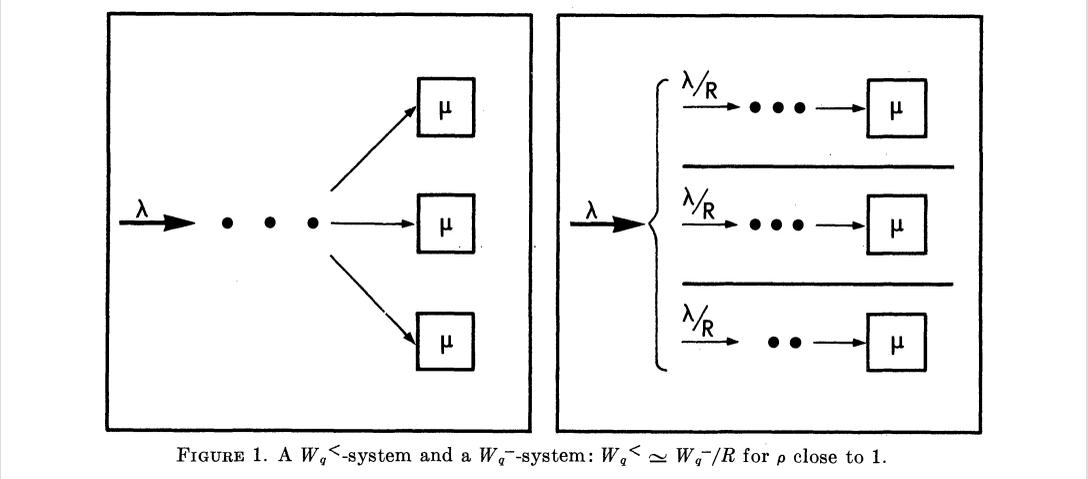
根据运筹学稳态公式可直接求得顾客的平均等待时间,M/Er/R模型中顾客平均等待时间
其中
通过查表可知,
以下根据M/Er/R排队理论做举例计算:假设8:30时间档的云柜员人数为15,客户到达平均间隔时间为4.78秒,客户到达时间服从exponential分布,那么客户到达率为:
假设云柜员全天服务时间均值约为25秒,方差150。用
所以Erlang分布的系数为:
假定该时间档整体服务率
将各参数带入以上客户平均等待时间公式计算可得:
需要指出的是,
- 本公式建立的客户平均等待时间与云柜员数量的映射关系过于复杂,涉及柜员数的阶乘,不容易降阶;
- 本公式的适用条件为
,即服务强度大于0.5的情况下对平均服务时间的预测结果较准确,但是经过统计发现存在服务强度小于 0.5 的时间档,导致预测结果不准确; - 另一方面,在文献里很多作者把M/Er/R当作M/G/R的一个特殊形式。
因此我们探索使用M/G/R排队理论来计算客户平均等待时间。该排队系统默认客户流服从Poisson分布,而服务率服从广义分布(general service-time distribution)。查阅 [2] 可知该系统稳态平均等待时间公式如下:
设定
对于给定的
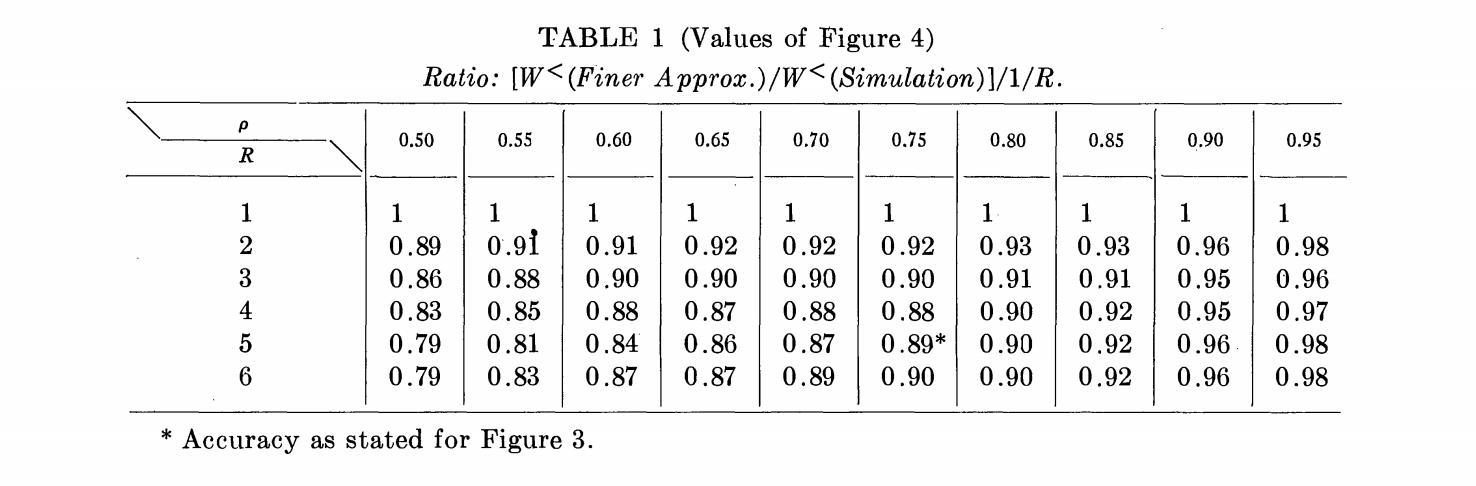
值,平均排队时间 的任意值都可以用相对百分比误差来近似: ,该误差根据涉及的参数值为正或负,且当 时趋于 0;对 的值不敏感,绝对值非常小,因此如果没有解析结果,很难被识别。
作为量级的一个示意,上方的表1给出了在过程( M/ / )且 , = 0.05, 0.10, 0.20, 0.50和1.00,中使用该公式评估平均排队时间时产生的相对百分比误差。 的任意值都可以用相对百分比误差来近似,该误差如最初预期的那样随 变化:当 趋近于0或1时,误差趋于0,并且在中间某个位置达到最大绝对值。
从实际应用角度看,如果近似评估
其中
注意到
七、数学建模
考虑到对M/G/R公式进行解析函数近似的难度。我们通过首先将
| n1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| t1 | 10000 | 10000 | 10000 | 10000 | 10000 | 432 | 135 | 55 | 24 | 10 | 4 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
请注意,表格中
为构建二元值变量从而将以上整数规划问题(IP)转化成二元值整数规划问题(BIP),我们定义
我们引入二元值变量
则以上优化目标可以表示成如下形式:
| 公式 | 说明 |
|---|---|
| 保证每个工作簿必选且只选一个值 | |
| 等价于以上的 | |
| 等价于以上的 | |
| 等价于以上的 | |
| 同上 | |
| 保证 |
这个模型忽略各时间档为保证排队系统达到稳态所需要的最少云柜员数量的约束条件。其理由是我们可以通过对未满足该约束条件所带来的客户平均等待时间的增长的赋值来作为惩罚,从而以软约束的方式去满足这个约束条件。
目前在上述表格中,未达到稳态的惩罚时间为10000,超过稳态平均等待时间两个数量级,依实际优化效果可以进一步提高这一数值以增强惩罚效果。
八、参考文献
[1] Erik Maaløe, Approximation Formulae for Estimation of Waiting-Time in Multiple-Channel Queueing System, Management Science, Vol. 19, No. 6, Application Series, pp.703-710 (1973)
[2] George P. Cosmetatos, Some Approximate Equilibrium Results for the Multi-Server Queue (M/G/r), Operational Research Quarterly, Vol. 27, No. 3, Part 1, pp. 615-620 (1976)