2.2 基于光量子计算的序列生成模型
随着数据生成需求的不断升级,图像、生物信息学序列、自然语言文本等复杂数据的生成任务对模型的效率、精度和资源消耗提出了更高要求。现有技术中,数据生成多依赖经典计算机构建的神经网络模型,其中,基于能量网络的模型(如玻尔兹曼机、受限玻尔兹曼机)因参数量小、可解释性强,在小样本数据生成场景中具备显著优势。
然而,基于能量网络的无条件约束数据生成模型存在一个核心技术瓶颈:模型的待采样变量采样问题属于NP-Hard问题,采用经典计算机进行采样(如Gibbs采样)时,存在计算复杂度高、采样效率低、样本偏差大等缺陷,导致模型训练收敛慢、生成数据质量差,难以适配大规模、高精度的数据生成需求。
序列生成模型的构建
本案例可广泛应用于能够转换为Ising模型的生成模型,包括但不限于玻尔兹曼机、受限玻尔兹曼机等经典生成模型。
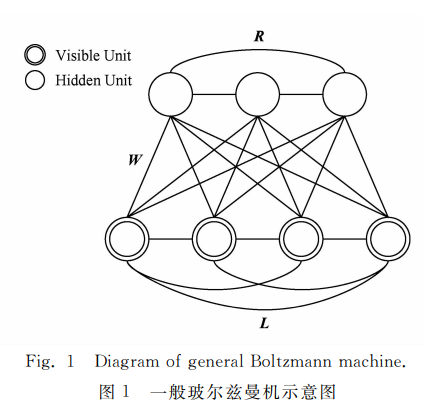
本例以玻尔兹曼机(BM)举例,其具有对称的连接权重,且每个单元与自己无连接,每个神经元有两种状态:
其中,
玻尔兹曼机的神经元通常分为可见节点和隐藏节点,可见节点表示可观察的数据,隐藏节点表示数据之间的高维特征。玻尔兹曼机的模型分布(全局概率分布)
其中,
考虑一组数据集
采样的实现
由于从给定玻尔兹曼机权重下采样数据为NP-Hard问题,可用多种采样方法进行近似采样,如Gibbs采样。
本案例将采样问题转化为伊辛矩阵的求解问题,并使用相干光量子计算机完成。具体来说,对于具有
转化后的伊辛模型的能量函数为:
其中
生成模型的训练
生成模型的参数优化采用基于梯度的技术来执行,梯度估计为:
其中
使用该方式,可得到
具体场景实现
本案例在5’端非翻译区(5’Untranslated Regions,以下简称5’UTR)序列的生成这一真实场景进行。
5’UTR从信使核糖核酸(message Ribonucleic Acid,以下简称mRNA)起点的甲基化鸟嘌呤核苷酸帽延伸至AUG起始密码子,其设计直接影响mRNA的翻译效率及稳定性。这就要求科学家们在设计新mRNA时,确保5’UTR的优化,以达到最佳表达状态。

使用
本案例使用9131条长度100及以内的5’UTR、使用one-hot编码(训练包含500个可见节点和100个隐藏节点的玻尔兹曼机(总参数量为180300,0.18M)。
新生成序列示例:
'TTGTCCGTCGCGAGGCGGCAGCAGGAACACAGTTTGCAAGAGTCGCGTGGAGCAAAAGCGGTGCTTTCTAGAAAAAAGCCAAAACGCCAGCGGAAATAAA',
'AAGTGCGCGGCTCGGGGGAGTCACGACAGTGCAGGGAAAGGTGAGCAGATGAGAGACAGGCGGGGCTGTGACGAGCCACTCCAGAGCCGTTGCATCTTTC',
'CAGTCGGAAGGTGCAGGGGCCTCTGAACCTGGTGTCCTCCCCGTCAGTAGGGGTCCCGGGCTCCCCTCGAGCAAGGTGCGAAAAATTCCACGCCAATACA',
'CTGTGCCGCTCGAGAGGGGGCGAGCAGCGGACTGTGCGCGGGTGGCGTAGGGGCAGAGCGGTGGTGTCTAGAAAAGTACGCAACACTCAGAAAAAGAAAC',
'CCCTCGGAGGGTCCTGAGCCCTAGCATCTCATTTACCGCCGAGTCAGTGTTGATCTCAGGGTGCCATCTTGTTAGGAACCAAAAATCCCGAGACTTAACC',
'GCCCCGCCCTTTCCTCCCCCCCAGCCCTTCACCCTCCGCCGGGCCTGTGGGCCTCCGCCGCGGCCCGCCTGCAGCGCCCGAGCCGGCCCCTCCGGGCACT',
'TTCTCCGCGGCTGCGCTGGCCCAGGACGGCGTTTTACTCTCTGCGGCTCCGCCGAGGACGGAGCTGTGTTCAGGAAAACCCAGAAGCCAGCTGAAATCGC',
'CAGTCCCCGGCTGAGGCGGACGAGGAAGGTCTTTTGTTCTGAGCCCTGCTTGCGTGAAAGGTCCTGTGCTCTGGAATAGTCAAACAACTGAAGCAAAAAA',
'CTGTCTGGGGAGCGGCCGCGCTGGGACCACGGTGGTCGCGGCGCCAGGCGTCCGAAAAAGATGAGCCGTAGAAGAAGGTCAAGATGCAAGCGAAAATAAA',
'CCCTCGCGCGGTTCTGACGCCCCGCAGCCCCTCGGCCCCCAAGCCCGTGGAGCTCTGGCAGTGCTTTCTTGGAACGCCCGAGACTTCCCCCGGTGACACC',
'GCCTCGGCCGCTGCCGCGGCCCAGGCACATGGATGCCCAGAGGCCCTGGCAGCGACAAAACCGAGTCCCTCACCAGTGCCAGAACCGCAGCTGCAACAAG',
'CCCTCGGAGGGTGCAGCGGCCTAGGAACTGCGTTTGCTCCGAGCCAGAGGTGGTCCAGCGGTGCGGTGAACCAAGTTGCTAAAAGCTCTGAGACAATACA',
'CTTTGGGAAGGTTGTGTGCCTTAACAACTCAATAATCGAGAAGTCAGTGTTGATCTAAGAGTCGCATCTTGCGAAGTGCCAGAAATCCAAAGGTATAACC',
'CCGTACGCCGGTGCCGCGAGCAAACACTGTGCTGTTGACAGCGGCCTTTTGACTTGCTCGTTCCTCTCTTCCGGACTGGTCAAAGTTCTGAAAGTTTGTA',
'CCGTCCCCGGCGGGGGCGGCCGCGGACCGGGCTTTGCGCCGGGGCCCACGTCCCTCGGCGGTGCTGTCTTCTCGACTCGCCAAAGCTCAGAAAAAATGAA',
'CCTTCCGGGGCGGGGGAGGCCGAGGACCGGGTTTGGAGTGGAGGCAGGAGCGGAAAAGAGGTGCGGTGTGCTCAAGTGCCCAAACCAAAGAAAAAGAACC'。
优势:
(1)参数量小、所需训练数据少:采用玻尔兹曼机/受限玻尔兹曼机作为无条件约束数据生成模型,相较于传统多层深度学习模型,参数量大幅减少,进而降低了模型训练所需的训练数据量,减少了数据采集和标注成本;
(2)可解释性强:模型基于能量函数建模,通过可见节点和隐藏节点的关联可清晰追溯生成结果的逻辑来源,解决了传统深度学习模型可解释性差的痛点,便于技术优化和问题排查;
(3)资源消耗低、训练效率高:通过量子-经典混合计算框架,将高复杂度的采样问题交由相干光量子计算机执行,突破了经典采样的NP-Hard复杂度瓶颈,无需消耗大量GPU资源,同时提升采样效率和训练效率,缩短模型训练周期;
(4)生成速度快、生成质量高:相干光量子计算机的高效采样能力,可实现快速靶向采样,推理阶段可快速生成无条件约束的全新样本;同时,通过训练阶段的迭代优化,模型全局概率分布可充分逼近真实数据分布,结合推理阶段的样本筛选逻辑,确保生成样本的合理性和高质量。
案例代码可参考:https://github.com/qboson/kaiwu-pytorch-plugin/tree/main/example/bm_generation